Clear Sky Science · tr
Somut Olmayan Kültürel Miras için Bir Çince Adlandırılmış Varlık Tanıma Veri Kümesi
Yaşayan gelenekleri korumanın akıllı okumaya neden ihtiyacı var
Dünya genelinde halk müziği, el sanatları ve yerel festivaller gibi yaşayan gelenekler günlük yaşamdan silinme riski taşıyor. Çin’de bu uygulamaları tanımlayan çok miktarda yazı zaten mevcut, ancak bunların çoğu uzun web sayfalarında yer alıyor ve insanların — ya da bilgisayarların — arayıp analiz etmesi zor oluyor. Bu çalışma, bu metinlerdeki zanaat adları, ustalar, malzemeler ve yerler gibi önemli bilgileri otomatik olarak tespit edebilen özenle oluşturulmuş bir Çince veri kümesini ve gelişmiş bir yapay zeka modelini tanıtıyor. Birlikte, somut olmayan kültürel mirası dijital ölçekte korumaya ve incelemeye yardımcı olacak yeni araçlar sunuyorlar.
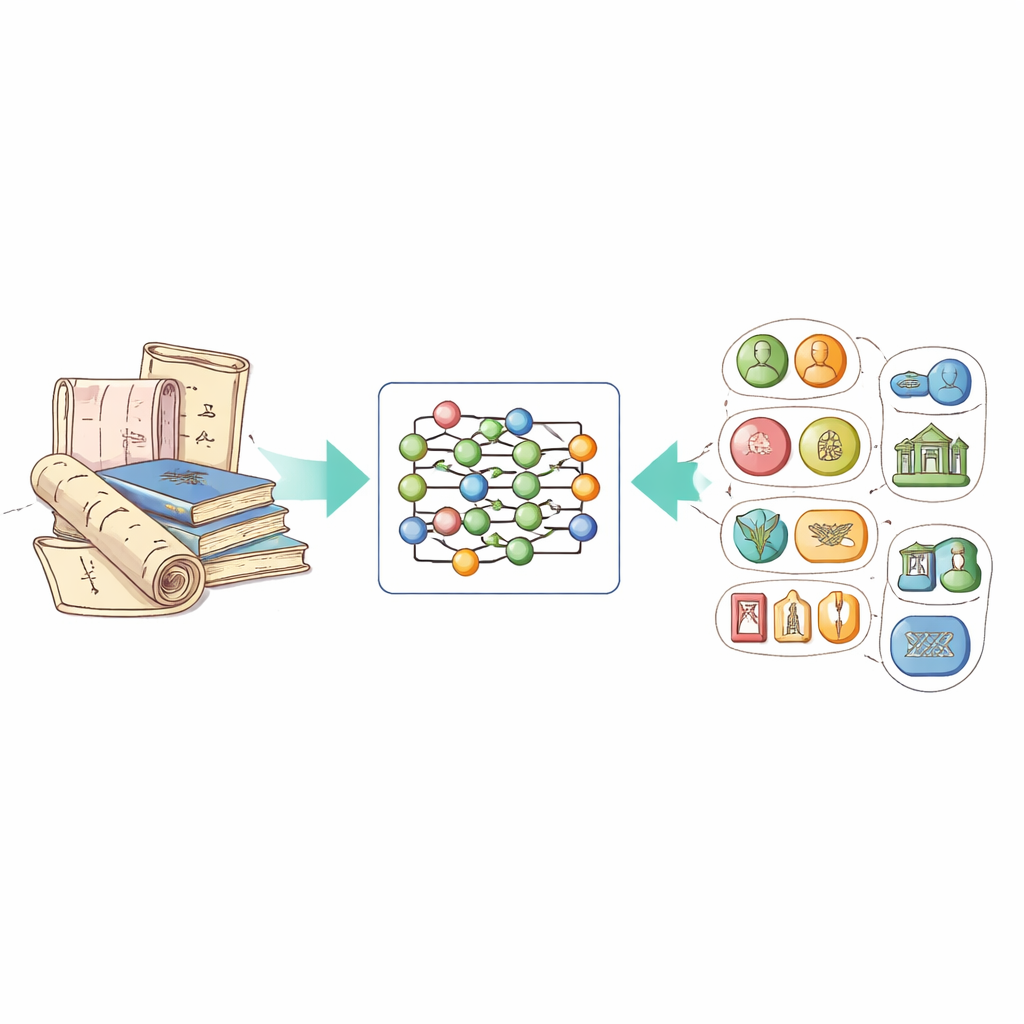
Düzensiz metni düzenli bilgiye dönüştürmek
Çalışmanın temel fikri, bilgisayarlara metindeki önemli öğeleri vurgulamayı öğreten adlandırılmış varlık tanıma adlı bir teknoloji. Bu teknoloji insanları, yerleri, zamanları, kurumları vb. tespit ediyor. Somut olmayan kültürel miras için bu, miras projelerinin adları, belirli zanaat teknikleri ve kullanılan malzemeler gibi özel varlık türlerini de tanımak anlamına geliyor. Sorun şu ki, şimdiye kadar bu alana özgü halka açık bir Çince veri kümesi yoktu ve genel amaçlı sistemler miras belgelerindeki canlı betimlemeler, şiirsel dil ve bölgesel ifadelerle zorlanıyordu.
