Clear Sky Science · tr
Cümle benzerlik skorunun hesaplanması: özellikle olumsuzlama cümlelerine odaklanan hibrit derin öğrenme
Neden kelime anlamı adil notlama için önemlidir
Öğrenciler soruları kendi sözcükleriyle yanıtladığında, öğretmenlere yardımcı olan bilgisayarlar yalnızca ortak anahtar kelimeleri anlamaktan daha fazlasını bilmek zorundadır. “Değil” gibi küçük bir kelime bir cümlenin anlamını tersine çevirebilir ve otomatik sistemler bu ters dönüşü kaçırırsa öğrenciler haksız değerlendirilebilir. Bu makale, bilgisayarların cümlelerin anlamlarını karşılaştırırken olumsuzlama sözcüklerinin anlamı nasıl değiştirdiğine özel önem veren yeni bir yöntem tasarlayarak bu sorunu ele alır.
Büyük etkiye sahip küçük kelimelerin zorluğu
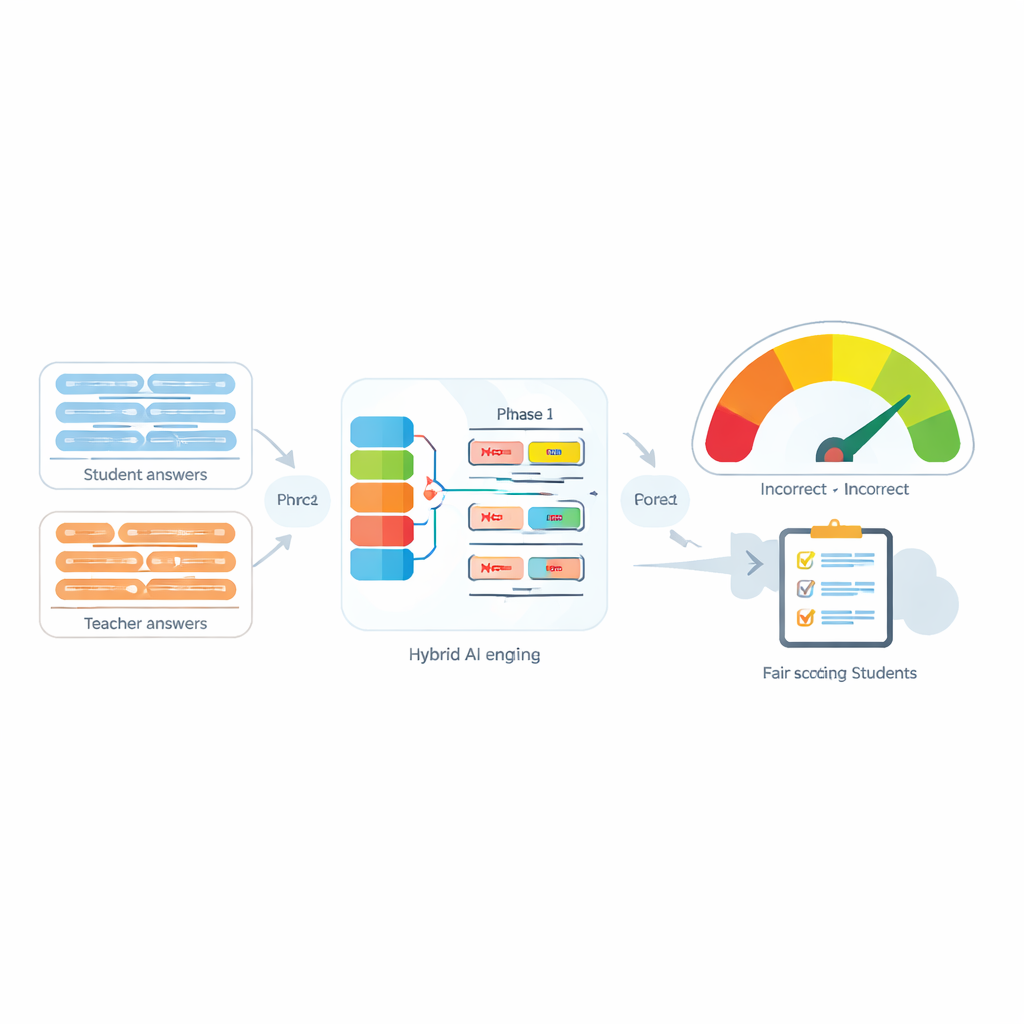
Otomatik Değerlendirme Sistemleri, öğrenci yanıtını öğretmenin model cevabı ile karşılaştırarak öğretmenlerin iş yükünü hafifletmek için giderek daha fazla kullanılıyor. Birçok modern araç, her cümleyi sayısal bir “parmak izi”ne dönüştürüp bu parmak izlerinin ne kadar yakın olduğuna bakarak bunu yapıyor. Bu araçlar olumsuzlama yoksa makul düzeyde iyi çalışıyor, ancak “değil”, “asla” veya “yok” gibi kelimeler göründüğünde sık sık başarısız oluyorlar. Örneğin, “Yöntem doğrudur” ile “Yöntem doğru değildir” bilgisayar için şaşırtıcı derecede benzer görünebilir, oysa anlamları zıttır. Yazarlar, yalnızca olumsuzlamanın varlığının değil, aynı zamanda kaç tane olumsuzlama kelimesi olduğunun ve bunların cümlede nerede yer aldığının da niyeti tamamen değiştirebileceğini gösteriyorlar.
