Clear Sky Science · tr
Makine öğrenmesiyle elde edilen nükleer verilerin tam çekirdek reaktör Monte Carlo nötronik ve hesaplama verimliliği analizlerindeki doğruluğunu değerlendirme
Neden daha hızlı reaktör simülasyonları önemli
Nükleer santraller, yakıtın aylar ve yıllar süren işletme boyunca nasıl davrandığını tahmin etmek için ayrıntılı bilgisayar modellerine güvenir. Bu modeller güvenlik, verimlilik ve yeni reaktörlerin tasarımı için hayati önemdedir, ancak genellikle çok yavaş ve bellek tüketimleri yüksektir. Bu makale, mühendislerin dayandığı fiziksel doğruluktan ödün vermeden bu simülasyonları besleyen devasa nükleer veri tablolarını makine öğreniminin daraltıp daraltamayacağını—hesaplama maliyetini dramatik şekilde azaltıp azaltamayacağını—araştırıyor.
Fiziğin arkasındaki verilerin küçültülmesi
Simüle edilmiş bir nötron sanal bir reaktör çekirdeği içinde hareket ettikçe, kod sekme, soğurulma veya bir atomun bölünme olasılığını tanımlayan büyük tablolara başvurur. Bu tablolar, nükleer veri kütüphaneleri olarak adlandırılır ve yakıt ve yan ürünleri için birçok izotopun binlerce enerji noktasındaki olasılıklarını kodlar. Yazarlar, bu tabloları “seyreltme” yoluyla kısaltan önceki bir makine öğrenimi yöntemini temel alır: kırılma eşikleri ve rezonans zirveleri gibi olasılıkların hızla değiştiği keskin özellikleri korurken gereksiz enerji noktalarını kaldırır. Verileri uzun, geleneksel bir işleme zinciriyle yeniden oluşturmak yerine yöntem, OpenMC’nin yerel HDF5 dosyalarını doğrudan düzenleyerek 23 özellikle önemli nuclidle orijinal ağ noktalarının yalnızca yaklaşık %10–50’sini saklar.
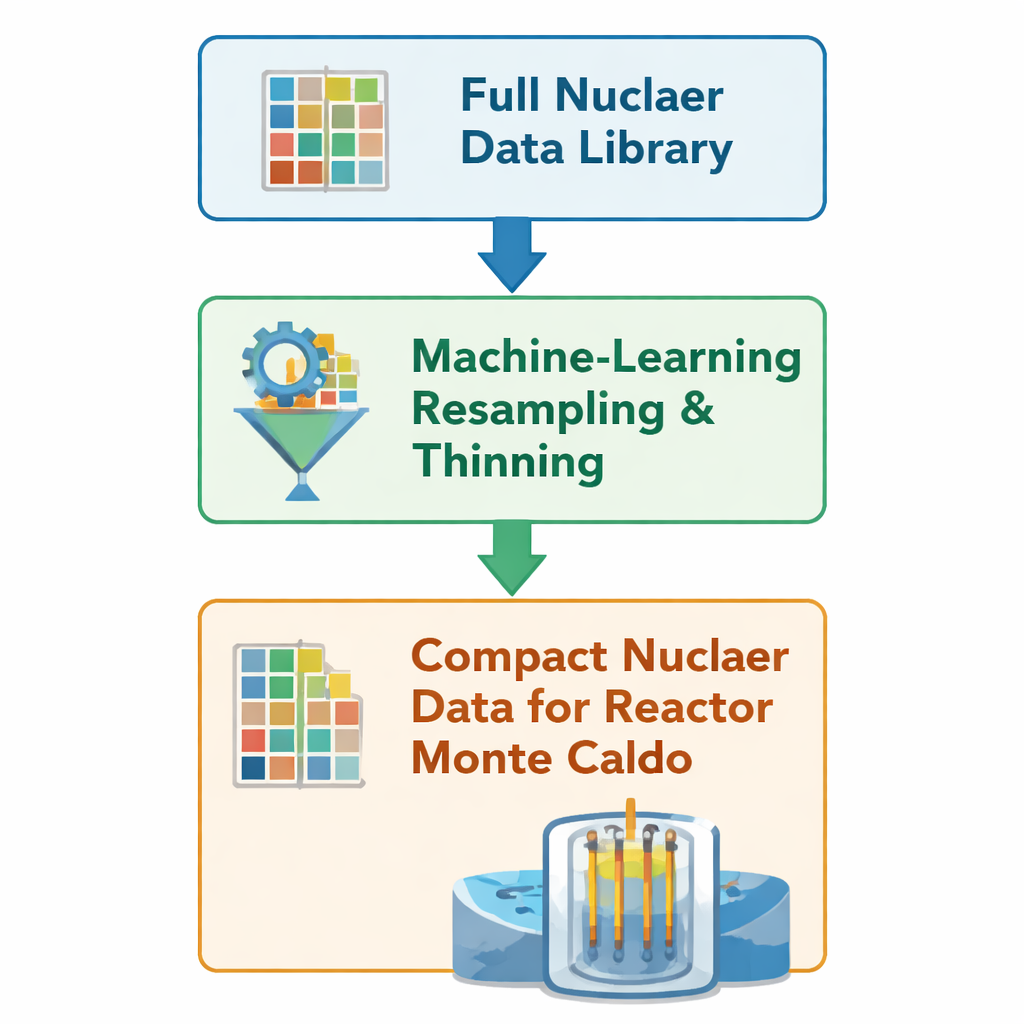
Fikri tam reaktör çekirdeklerinde test etme
Bu daha ince verinin gerçekçi ortamlarda hâlâ güvenilir sonuçlar verip vermediğini görmek için ekip, açık kaynaklı Monte Carlo kodu OpenMC’yi kullanarak iki büyük basınçlı su reaktörünün bir yıllık simülasyonlarını çalıştırır: bir Avrupa Basınçlı Reaktör (EPR) ve bir VVER‑1000. Her çekirdek için, biri tam nükleer veri kütüphanesiyle, diğeri makineyle seyreltilmiş versiyonla olmak üzere, aksi takdirde özdeş iki kampanya yürütürler. Tüm geometri, işletme koşulları ve sayısal ayarlar sabit tutulur; yalnızca fiziğin arkasındaki veri tabloları farklıdır. Hız veya bellekteki herhangi bir değişikliğin verinin azaltılmasına doğrudan bağlanabilmesi için OpenMC içindeki diğer hızlandırma özelliklerini devre dışı bırakırlar; böylece değişiklikler algoritma veya ayar farklarından değil, azaltılmış veriden kaynaklanır.
