Clear Sky Science · tr
QPSODRL: kablosuz sensör ağları için iyileştirilmiş bir kuantum parçacık sürü optimizasyonu ve derin pekiştirmeli öğrenme tabanlı akıllı kümeleme ve yönlendirme protokolü
Bağlı Bir Dünya için Daha Akıllı Sensör Ağları
Hassas tarımdan afet erken uyarı sistemlerine kadar, kablosuz sensör ağları geniş alanlara yayılmış yüzlerce veya binlerce küçük cihazdan sessizce veri toplar. En büyük zayıflıkları aynı zamanda ayırt edici özellikleridir: her sensör küçük bir batarya ile çalışır ve bunların değiştirilmesi zor veya imkansızdır. Bu makale, batarya ömrünü uzatmak, bilgilerin daha güvenilir iletilmesini sağlamak ve ağ koşullar değiştiğinde ağın uyum göstermesini sağlamak için bu ağlarda verinin nasıl organize edilip yönlendirileceğine dair yeni bir yaklaşım sunar.
Neden Küçük Cihazlar Büyük Zekâya İhtiyaç Duyar
Bir kablosuz sensör ağında her düğüm algılama, hesaplama ve iletişim yapabilir, ancak enerji kıymetlidir. Bazı düğümler çok fazla iş yaparsa erken ölür ve veri toplanamayan “ölü bölgeler” ortaya çıkar. Bunu önlemek için tasarımcılar genellikle düğümleri kümelere ayırır. Her küme içinde bir düğüm küme başı olur: komşularından okumaları toplar ve bunları merkezi bir istasyona iletir. Hangi düğümlerin küme başı olacağı ve verilerin ağ üzerinde nasıl atlayarak iletileceği, piller azaldıkça değişen karmaşık bir bulmacadır. Geleneksel kural‑tabanlı veya tek algoritmalı çözümler genellikle fazla çabuk yerel olarak optimal olmayan modellere saplanır veya ağın şekli ve enerji seviyeleri zaman içinde değiştiğinde başarısız olur.
Kuantum Esinli Sürülerle Öğrenen Makinelerin Harmanı
