Clear Sky Science · tr
EMD ayrıştırmasıyla yüksek ve düşük frekanslı IMF’lere dayanan PM2.5 konsantrasyonu için hibrit bir tahmin modeli
Daha temiz hava tahminlerinin günlük yaşam için önemi
Havadaki ince parçacıklar, PM2.5 olarak bilinen partiküller, akciğerlerimizin derinliklerine kadar inebilecek ve hatta kana karışabilecek kadar küçüktür. Ağır sanayi ve kışın ısınma faaliyetlerinin yoğun olduğu Kuzey Çin’de bu parçacıklar sıklıkla sağlık uyarılarını tetikleyecek, ulaşımı aksatacak ve hatta fabrika ve okulların kapanmasına yol açacak düzeylere ulaşır. Bu çalışma çok pratik bir soruyu gündeme getiriyor: havanın tehlikeli hale gelmesinden önce şehirlerin ve sakinlerin daha erken ve daha güvenilir uyarılar alabilmesi için saat saat PM2.5 düzeylerini daha doğru tahmin edebilir miyiz?
Kuzey Çin’in kirli havasına daha yakından bakış
Araştırmacılar Kuzey Çin’deki altı büyük kente odaklandı: Pekin, Tianjin, Shijiazhuang, Taiyuan, Jinan ve Zhengzhou. Bu şehirler, kirliliğin özellikle kışın sık görüldüğü yoğun nüfuslu ve sanayileşmiş bölgeleri temsil ediyor. Resmi izleme verilerini kullanarak ekip, 2021 yılı boyunca her şehir için saatlik PM2.5 ölçümlerini topladı ve her şehirde 8.760 veri noktası elde etti. Kirlilik düzeylerinin şehirler arasında büyük farklılıklar gösterdiği tespit edildi; örneğin Taiyuan ortalama PM2.5 bakımından en yüksekken, Pekin en düşük ortalamaya sahipti. Aşırı olaylar çarpıcıydı: Taiyuan’da Mart ayında yaşanan toz ve kirlilik olayında konsantrasyonlar 652 mikrogram/metreküpe kadar tırmandı ve hava kalitesi endeksini en yüksek düzeye çıkararak ciddi kirliliğin açık bir göstergesi oldu.
PM2.5 tahminini zorlayan nedir
PM2.5 düzeyleri aynı anda birçok etken tarafından itilir ve çekilir—trafik ve fabrikalardan kaynaklanan yerel emisyonlar, bölgesel toz ve duman taşınımı, rüzgâr hızı, nem ve daha fazlası. Sonuç olarak, kirlilik kaydı düzgün bir eğri yerine keskin, huzursuz bir nabız gibi davranır. Geleneksel istatistiksel araçlar veya modern sinir ağları bu tür verilerle zorlanabilir: genel eğilimi yakalayabilirler ama ani sıçramaları kaçırabilir veya bir şehirde iyi çalışıp başka bir şehirde başarısız olabilirler. Önceki çalışmalar, tahminleri ya daha fazla fiziksel ayrıntı ekleyerek (örneğin kimyasal taşınım modelleri) ya da yalnızca sofistike makine öğrenimi yöntemlerine dayanarak iyileştirmeye çalıştı. Bu makale ise verideki farklı “ritimleri” ele almak üzere her biri farklı bir amaca uygun birkaç yöntemi bir araya getirir.
Sinyali hızlı ve yavaş ritimlere ayırmak
Ana adım, özgün modu ayrıştırma (empirical mode decomposition) olarak adlandırılan bir tekniktir; bu teknik orijinal PM2.5 zaman serisini daha basit birkaç bileşene böler. Bu bileşenlerden bazıları hızla dalgalanır ve kısa vadeli sıçramaları ve gürültüyü yakalar; diğerleri ise yavaş değişir ve altında yatan eğilimi yansıtır. Yazarlar ilk beş bileşeni “yüksek frekanslı” parçalar olarak, kalanları ve bir artık eğilimini ise “düşük frekanslı” parçalar olarak gruplaştırır. Daha düzensiz ve güçlü biçimde doğrusal olmayan yüksek frekanslı parçalar, zamana bağlı desenleri öğrenmeye uygun bir derin öğrenme türü olan uzun kısa vadeli hafıza (LSTM) ağına verilir. Daha düzgün, düşük frekanslı bileşenler ise verinin daha düzenli, yakın doğrusal davrandığı durumlarda etkili olan klasik bir zaman serisi yöntemi olan ARIMA’ya yönlendirilir.
