Clear Sky Science · tr
StatLLM: Büyük Dil Modellerinin İstatistiksel Analizdeki Performansını Değerlendirmek İçin Bir Veri Seti
Günlük veri kullanıcıları için bunun önemi
Sohbet tabanlı asistanlar gibi yapay zekâ araçları günlük işe dahil oldukça, daha çok insan onlardan sayı hesaplamasını, deney yürütmesini ve veri analizini istemeye başladı. Ancak bir yapay zekâ bir istatistiksel çalışma için kod yazdığında—örneğin yeni bir tıbbî tedavinin işe yarayıp yaramadığını kontrol etmek veya okul performans verilerini incelemek gibi—işin doğru yapıldığını nasıl biliriz? Bu makale, büyük dil modellerinin gerçek istatistiksel analiz görevlerini ne kadar iyi yerine getirdiğini sınamak üzere tasarlanmış kamuya açık bir veri seti olan StatLLM’yi tanıtıyor; araştırmacılara ve uygulayıcılara yapay zekâ tarafından yazılan koda ne zaman güvenileceğine ve ne zaman temkinli olunacağına dair daha net bir bakış sağlıyor.
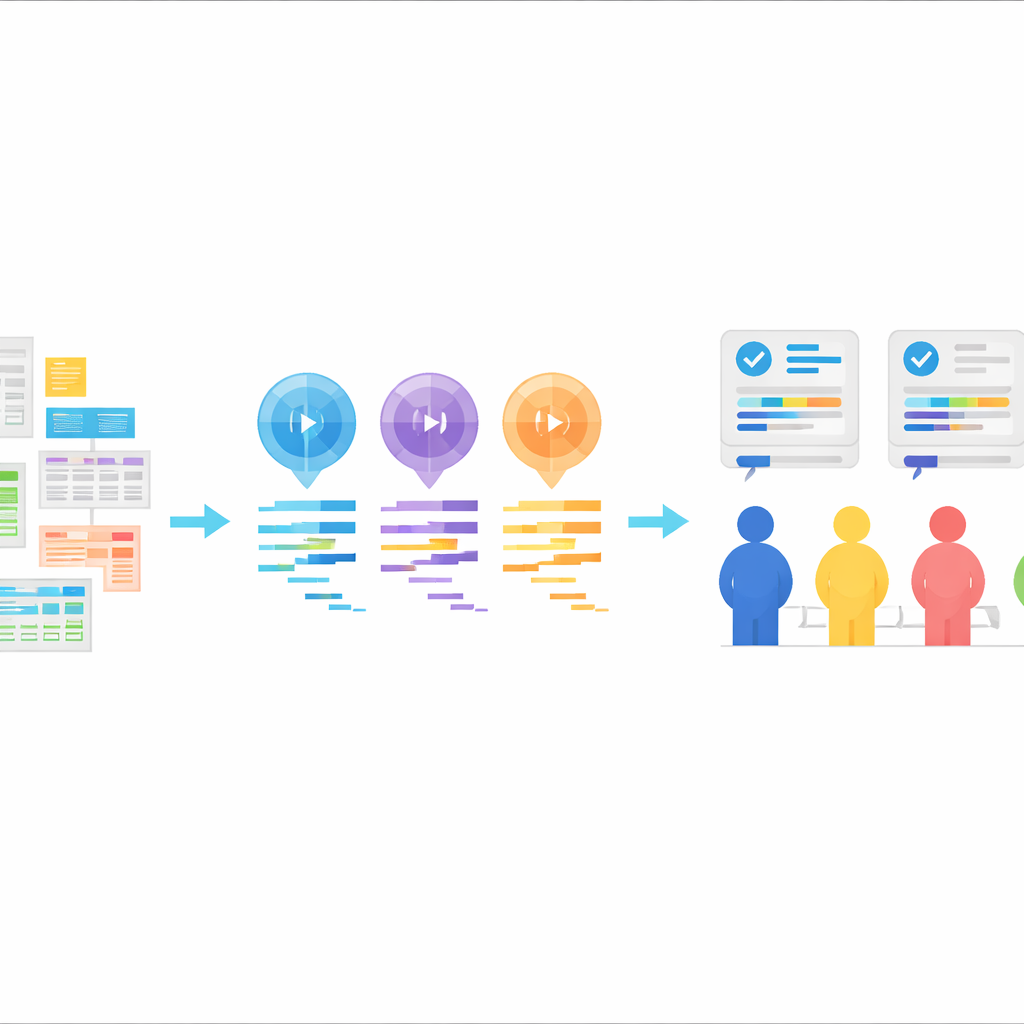
Yapay zekâ tarafından yazılan istatistik kodu için yeni bir test ortamı
StatLLM’nin özünde eğitim, tıp, işletme, finans, mühendislik ve spor gibi alanlardan alınmış 65 gerçek veri kümesinden oluşturulmuş 207 dikkatle derlenmiş istatistiksel analiz görevi bulunuyor. Her görev, yalın dille bir problem tanımı, veri seti ve değişkenler hakkında ayrıntılı açıklama ve insan uzmanlar tarafından yazılmış ve doğrulanmış kısa bir SAS kodu içeriyor. Görevler, güçlü bir lisans veya yüksek lisans düzeyindeki bir istatistik öğrencisinin öğrenebileceklerini kapsayacak şekilde; basit veri özetleri ve grafiklerden regresyon, sağkalım analizi ve daha ileri yöntemlere kadar uzanıyor. Bu, yapay zekâ araçlarının pratik soruları anlayıp bunları sağlam analiz adımlarına dönüştürme yeteneğini gerçekçi, hem sınıf hem de endüstri tarzında test ediyor.