Bu çalışma, kümelenmeyi gerçekleştiren kuantum esinli bir sürü yöntemi ile yönlendirme için kullanılan derin pekiştirmeli öğrenme motorunu birleştiren QPSODRL adlı bir protokol tanıtıyor. İlk aşamada sanal “parçacıklar” farklı küme başı ve üye atama yollarını keşfeder. Davranışları, ağ genelinde enerjinin ne kadar eşit dağıldığını gösteren bir ölçüt olan entropi ile yönlendirilir. Enerji kullanımı dengesiz olduğunda algoritma yeni küme düzenlerinin geniş çapta keşfedilmesini teşvik eder; durum stabil görünüyorsa umut vadeden düzenleri ince ayarlar. Özel bir “seçkin bozma” adımı zaman zaman en iyi adayları yeni yönlere doğru iterek aramanın yerel tuzaklardan kaçmasına ve aynı yüksek enerjili düğümlerin aşırı kullanılmasının önlenmesine yardımcı olur. 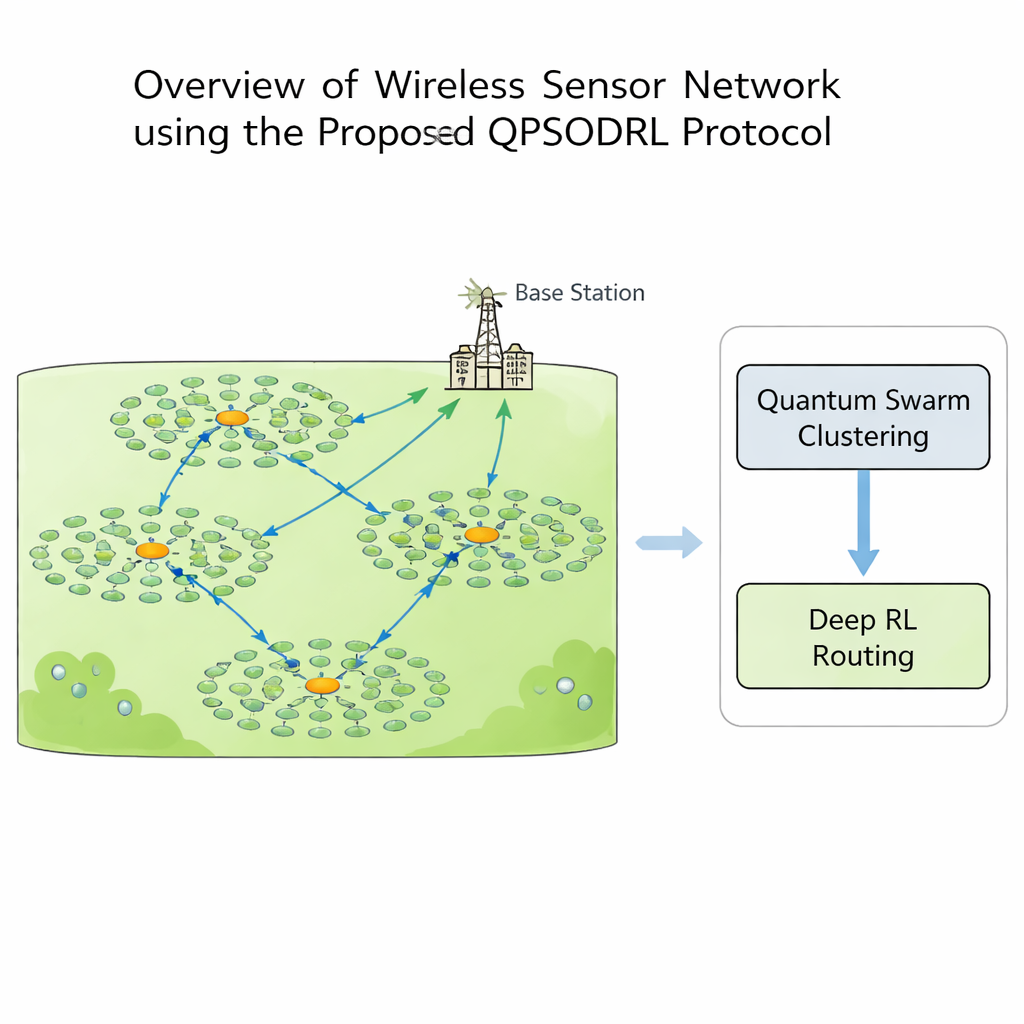
Ağa Daha İyi Yollar Öğretmek
Kümeler oluşturulduktan sonra ikinci aşama her küme başının verilerini istasyona nasıl göndereceğine karar verir. Sabit rotaları takip etmek yerine QPSODRL her küme başını öğrenme sürecinde bir ajan olarak ele alır. Her adımda ajan kendi kalan enerjisini, komşu başların enerji ve mesafe bilgilerini ve tahmini gecikmeleri gözlemler, ardından bir sonraki atlamayı seçer. Dueling Double Deep Q‑Network adındaki özel bir derin Q‑öğrenme türü her seçimin uzun vadede ne kadar iyi olduğunu tahmin eder. Yazarlar, sistemin çok çabuk aşırı emin hale gelmesini engellemek ve alternatif yolları keşfetmeye devam ettirmek için bir “entropi” terimi ekler. Ayrıca deneyim tekrar mekanizmasını, enerji düşük olduğunda veya gecikmeler arttığında olduğu gibi en bilgilendirici durumlara kasıtlı olarak odaklanacak şekilde geliştirirler; böylece model önemli senaryolarda daha hızlı öğrenir. 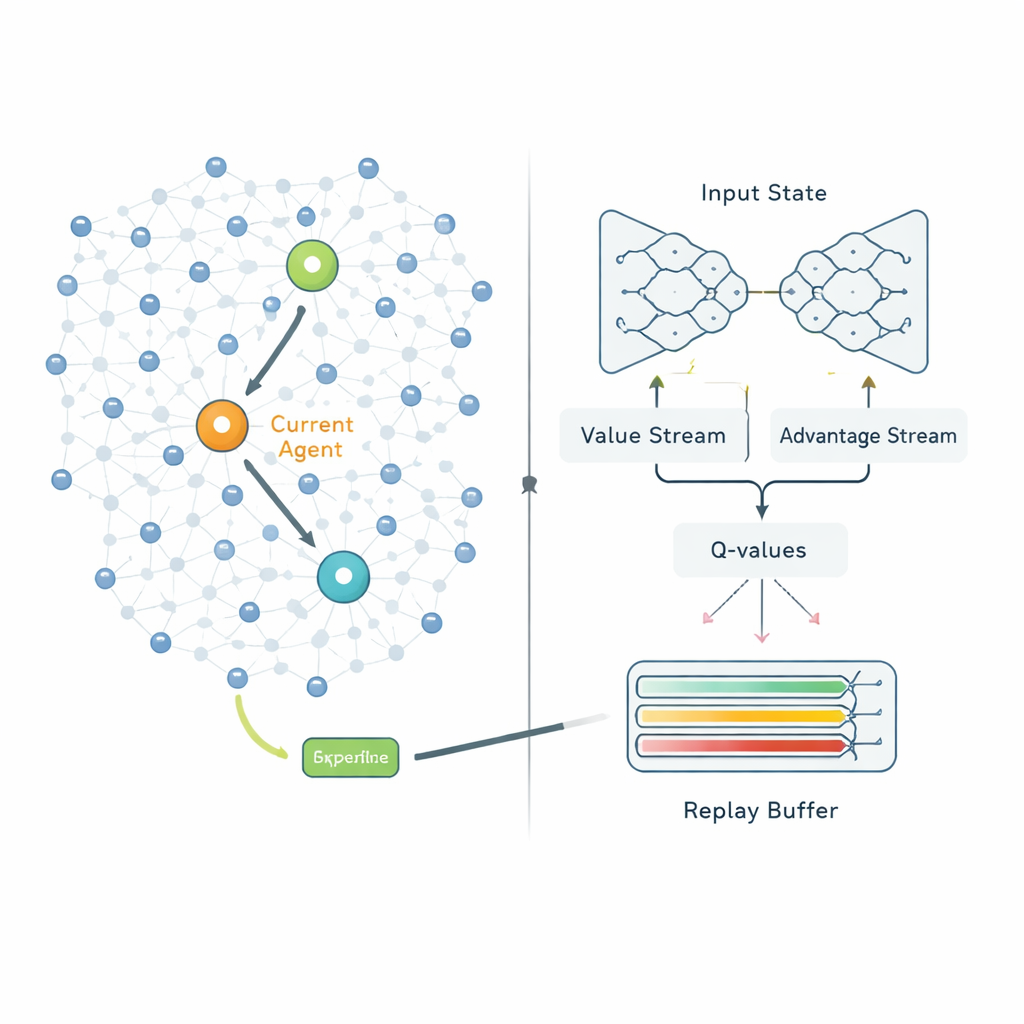
Yaklaşımı Sınamak