Sıkı hata sınırlarıyla hız kazanımları
Getiri kayda değerdir. EPR durumunda toplam çalışma süresi yaklaşık %18 azalırken, VVER‑1000’de çalışma süresi yaklaşık %43 kısalır. Bellek kullanımı daha ılımlı değişir: tepe kullanım EPR’de yaklaşık %4 düşer, VVER‑1000’de ise yaklaşık %5 artar; bu, her modelin nükleer veriye bakma ile parçacık yollarını geometri içinde izleme arasında ne kadar zaman harcadığındaki farkları yansıtır. Kritik olarak, ana reaktör düzeyi ölçümleri orijinallere çok yakın kalır. VVER‑1000’de tam bir yıl boyunca etkin çarpan—temelde her fisyonda ortalama kaç nötron üretildiğini gösteren değer—yaklaşık 100 parçaya milyonda daha fazla sapma göstermez ve tipik olarak sadece birkaç on parçaya milyonda sapma olur. Uranyum‑235 ve uranyum‑238’de fisyon ile ksenon‑135 ve samaryum‑149’daki nötron yakalama gibi ana reaksiyon kanalları için ortalama farklar yüzde birin onda birinden çok daha azdır.
Yakıt evrimi ve zehirler yolunda kalıyor
Uzun vadeli reaktör davranışı yalnızca ani reaksiyonlara değil, aynı zamanda yakıt ve fisyon ürünlerinin nasıl biriktiğine ve yandığına da bağlı olduğundan, yazarlar ayrıca önemli izotopların değişen stoklarını izler. Ana uranyum izotoplarını, uranyum‑238’den yetiştirilen bir plutonyum izotop ailesini ve özellikle ksenon‑135 ile samaryum‑149 gibi nötronları emen güçlü “zehir” nuclidlerini incelerler. Tam ve azaltılmış veri durumları arasındaki bu stoklardaki farklar bir yılın sonunda bile çok küçüktür: ksenon ve samaryum için birkaç yüzde puanının yüzdelik diliminin onda biri mertebesinde ve plutonyum türleri için genelde yüzde ondalık birin altında. Çekirdeğin enerji üretimini ve nötronik dengesini domine eden uranyum‑235 ve uranyum‑238, yüzde yüzbinde bile çok daha hassas şekilde yeniden üretilir. Bazı plutonyum izotopları için göreceli hataların kısa süreliğine %1’i aşması durumunda, bu döngünün erken döneminde onların mutlak miktarları hâlâ son derece küçük olduğu için pratik etkisi önemsizdir.
Gelecekteki reaktör modellemesi için anlamı
Uzman olmayanlar için temel mesaj, dikkatle eğitilmiş bir makine öğrenimi prosedürünün gelişmiş reaktör simülasyonlarındaki nükleer “arama tablolarını” önemli ölçüde daha küçük ve kullanımı daha hızlı hale getirebileceği, aynı zamanda simüle edilen reaktörün davranışını geleneksel yaklaşımdan neredeyse ayırt edilemez şekilde koruyabileceğidir. Çalışma, iki endüstriyel ölçekli reaktör çekirdeği için bir yıllık işletme boyunca bunu gösterir; hata marjları reaktör analizindeki diğer tipik belirsizliklere kıyasla küçüktür. Yazarlar sonuçlarının şu an için belirli bir veri kütüphanesini ve kod ayarlarını kullanan kararlı durum basınçlı su reaktörlerine uygulandığını ve diğer reaktör tipleri ile geçiş durumlarını test etmek için daha fazla çalışmaya ihtiyaç olduğunu vurgularlar. Yine de sonuçlar, sınırlı hesaplama kaynaklarıyla daha fazla tasarım çalışması ve güvenlik analizinin yapılmasına olanak tanıyan daha hızlı, daha verimli yüksek doğruluklu nükleer simülasyonlara yönelik ümit verici bir yol öneriyor.
Atıf: Hashemi, A., Macián-Juan, R. & Ohlerich, M. Evaluating machine learned nuclear data precision in full core nuclear reactor Monte Carlo neutronics and computational efficiency analyses. Sci Rep 16, 1314 (2026). https://doi.org/10.1038/s41598-026-35227-9
Anahtar kelimeler: nükleer reaktör simülasyonu, makine öğrenimi, Monte Carlo nötronik, nükleer veri kütüphaneleri, basınçlı su reaktörleri