Clear Sky Science · tr
Önceden eğitilmiş büyük dil modellerini kullanarak fizik bilgili sembolik regresyon için bilgi bütünleştirme
Bilgisayarlara Doğanın Formüllerini Tahmin Etmeyi Öğretmek
Bilimdek birçok büyük fikir, bir topun nasıl düştüğünden ışık dalgalarının uzayda nasıl yayıldığına kadar, düzgün küçük denklemlerle ifade edilir. Bu makale, bilgisayarların ham verilerden bu tür denklemleri otomatik olarak yeniden keşfetmesine yardımcı olacak yeni bir yolu inceliyor: tahminlerinin yalnızca doğru değil, aynı zamanda fiziksel açıdan anlamlı olmasını sağlamak için modern sohbet botlarını besleyenle aynı türden bir büyük dil modeline danışmalarına izin vermek.
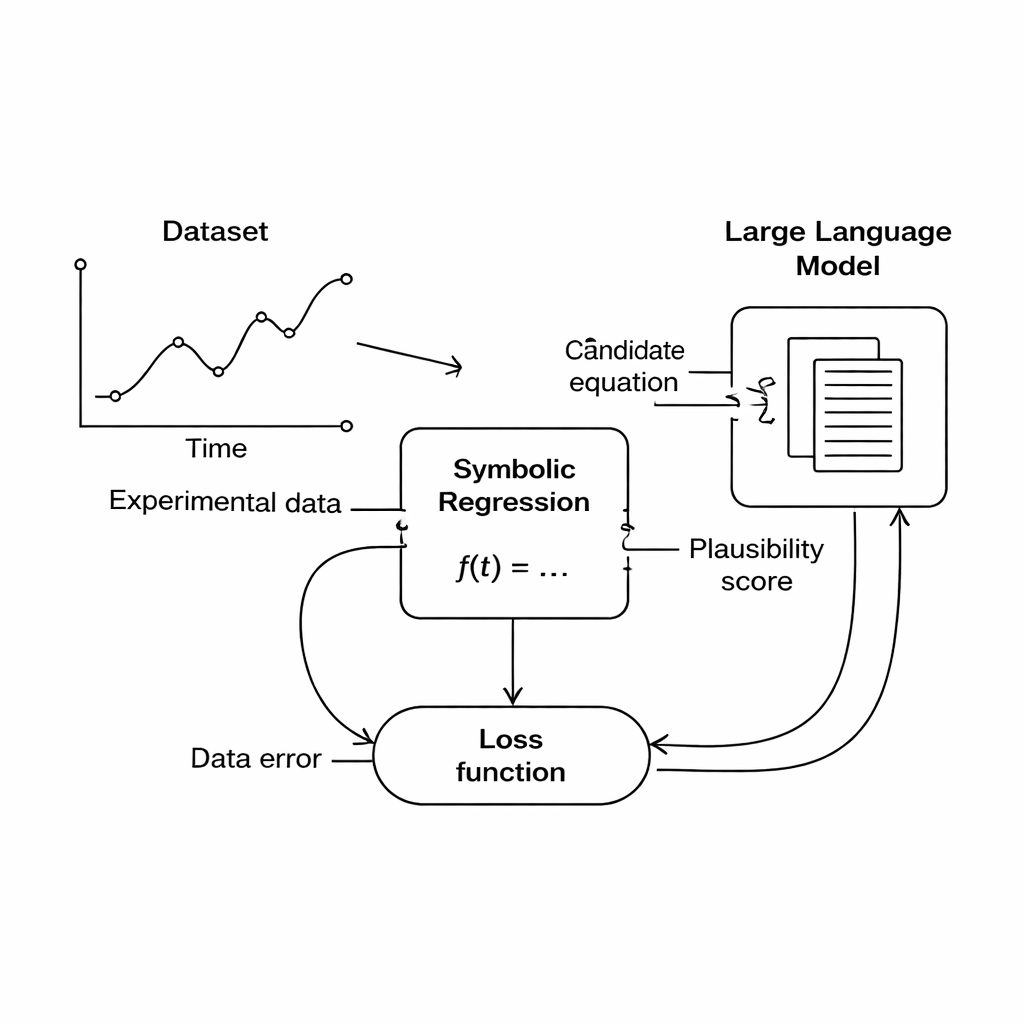
Ham Veriden İnsan Okuyabileceği Kanunlara
Yazarlar, ölçülen girişler ile çıkışlar arasındaki matematiksel formülü arayan bir teknik olan sembolik regresyona odaklanıyor. Sıradan eğri uydurmadan farklı olarak, sembolik regresyon sabit bir formül biçimiyle başlamaz; bunun yerine veriyle iyi örtüşen bir aday denklem bulana kadar denklem adaylarını oluşturur ve evrimleştirir. Bu, daha önce hiç yazılmamış yeni ilişkileri ortaya çıkarma potansiyeli olduğu için bilimsel keşif için umut verici bir araçtır. Ancak bir sorun vardır: veriye mükemmel uyan bir formül, örneğin bir mesafeyi bir zamana eklemek veya gerçek bir büyüklükle uyuşmayan birimler üretmek gibi fizik açısından saçma olabilir.