QPSODRL’in performansını görmek için yazar, farklı boyutlardaki alanlara yayılmış 100 ve 200 düğümlü ağların ayrıntılı bilgisayar simülasyonlarını çalıştırır ve farklı oranlarda küme başı görevini üstlenen düğümler içeren senaryoları dener. Yeni protokol, parçacık sürüleri, balina optimizasyonu, bulanık mantık veya diğer hibrit ve öğrenme‑tabanlı şemaları kullanan dört güncel ileri rakip ile karşılaştırılır. Test edilen tüm düzenlerde QPSODRL, iletişim turlarında ağın daha uzun süre canlı kalmasını sağlar, daha fazla veri paketini istasyona ulaştırır ve toplamda daha az enerji tüketir. Ayrıca her bir başın işlediği trafik miktarındaki varyasyonun daha düşük olmasına bağlı olarak yükü küme başları arasında daha eşit dağıtır. Bu kazanımlar, bazı düğümlerin daha uzun atlamalar yapmasını gerektiren alan kenarına yerleştirilmiş istasyon gibi daha zorlu düzenlerde özellikle belirgindir.
Gerçek Dünya Sistemleri İçin Ne Anlama Geliyor
Uzman olmayanlar için ana mesaj şudur: sensör ağlarının hem yapısını küresel olarak optimize etme hem de yerelde deneyimden öğrenme yeteneğine sahip olması, onların hizmet ömrünü önemli ölçüde uzatabilir. QPSODRL’in kuantum esinli kümelenmesi enerji kullanımını dengede tutarken, derin öğrenme tabanlı yönlendirmesi değişen koşullara insan müdahalesi gerektirmeden uyum sağlar. Sonuçlar sabit, hareket etmeyen düğümlerle yapılan simülasyonlara dayansa da, benzer akıllı kontrol stratejilerini benimseyen gelecek sensör dağıtımlarının—akıllı şehirlerden çevresel gözlem istasyonlarına kadar—daha uzun süre çalışabileceğini, daha az arıza yaşayabileceğini ve sınırlı pil gücünden daha iyi faydalanabileceğini göstermektedir.
Atıf: Guangjie, L. QPSODRL: an improved quantum particle swarm optimization and deep reinforcement learning based intelligent clustering and routing protocol for wireless sensor networks. Sci Rep 16, 5526 (2026). https://doi.org/10.1038/s41598-026-35365-0
Anahtar kelimeler: kablosuz sensör ağları, enerji verimli yönlendirme, derin pekiştirmeli öğrenme, sürü optimizasyonu, ağ kümeleme