Yapay zekânın kod yazmasına izin verip sonra işini notlandırmak
Yazarlar bu görevleri kullanarak üç büyük dil modelinden—GPT-3.5, GPT-4 ve Llama‑3.1 70B—SAS kodu üretmelerini istediler. Her modele aynı bileşenler verildi: görev tanımı, veri kümesi açıklaması, gerçek veri dosyası ve SAS kodu üretmeye dair açık bir talimat. Modeller “sıfır vuruş” (zero-shot) biçimde kullanıldı; yani önceden doğru SAS kodu örnekleri gösterilmedi. Yanıtlar yalnızca kod kalacak şekilde temizlendi, açıklamalar çıkarıldı. Bu kurulum, gerçek dünyada sıkça görülen bir deseni taklit ediyor: kullanıcı ne istediğini anlatıyor, yapay zekâ kodu döndürüyor ve o kod istatistik paketinde çalıştırılıyor.
Altın standart olarak insan uzmanlar
Yapay zekâ tarafından yazılan kodun gerçekten ne kadar iyi olduğunu görmek için ekip titiz bir insan incelemesi düzenledi. Dokuz deneyimli SAS kullanıcısı, her biri performansın bir bölümüne odaklanan üç grup oluşturdu: kodun mantıksal doğruluğu ve okunabilirliği; kodun hatasız çalışıp çalışmadığı; ve elde edilen çıktının orijinal soruyu açık ve doğru şekilde yanıtlayıp yanıtlamadığı. Her görev için üç modelin SAS programları karıştırıldı, böylece puanlayıcılar hangi kodu hangi modelin ürettiğini bilmiyordu. Puanlar beş puanlık bir ölçekte verildi ve birleşik bir toplam elde edilerek yüzlerce model–görev çifti arasında güçlü ve zayıf yönlerin nüanslı bir görünümü sağlandı. Bu uzman değerlendirmeleri şimdi StatLLM veri setindeki tüm kod ve görevlerle birlikte yer alıyor.
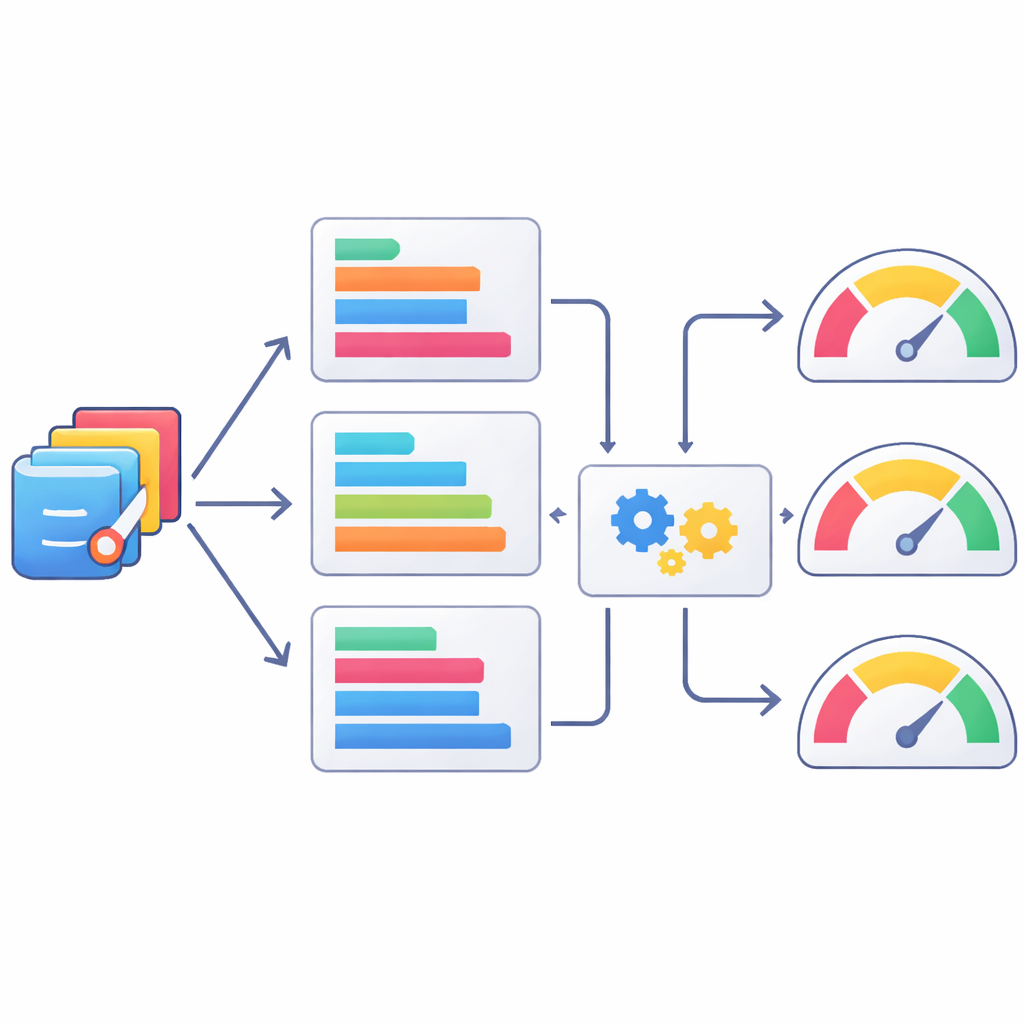
Makinelere insan gibi kod değerlendirmeyi öğretmek
İnsan incelemesi yavaş ve pahalı olduğundan, yazarlar otomatik metin tabanlı ölçütlerin istatistik kodu kalitesinin kaba yargıcı olarak ne kadar iyi işe yaradığını da araştırdı. AI tarafından üretilen SAS programlarını insan onaylı sürümleriyle karşılaştırmak için iyi bilinen doğal dil işleme puanları dizisini kullandılar ve bu puanların insan değerlendirmeleriyle nasıl örtüştüğünü kontrol ettiler. Kısa token dizilerindeki örtüşmeleri izleyen ROUGE varyantları gibi bazı ölçütler insan yargılarıyla diğerlerinden daha iyi korelasyon gösterdi, ancak hepsi yalnızca ılımlı derecede uyum sağladı. Ekip bir adım daha ileri giderek bu ölçütlerin kombinasyonlarından insan puanlarını tahmin etmek için makine öğrenmesi modelleri eğitti. XGBoost gibi yöntemler insan puanlarıyla uyumu iyileştirdi, ancak yine de uzman yargısını kusursuzca yakalamaktan çok uzaktı; bu da otomatik puanların en iyi ihtimalle kısmi vekiller olduğunu vurguluyor.