Fiziksel Sezgi Neden Hâlâ Önemli
Böyle saçmalıkları önlemek için araştırmacılar, aramaya doğanın bilinen kurallarını yerleştiren "fizik bilgili" sembolik regresyon sürümleri geliştirdiler. Bu yöntemler, örneğin enerjinin korunması veya boyutsal tutarlılık gibi kurallara uyan denklemleri ödüllendirir. Ancak bu bilginin kodlanması genellikle uzmanların her yeni problem için kısıtlar ve özel kayıp fonksiyonları elle tasarlamasını gerektirdi. Bu da yaklaşımı güçlü ama genelleştirmesi zor hale getiriyor. Her yeni fiziksel sistem kendi dikkatli tasarım çalışmasını gerektirebilir ve bu da bu araçların uzman olmayanlar için erişilebilirliğini sınırlıyor.
Denklemleri Dil Modellerine Yürütmek
Bu çalışma başka bir yol öneriyor: alan kurallarını sert kodlamak yerine, bilimsel olasığı esnekçe yargılayabilecek bir büyük dil modelini (LLM) kullanmak. Arama sırasında sembolik regresyon motoru veriye belirli bir dereceye kadar uyan aday denklemler üretir. Her denklem daha sonra metne çevrilir ve dahil olan büyüklükleri ve bilinen fiziksel kısıtları kısa bir istem ile birlikte LLM'ye gönderilir. LLM üç açı için puanlar döndürür: denklemin birimleri mantıklı mı, ne kadar basit olduğu ve fiziksel olarak gerçekçi görünüp görünmediği. Bu puanlar ana amaç fonksiyonuna katılır, böylece bilgisayar artık hangi denklemlerin geliştirilip tutulacağına karar verirken "veriye uyan" ile "iyi fizik gibi görünen" arasında denge kurar.
Yöntemi Test Etmek
Bunun ne kadar iyi çalıştığını görmek için yazarlar üç klasik problem üzerinde kapsamlı bilgisayar deneyleri yürüttüler: Dünya çekiminde bir topun serbest düşüşü, bir yaya bağlı kütlenin basit harmonik hareketi ve sönümlü bir elektromanyetik dalga. Her sistem için binlerce gürültülü ölçüm çeşitli koşullar altında simüle edildi ve üç popüler sembolik regresyon programından, LLM yardımıyla veya onsuz temel denklemleri geri çıkarmaları istendi. Mistral, Llama 2 ve Falcon olmak üzere üç kompakt, açık kaynak dil modeli denendi ve minimal bağlamdan tam açıklamalara ve hatta gerçek formülün verildiği durumlara kadar farklı istem tasarımlarının LLM rehberliğini nasıl etkilediği incelendi. Çoğu ayarda, LLM puanının eklenmesi geri kazanılan denklemlerin bilinen kanunlarla daha yakın eşleşmesini sağladı ve gürültüye karşı daha dayanıklı hale getirdi; genel olarak PySR (bir sembolik regresyon kütüphanesi) ile Mistral kombinasyonu en iyi performansı gösterdi.
