Clear Sky Science · tr
Vücut kamera görüntülerinden ve genel fotoğraflardan inşaat sahalarında koruyucu ekipman eksikliğini belirlemek için alan uyumlu faster R-CNN
Neden eksik güvenlik ekipmanı hâlâ gözden kaçıyor
Baretler, yelekler, maskeler, eldivenler ve sağlam ayakkabılar inşaat sahalarında vazgeçilmez olması gereken unsurlardır; yine de ihmal vakaları olur—ve bunlar ölümcül olabilir. Birçok proje artık çalışanları gerekli ekipmandan yoksun olarak tespit etmek için kameralara ve yapay zekâya dayanıyor, fakat bu sistemler gerçek ihlallerin nadir ve filme almak açısından zor olması nedeniyle zorlanıyor. Bu çalışma, günlük sokak fotoğraflarından örnek ödünç alarak daha akıllı tespit sistemleri eğitmenin bir yolunu araştırıyor; böylece otomatik güvenlik denetimleri, kazaların veya ihlallerin birikmesini beklemeden daha güvenilir hâle getirilebiliyor.
Günlük fotoğrafları güvenlik dersine dönüştürmek
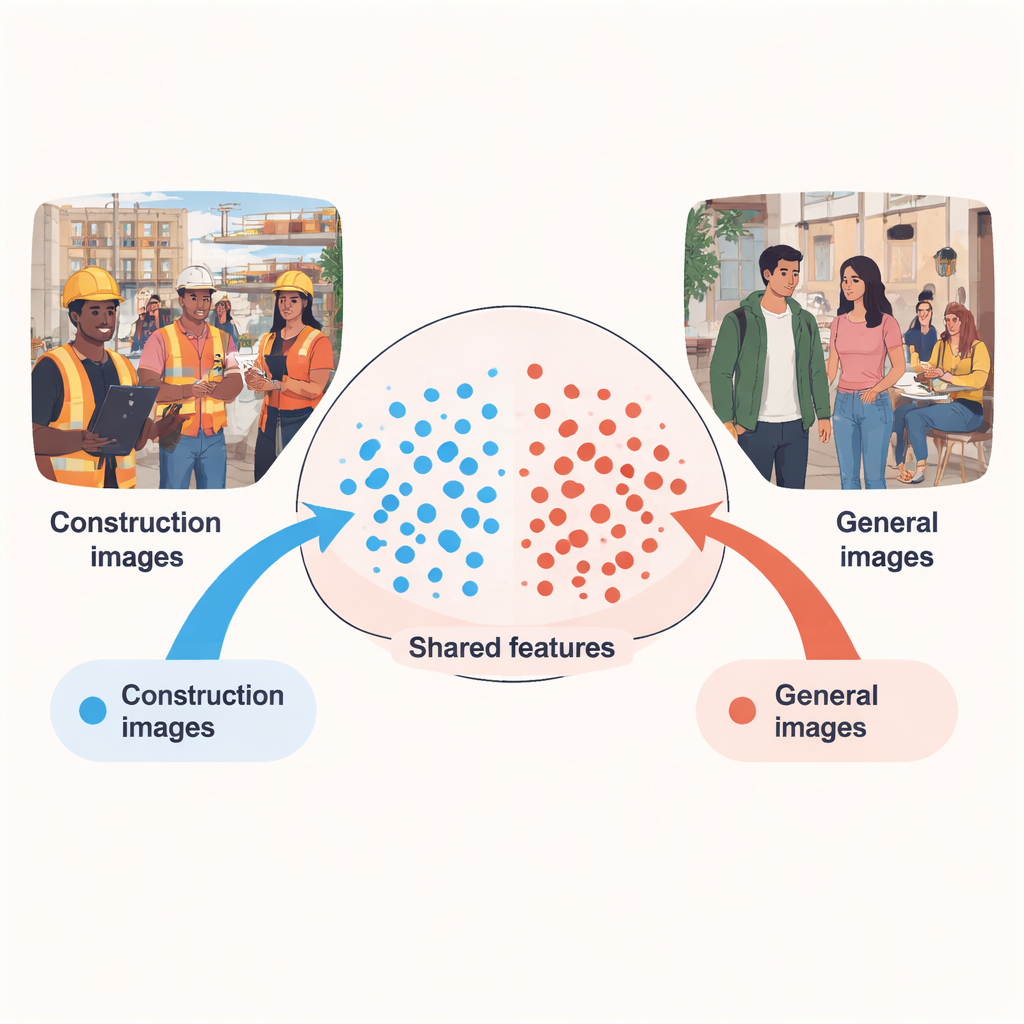
Temel fikir basit: kamusal alanlarda veya ofislerde bulunan insanlar nadiren inşaat ekipmanı giyer, dolayısıyla bu ortamlardan alınan fotoğraflar bir iş sahasında “ne giymemek gerektiğine” dair bolca örnek içerir. Zorluk, bu sahnelerin gerçek inşaat işlerinden çok farklı görünmesi—arka planlar, aydınlatma ve kamera açıları insanların nasıl göründüğünü değiştirir. Yazar, bu iki dünyayı farklı "alanlar" (domain) olarak ele alıyor: genel görüntülerden bol miktarda non‑PPE örneği içeren bir kaynak alanı ve daha az ama daha gerçekçi inşaat sahası görüntüleri içeren, çoğu işçi kaskına monte kameralarla çekilmiş bir hedef alanı. Makale, bilgisayarın her iki alandan öğrendiklerini dikkatli biçimde hizalayarak sistemin gerçek sahalarda eksik ekipmanı, yalnızca inşaat verileriyle eğitildiğinden çok daha doğru biçimde tespit edebileceğini gösteriyor.