İnceliği öğreten bir veri seti oluşturmak
Gerçekten olumsuzlamayı anlayan bir sistemi eğitmek için yazarların önce bu zorlu durumları vurgulayan verilere ihtiyaçları vardı. Negation-Sentence-Similarity Dataset adlı veri setini oluşturdular; bu veri seti, işletim sistemleri, veritabanları, bilgisayar ağları ve makine öğrenmesi olmak üzere dört bilgisayar bilimi alanından 8.575 cümle çiftini içeriyor. Her çift için insanlar, olumsuzlamayı göz önünde bulunduran bir benzerlik puanı atadılar. Veri seti ayrıca her cümlenin kaç olumsuzlama kelimesi kullandığını ve tek bir “değil”, çift ya da tek sayıda olumsuzlama gibi hangi olumsuzlama desenini izlediğini veya olumsuzlamanın “çünkü” veya “ama” gibi bağlaçlarla etkileşime girdiği daha karmaşık durumları kaydeder. Bu ayrıntılı etiketleme, modele olumsuzlamanın anlamı nasıl şekillendirdiği konusunda açık ipuçları verir.
Çoklu bakış açılarını birleştiren hibrit bir motor
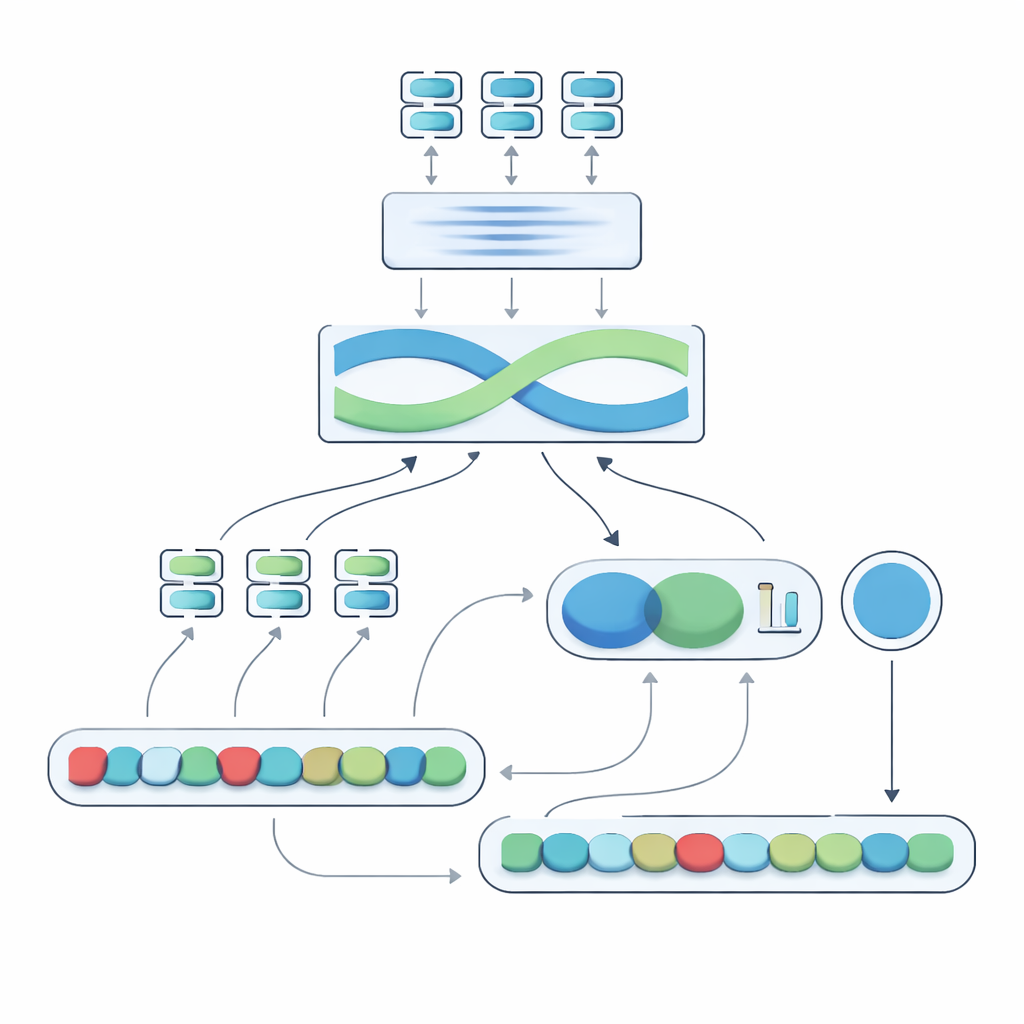
Negation-Aligned Similarity Scorer adındaki önerilen sistemin özü iki aşamalı bir motordur. Birinci aşamada sistem, her cümleyi anlamın biraz farklı yönlerini yakalayan birkaç farklı dil modelinden geçirir. Bu modellerin çıktıları birleştirilir ve ardından kelime sırasını ve yerel bağlamı dikkate alan çift yönlü tekrarlayan bir ağa verilir. Bu, olumsuzlama sözcüklerinin diğer sözcüklere göre nerede durduğunu da içerecek şekilde ince ifade farklılıklarına daha iyi ayarlanmış her cümlenin kompakt bir özetini üretir.