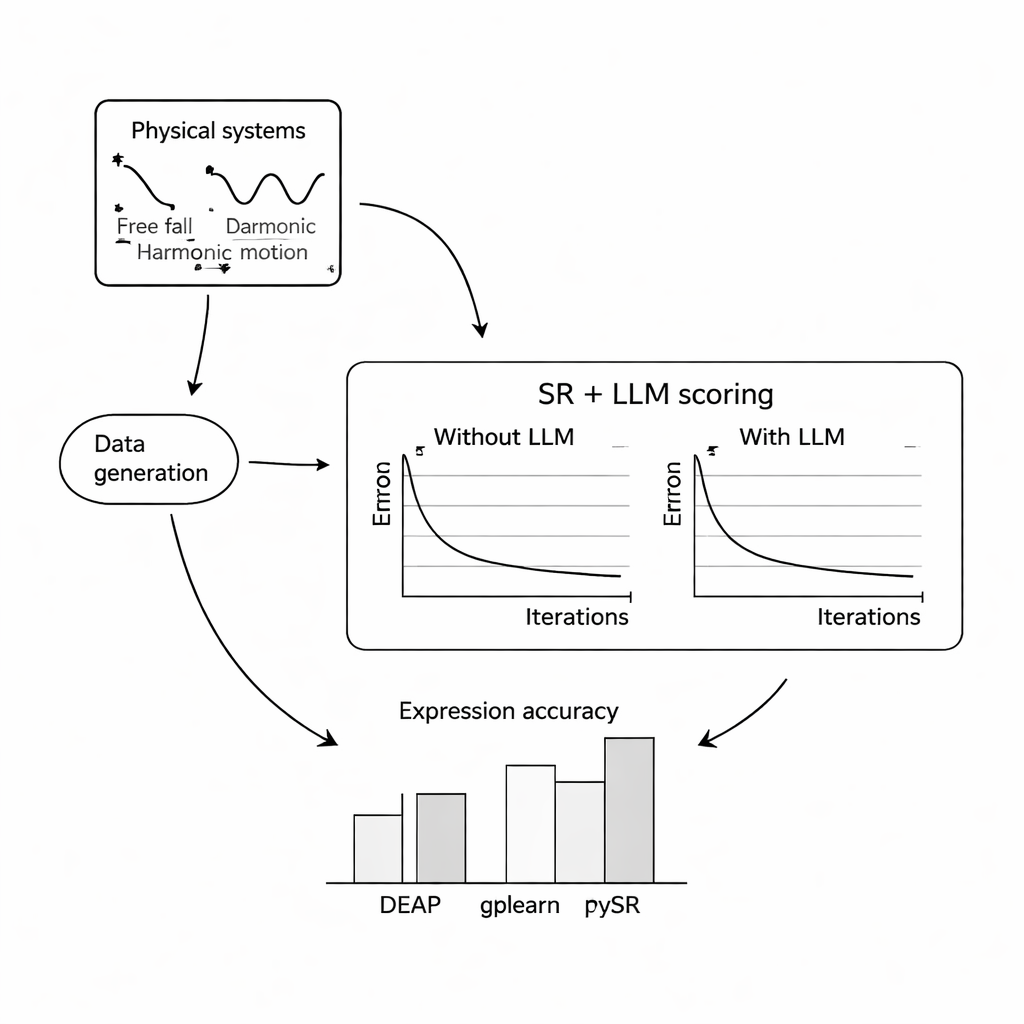
Sözcükler Matematiği Yönlendirdiğinde
Ana bulgulardan biri, istemin sözcüklerinin sonuçları güçlü biçimde etkilediği. İstemler değişkenlerin açık tanımlarını, deneyin doğasını ve bazen hedef formülün tam halini içerdiğinde, LLM yönlendirmeli arama doğru yapıya daha güvenilir şekilde dönüştü. Bu daha zengin durumlarda keşfedilen denklemler genellikle yalnızca sayısal olarak yakın olmakla kalmayıp, yapısal olarak da gerçek kanunlarla özdeşti. Yazarlar ayrıca yaklaşımın artan rastgele ölçüm gürültüsü seviyelerine karşı nasıl dayandığını test ettiler. Veriler daha gürültülü hale geldikçe ve alttaki denklemler daha karmaşık oldukça tüm yöntemler bozulsa da, LLM destekli sürümler standart muadillerine göre genellikle doğruluğu daha yavaş kaybetti; bu da dil modelinin olasıga dair hissinin dengeleyici bir etki yapabileceğini düşündürüyor.
Gelecekteki Keşifler İçin Anlamı
Genel okuyucular için ana mesaj, metin tabanlı yapay zekanın sadece makale yazmak ya da soruları yanıtlamakla kalmayıp, aynı zamanda diğer algoritmaları doğamız hakkındaki mevcut bilgimize göre "doğru hissettiren" bilimsel denklemler önermeye yönlendirebileceğidir. Burada sunulan yöntem keşfedilen her denklemin kesin olduğunu garanti etmez ve hâlâ insan denetimi ile özenle hazırlanmış istemlere dayanır. Ancak büyük dil modellerinin, bilimsel metin okyanuslarında eğitilmiş olarak, tekrar kullanılabilir bir alan bilgisi kaynağı olarak hizmet edebileceğini; otomatik araçların körce veri uydurmaktan bilim insanlarının yorumlayabileceği, kontrol edebileceği ve üzerine inşa edebileceği kanunlar önermeye doğru ilerlemesine yardımcı olabileceğini gösteriyor.
Atıf: Taskin, B., Xie, W. & Lazebnik, T. Knowledge integration for physics-informed symbolic regression using pre-trained large language models. Sci Rep 16, 1614 (2026). https://doi.org/10.1038/s41598-026-35327-6
Anahtar kelimeler: sembolik regresyon, fizik bilgili AI, büyük dil modelleri, bilimsel keşif, denklem öğrenimi