Yeni güvenlik denetleyicisinin sahneyi görme biçimi
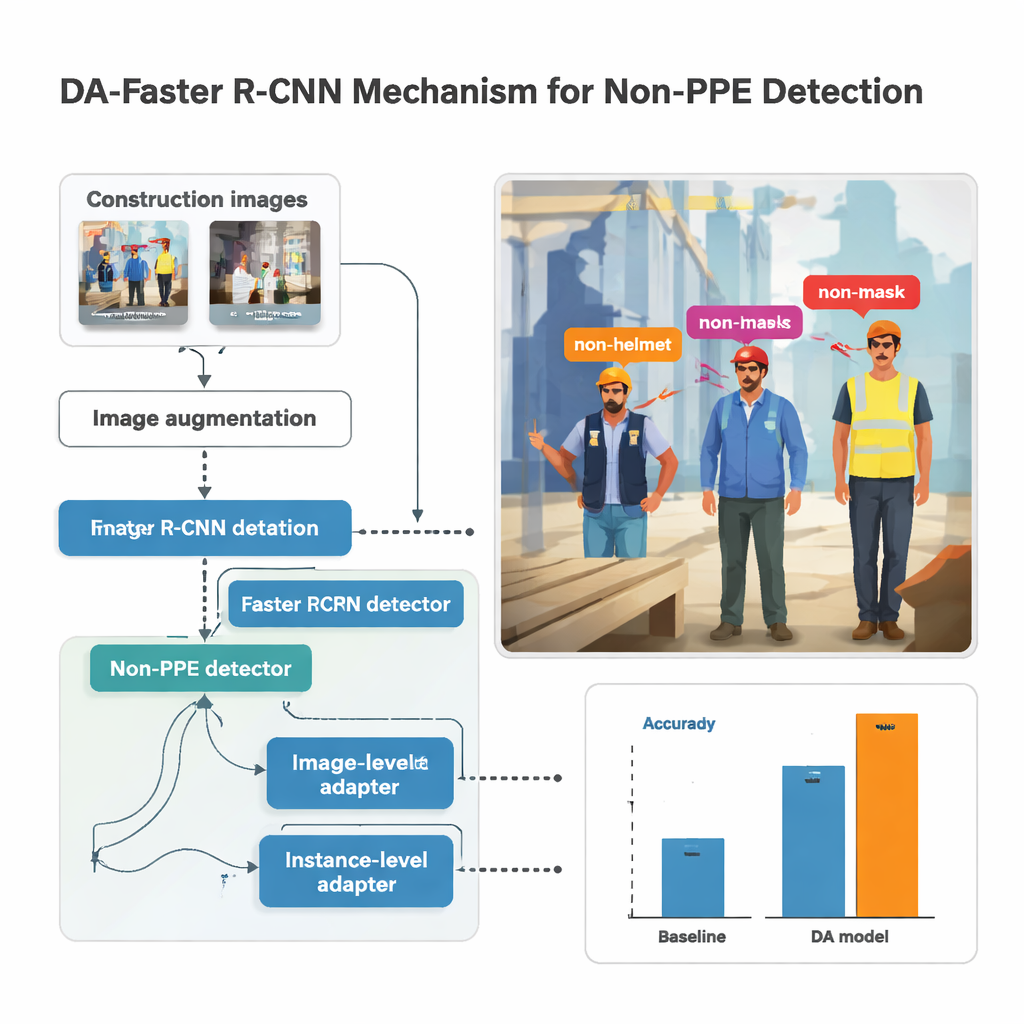
Araştırma, bir görüntüyü tarayan, içinde insanlar veya vücut parçaları bulunma olasılığı yüksek bölgeler öneren ve ardından her kutunun içindekini sınıflandıran popüler bir nesne tespiti sistemi olan Faster R‑CNN üzerine kuruludur. Burada detektör, beş tür eksik ekipmanı tanımak üzere eğitilmiştir: başlıksız (non‑helmet), maskesiz (non‑mask), eldivensiz (non‑glove), yeleksiz (non‑vest) ve ayakkabısız (non‑shoes). Görüntüler modele verilmeden önce, sarsılmış kameralar, sert güneş ışığı ve yoğun sahalarda sık rastlanan garip açılar gibi koşulları taklit etmek için parlaklık artırma veya azaltma, döndürme, bulanıklaştırma ve çarpıtma gibi yoğun veri çoğaltma (augmentation) uygulanır. Bu sentetik çeşitlilik, modelin vücut kameralarından elde edilen gerçek dünya görüntüleri mükemmel olmadığında bile kararlı kalmasına yardımcı olur.