Geleceğin yapay zekâ destekli istatistik araçlarına doğru inşa etmek
Benchmark’un ötesinde, yazarlar StatLLM’nin yeni araçlar ve araştırma yönlerini nasıl destekleyebileceğini gösteriyor. Her görev genel terimlerle tanımlandığı için aynı problemler R veya Python gibi diğer dillerde kod üretimini test etmek veya birden fazla dilden kodu birleştirmek için kullanılabilir. Makale, daha yüksek güvenilirlik için farklı yapay zekâ tarafından üretilmiş çözümleri karıştırabilecek ansambl yaklaşımlarını vurguluyor ve kullanıcıların bir veri kümesi ve görev açıklaması yüklediği ve bir yapay zekâ sisteminin otomatik olarak R kodu ürettiği ve çalıştırdığı bir prototip R Shiny uygulamasını gösteriyor. StatLLM ayrıca doğal dil talimatlarını anlayan, aynı zamanda açık ve ölçülebilir standartlara tabi tutulan bir sonraki nesil istatistik yazılımını tasarlayıp test etmek için bir platform sağlıyor.
Veri analizinde yapay zekâ kullanmak ne anlama geliyor
Uzman olmayanlar için temel çıkarım, yapay zekânın kısa istatistik kodu parçacıkları yazabildiği, ancak güvenilirliğin henüz garanti edilmediği—özellikle basit örneklerin ötesine geçen görevlerde—gerçeğidir. StatLLM, farklı modellerin ne kadar iyi performans gösterdiğini görmek, onların işi üzerindeki otomatik kontrolleri geliştirmek ve daha güvenli, daha sağlam veri analiz araçları tasarlamak için şeffaf, yeniden kullanılabilir bir yol sunuyor. Yeni dil modelleri ortaya çıktıkça bunlar bu canlı benchmark’a eklenebilir ve alandaki yapay zekânın ciddi istatistiksel çalışmalarda neleri yapıp neleri yapamadığı konusunda gerçekçi kalmayı sağlar.
Atıf: Song, X., Lee, L., Xie, K. et al. StatLLM: A Dataset for Evaluating the Performance of Large Language Models in Statistical Analysis. Sci Data 13, 369 (2026). https://doi.org/10.1038/s41597-026-06731-4
Anahtar kelimeler: büyük dil modelleri, istatistiksel analiz, kod değerlendirmesi, ölçüt veri seti, SAS programlama