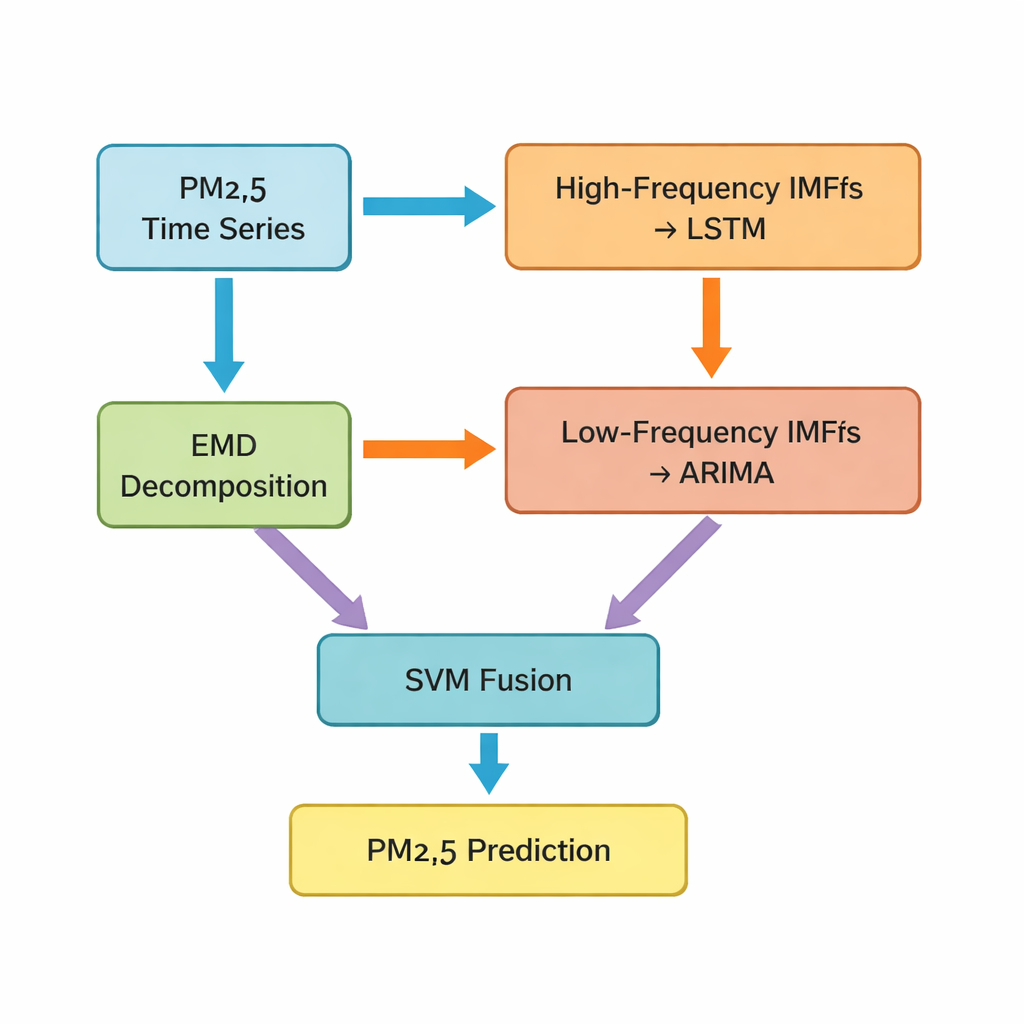
Farklı modelleri tek bir daha akıllı tahminde harmanlamak
LSTM ve ARIMA modelleri kendi kısmi tahminlerini ürettikten sonra çalışma hâlâ bir zorlukla karşılaşır: bu ayrı tahminleri bir sonraki saat için tek bir nihai, en iyi tahmin PM2.5 değerinde nasıl birleştirilecek? Bunun için yazarlar, iki girdi arasındaki ağırlıkları ve kombinasyonu öğrenen başka bir makine öğrenimi yöntemi olan destek vektör makinelerini (SVM) kullanır. Özü itibarıyla SVM bir hakem gibi davranır; “hızlı” bakışın (yüksek frekanslı desenlerin) ne zaman daha önemli olduğuna ve “yavaş” bakışın (uzun vadeli eğilimlerin) ne zaman baskın olması gerektiğine karar verir. Yazarların Hybrid‑EMDHL adını verdikleri birleşik sistem daha sonra ortalama hata, tahminlerin gözlenen değerlerle ne kadar yakından eşleştiği ve modelin değişim yönünü—yükselme mi yoksa düşme mi—ne kadar doğru yakaladığı gibi birkaç performans göstergesi kullanılarak değerlendirilir.
Daha net uyarılar ve daha iyi planlama
Hibrit model, ana bileşenlerinin hiçbirinin tek başına elde edemediği performansı altı şehrin tamamında gösterir. Sadece ortalama ve kare hataları azaltmakla kalmaz, aynı zamanda bir sonraki saatte PM2.5’in yükselip düşeceğini doğru biçimde tahmin etme yeteneğini önemli ölçüde iyileştirir—bu, zamanında sağlık uyarıları vermek için kritik bir özelliktir. Birçok durumda hibrit yaklaşım, tek bir sinir ağı modeline kıyasla hata ölçülerini yarıdan fazla azaltır ve “yön doğruluğu” 0,69’un üzerine çıkar; bu da test vakalarının üçte ikisinden fazlasında eğilimi doğru tahmin ettiği anlamına gelir. Bir okuyucu için bu, hem daha keskin hem de daha güvenilir hava kalitesi tahminleri demektir. Şehir planlamacıları ve sağlık otoriteleri içinse, kirlilik olayı zirve yapmadan önce hedefe yönelik erken müdahaleleri—örn. sanayi operasyonlarını veya trafik kontrollerini ayarlama—destekleyen pratik bir araç sunar; bu da maruziyeti azaltmaya ve Çin’in en kirli kentsel bölgelerindeki günlük yaşamı korumaya yardımcı olur.
Atıf: Wang, P., Wu, Q. & Zhang, G. A hybrid prediction model for PM2.5 concentration based on high-frequency and low-frequency IMFs with EMD decomposition. Sci Rep 16, 4969 (2026). https://doi.org/10.1038/s41598-026-35386-9
Anahtar kelimeler: PM2.5 tahmini, hava kirliliği, Kuzey Çin, makine öğrenimi, zaman serisi ayrıştırması