Clear Sky Science · tr
İnsan ve Yapay Zeka Değerlendirmesi Arasındaki Tedavi Planı Anlaşmazlığı
Günlük tıbbi bakım için neden önemli
Yapay zeka (YZ) araçları doktorlara tedavi seçmede yardımcı olmaya başladıkça temel bir soru ortaya çıkıyor: kimin yargısına daha çok güvenmeliyiz — insanlar mı yoksa makineler mi? Bu çalışma basit ama rahatsız edici bir olasılığı inceliyor: doktorlar ve YZ sistemleri yalnızca hangi tedavinin en iyi olduğunda uyuşmayabilir, aynı zamanda baştan “iyi” bir tedavi planının ne olduğuna dair ölçütlerde de ayrılabilir. Bu boşluğu anlamak, YZ’nin gerçek dünyadaki tıbbi kararları desteklemesini —ya da farkında olmadan çarpıtmasını önlemek istiyorsak— hayati önem taşıyor.
Tedavi önerilerinin karşılaştırmalı testi
Araştırmacılar, nadiren tek bir “doğru” cevabı olan uzun dönem cilt hastalıklarını yöneten dermatoloji alanına odaklandı. On deneyimli dermatolog ve iki büyük dil modeli (biri genel amaçlı, diğeri akıl yürütmeye odaklı) ağır egzama, ek hastalıklarla birlikte psoriasis ve gebelikle ilişkili akne gibi beş zorlu, uydurma vaka için tedavi planları yazmaları istendi. Adil olsun diye tüm 60 plan ortak bir biçime getirildi: benzer uzunluk, yapı ve üslup. Bir planın insan mı yoksa YZ tarafından yazıldığını belli eden bariz ipuçları kaldırıldı, böylece sonraki hakemler içeriği değerlendirip üsluba değil içeriğe puan verecekti.
İnsanlar ve YZ nasıl puanladı
Planlar daha sonra aynı rubrikle iki tur kör puanlamadan geçirildi. Önce aynı on dermatolog grubu, her planı 0 ile 10 arasında genel kalite bakımından; etkinlik, güvenlik, uygulanabilirlik ve hasta odaklılık göz önünde bulundurarak değerlendirdi. İkinci olarak, yalnızca hakem olarak kullanılan ayrı bir YZ modeli aynı talimatlarla tam olarak aynı planları puanladı. Kritik olarak, ne insan değerlendiriciler ne de YZ hakem herhangi bir planın kim tarafından yazıldığını bilmiyordu. Bu düzenek, yazarların izole edebildiği tek bir faktöre izin verdi: değerlendiricinin insan mı yoksa YZ mi olduğu.
İnsanlar insanı, YZ YZ’yi destekliyor
Sonuçlar belirgin bir “değerlendirici etkisi” gösterdi. İnsanlar planları puanlarken, meslektaşları dermatologlar tarafından yazılmış planlara YZ’lerin yazdıklarına kıyasla daha yüksek puan verdiler. İnsan kaynaklı planların ortalama puanı biraz daha yüksekti ve sıralamada ilk beşi insan planları işgal etti. İleri düzey akıl yürütme sistemi olan bir YZ modeli en alt sıralara yakın yer aldı. Ancak YZ hakem devreye girince tablo tersine döndü. Bu kez, YZ tarafından yazılmış iki plan sıralamanın başına yükseldi ve her insan dermatoloğun planı bunların altında kaldı. Ortalama olarak YZ hakem aynı standartlaştırılmış metni okumasına rağmen YZ tarafından üretilen planlara insan üretimi planlardan daha yüksek puan verdi.