Modele olumsuzlamanın tersini hissettirmeyi öğretmek
İkinci aşamada sistem, iki cümle özetini karşılaştırır ve olumsuzlama hakkında açık bilgileri ekler. Özetlerin ne kadar farklılaştığına, ne kadar örtüştüğüne bakar ve bu sinyalleri üç basit özellikle birleştirir: olumsuzlama kelime sayısı farkı, cümlelerde olumsuzlama sayısının tek veya çift olup olmadığı (bu negatif anlamı tersine çevirebilir veya iptal edebilir) ve olumsuzlamanın yaklaşık olarak karşılık gelen pozisyonlarda görünüp görünmediği. Bu ipuçlarının tümü, 0 ile 100 arasında bir benzerlik skoru veren küçük bir tahmin ağında harmanlanır. Düzenlenmiş veri seti üzerinde uçtan uca eğitildiğinde, bu skor “değil”i sadece başka bir kelime olarak görmek yerine olumsuzlamanın anlamı nasıl yeniden şekillendirdiğine duyarlı hale gelir.
Yeni skorerin pratikteki performansı
Yaklaşımlarını test etmek için yazarlar hem kendi özel veri setlerinde hem de yaygın kullanılan bir cümle benzerliği kıyas setinde değerlendirme yaparlar. Standart yöntemleri kullanan güçlü dönüştürücü tabanlı taban modellerle karşılaştırıldığında, yeni skorer daha düşük tahmin hatası ve çok daha yüksek sınıflandırma kalitesi elde eder; F1 skoru yaklaşık 0,97’ye yakındır. Titizlikle seçilmiş örneklerde, olumsuzlama anlamı açıkça tersine çevirdiğinde düşük benzerlik puanları verir ve çift olumsuzlamanın etkili şekilde iptal ettiği durumlarda yüksek puanlar verirken, rekabet eden modeller genellikle benzerliği fazla tahmin etme eğilimindedir. Bir eksiltme (ablation) çalışması, hem sıra bilgisi gözeten tekrarlayan katmanın hem de açık olumsuzlama özelliklerinin bu performans artışı için önemli olduğunu doğrular.
Bu durum öğrenciler ve gelecekteki araçlar için ne anlama geliyor
Gayri uzman bir okuyucu için çıkarım basittir: “değil” demenin biçimi önemlidir ve makinelere bunu fark etmeyi öğretmek mümkündür. Birden çok dil modelini, bağlamsal işlemi ve olumsuzlama kelimelerinin basit sayımlarını ve konumlarını harmanlayarak önerilen skorer, iki cümlenin gerçekten aynı anlama gelip gelmediğini daha adil ve güvenilir biçimde değerlendirme olanağı sunar. Bu, otomatik değerlendirme sistemlerinin “izin verilmiyor”u “izin veriliyor” gibi ciddi hatalar yapmasını önlemeye yardımcı olabilir. Yöntem daha fazla hesaplama gerektirse ve hâlâ teknik alanlara odaklı olsa da, günlük dilin ince mantığını daha iyi yakalayan gelecekteki araçlara işaret eder; böylece otomatik dil teknolojileri hem daha akıllı hem de daha güvenilir hale gelir.
Atıf: M, R., L, J., Ummity, S.R. et al. Computation of sentence similarity score through hybrid deep learning with a special focus on negation sentence. Sci Rep 16, 8904 (2026). https://doi.org/10.1038/s41598-025-34084-2
Anahtar kelimeler: cümle benzerliği, dilde olumsuzlama, otomatik notlandırma, doğal dil işleme, derin öğrenme modelleri