Sisteme arka planı görmezden gelmeyi öğretmek
Sokağa ait fotoğrafları inşaat görüntüleriyle basitçe karıştırmak yetmez; model eksik ekipmanı şehir kaldırımlarıyla ilişkilendirmeyi öğrenebilir. Bunu önlemek için çalışma, sistemi çevresindeki sahne yerine insanlara ve kıyafetlere odaklanmaya nazikçe yönlendiren "alan uyumu" modüllerini tanıtıyor. Bir modül görüntüyü bütün olarak ele alır; farklı aydınlatma veya ekipmana rağmen inşaat ve inşaat dışı fotoğrafların benzer genel desenler üretmesini teşvik eder. Diğeri ise her tespit edilen kişi düzeyinde çalışır; örneğin korumasız bir başın görsel imzasının iskeleden veya alışveriş caddesinden ortaya çıkıp çıkmadığına bakılmaksızın benzer olmasını sağlar. Bu modüller adveraryal bir biçimde eğitilir: küçük bir sınıflandırıcı görüntünün hangi alandan geldiğini söylemeye çalışırken, ana ağ bu bilgiyi gizlemeyi öğrenir ve böylece odağını koruyucu ekipmana çevirir.
Yöntemi teste sokmak
Yazar, Güney Kore’deki beş inşaat sahasından alınan vücut kamera görüntülerini birkaç açık görüntü koleksiyonuyla birleştirerek kayda değer bir veri seti topladı. Baret, maske, eldiven, yelek ve güvenlik ayakkabısının eksik olduğu her örneğin elle etiketlenmesinin ardından çalışma, farklı sinir ağı omurgaları ve parametre ayarlarıyla yüzlerce model eğitti. En iyi performans gösteren yapı, güçlü görüntü çoğaltma ve alan uyum modülleriyle birlikte ResNet‑152 adlı derin bir ağ kullandı. Daha önce görülmemiş inşaat görüntülerinde bu düzenleme, tespit kalitesi için genel bir puan olan ortalama Ortalama Doğruluk (mAP) yaklaşık %86,8 elde ederken, saniyede yaklaşık 33 kare hızında çalıştı; bu da neredeyse gerçek zamanlı izleme için yeterince hızlıdır. Geleneksel denetimli sistemlerle karşılaştırıldığında, uyarlanmış model doğruluğu en fazla 14 puan geliştirdi ve daha basit bir temel modele göre 39 puana kadar iyileşme gösterdi.
Bu durum daha güvenli sahalar için ne anlama geliyor
Uzman olmayanlar için çıkarılacak nokta şudur: yalnızca daha büyük veri kümeleri değil, daha akıllı eğitim de otomatik güvenlik izlemini çok daha güvenilir kılabilir. Hem günlük fotoğraflardan hem de gerçek iş sahalarından öğrenerek ve sistemin önemsiz arka plan ayrıntılarını görmezden gelmesini öğreterek önerilen yaklaşım, gerçek ihlaller nadir olsa bile baret, yelek, eldiven, maske ve güvenlik ayakkabısı eksikliklerini yüksek güvenilirlikle tespit eder. Mevcut çalışma beş ekipman türü ve tek bir ana inşaat veri setine odaklansa da, bu yöntem pek çok sahada yardımcı kayışlar, halatlar ve diğer güvenlik teçhizatı izleyebilecek gelecekteki sistemler için pratik bir yol haritası sunar; böylece denetçiler tüm gün video ekranlarına bakmak zorunda kalmadan problemleri erken yakalayabilir ve işçileri daha güvende tutabilir.
Atıf: Wang, S. Domain-adaptive faster R-CNN for non-PPE identification on construction sites from body-worn and general images. Sci Rep 16, 4793 (2026). https://doi.org/10.1038/s41598-026-35148-7
Anahtar kelimeler: inşaat güvenliği, kişisel koruyucu donanım, bilgisayarla görme, alan uyumu, nesne tespiti