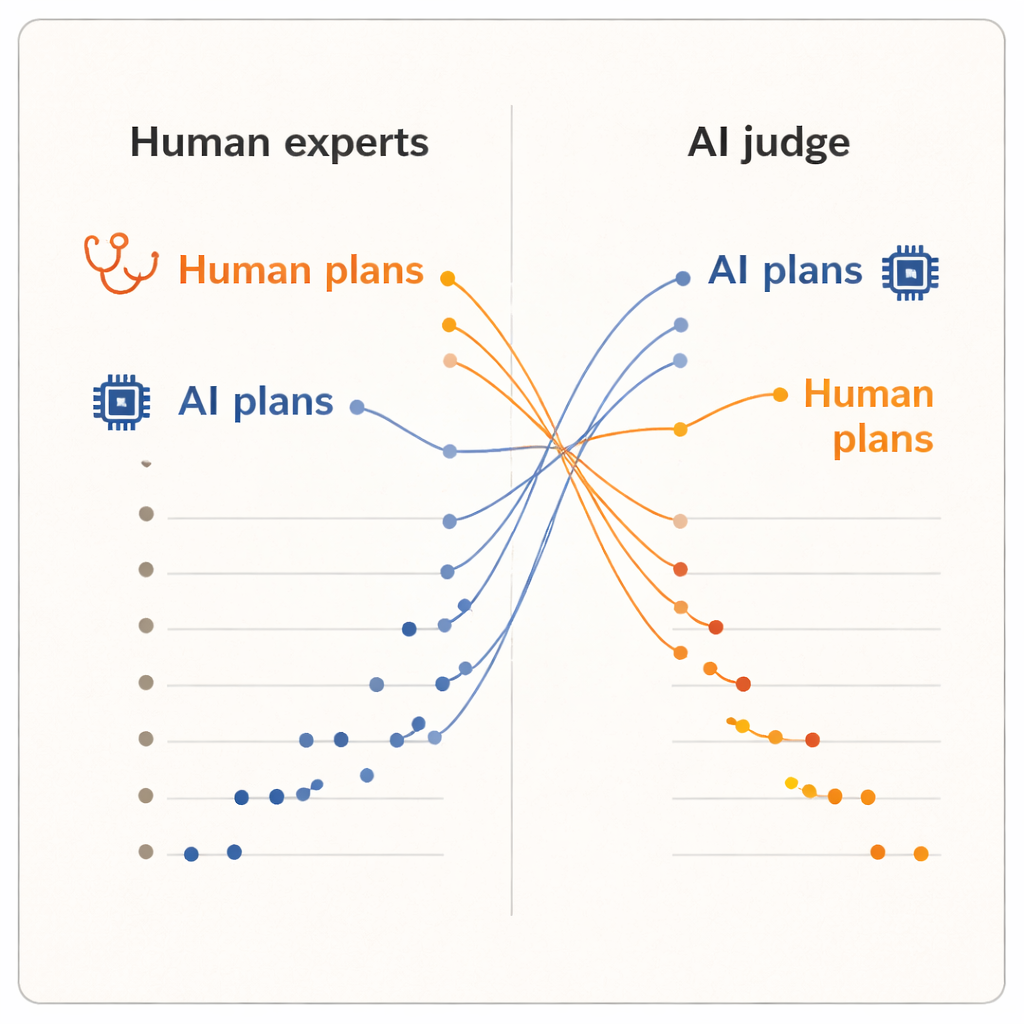
"İyi" bir plan hakkında farklı fikirler
Planlar sözdizimi açısından normalize edildiği ve hakemler kaynağa karşı kör tutulduğu için yazarlar bu ayrışmanın yüzeysel cilalama ile açıklanamayacağını savunuyor. Bunun yerine, insanların ve YZ sistemlerinin farklı iç ölçüleri masaya getirdiğini öne sürüyorlar. Klinikler muhtemelen gerçek dünya deneyimine yaslanır: kliniğe uygunluk, hastaların tepkileri ve hangi ödünlerin pratikte kabul edilebilir hissettirdiği gibi. Öte yandan, geniş metin koleksiyonları üzerinde eğitilmiş bir YZ hakem tıbbi literatürde veya kılavuzlarda sık görülen desenleri takip eden planları tercih edebilir; bu desenler yerel kısıtları veya hasta tercihlerini tam olarak yansıtmayabilir. Çalışma küçük ölçekli—sadece on klinisyen, beş vaka ve tek bir YZ hakem—ve algılanan kaliteyi ölçüyor, gerçek hasta sonuçlarını değil. Yine de, bu tersinin dikkat çekiciliği klinik YZ’yi nasıl değerlendirdiğimiz konusunda daha derin sorular doğuruyor.
Klinik YZ’yi test etme ve kullanma biçimimizi yeniden düşünmek
Bu bulgulardan yazarlar iki geniş ders çıkarıyor. Birincisi, tıbbi YZ için geleneksel “doğru cevap” testleri, gerçek bakımda önemli olan birçok unsuru kaçırıyor; çünkü planlar etkinlik, güvenlik, maliyet, lojistik ve hasta isteklerini aynı anda dengelemek zorunda. Yazarlar, bu boyutları açıkça puanlayan, birden çok insan ve YZ hakemi kullanan ve anlaşmazlıkların nerede ve neden ortaya çıktığını tek bir skora indirgemek yerine analiz eden daha zengin, çok ölçütlü değerlendirme çerçevelerini savunuyorlar. İkincisi, insan ve YZ yargıları arasındaki farklılıkların yalnızca bir hata değil, bir özellik olabileceğini öne sürüyorlar. Dikkatli kullanılırsa, YZ tarafından üretilen planlar doktorları varsayımlarını yeniden gözden geçirmeye teşvik eden düşünceli bir ikinci görüş işlevi görebilir; doktorlar ise YZ’nin eksik olduğu gerçek dünya bağlamını ve etik değerlendirmeyi sağlar. Varsayımları açıklayan, klinisyenlerin öncelikleri ayarlamasına ve eleştirel incelemeye izin veren güvenilir, şeffaf arayüzler geliştirmek, insan ve YZ perspektifleri arasındaki bu gerilimi daha güvenli, dengeli karar vermeye dönüştürmeye yardımcı olabilir.
Atıf: Sengupta, D., Panda, S. Disagreement between human and AI evaluation of treatment plans. Sci Rep 16, 4798 (2026). https://doi.org/10.1038/s41598-026-35406-8
Anahtar kelimeler: klinik karar desteği, tıpta yapay zeka, insan-yapay zeka işbirliği, tedavi planlaması, değerlendirme önyargısı