Miras metinlerinden odaklanmış bir koleksiyon oluşturmak
Bu boşluğu doldurmak için yazarlar, Çin’in resmi Somut Olmayan Kültürel Miras Ağı’ndan ICH-NER adlı yeni bir veri kümesi derlediler. Geleneksel tekstil, seramik, metal işçiliği ve oyma gibi zanaatla ilgili girdilere odaklandılar; çünkü bu tanımlar süreçler ve malzemeler hakkında zengin ayrıntılar içeriyor. Duyurular ve kopyalar temizlendikten sonra sekiz ana varlık kategorisi tasarladılar: miras öğesi adları, yerler, kişiler, kuruluşlar, zaman dilimleri, etnik gruplar, malzemeler ve zanaatkarlık. Metinlerdeki her Çince karakter, bir varlığa ait olup olmadığını ve öyleyse hangi türden olduğunu gösteren basit bir kodla etiketlendi. Toplamda veri kümesi 7.779 örnek ve 21.000’den fazla etiketlenmiş varlık içeriyor ve bu da onu gelecekteki araştırmalar için sağlam bir kıstas yapıyor.
Tutarlı etiketleme için özenli kurallar
Bu tür miras metinleri için standart bir sınıflandırma sistemi olmadığından, araştırmacılar önce ulusal miras listeleri ve resmi tanımlamalara dayanan ayrıntılı yönergeler oluşturdular. Proje adlarının parçası olan yerler veya bir varlığın başka bir varlık içinde yer aldığı iç içe ifadeler gibi zor durumları ele almak için pilot bir aşama yürüttüler. Ardından tek bir eğitimli notlayıcı tüm veri kümesini açık kaynaklı yazılımla etiketledi ve tutarsızlıkları düzeltmek için önceki çalışmaları tekrar tekrar gözden geçirdi. Nihai veriler eğitim ve geliştirme setlerine ayrıldı; her varlık türünün benzer oranlarda korunmasına ve her iki parçanın da bölgesel terimler ile yazı stilleri bakımından iyi bir karışıma sahip olmasına dikkat edildi.
Miras diline uyarlanmış bir yapay zeka modeli tasarlamak
Veri kümesine ek olarak çalışma, birden çok modern yapay zeka bileşenini üst üste koyan özel bir tanıma modeli öneriyor. İlk olarak güçlü bir dil kodlayıcı (RoBERTa), Çince karakterleri çevreleyen metindeki kullanımını yansıtan bağlam farkındalığına sahip sayısal temsillere dönüştürüyor. Ardından Kolmogorov–Arnold Ağı modülü, belirli malzemelerin belirli teknikler veya bölgelerle nasıl eşleşme eğiliminde olduğuna dair nüanslı, doğrusal olmayan desenleri öğreniyor. Çoklu başlıklı dikkat katmanı daha sonra tüm cümle içindeki ilişkileri birden çok açıdan inceliyor ve son olarak çözücü katman en olası etiket dizisini seçiyor. Bu mimari, metaforlarla ve katmanlı kültürel göndermelerle dolu uzun, karmaşık cümlelerle başa çıkacak şekilde tasarlandı.
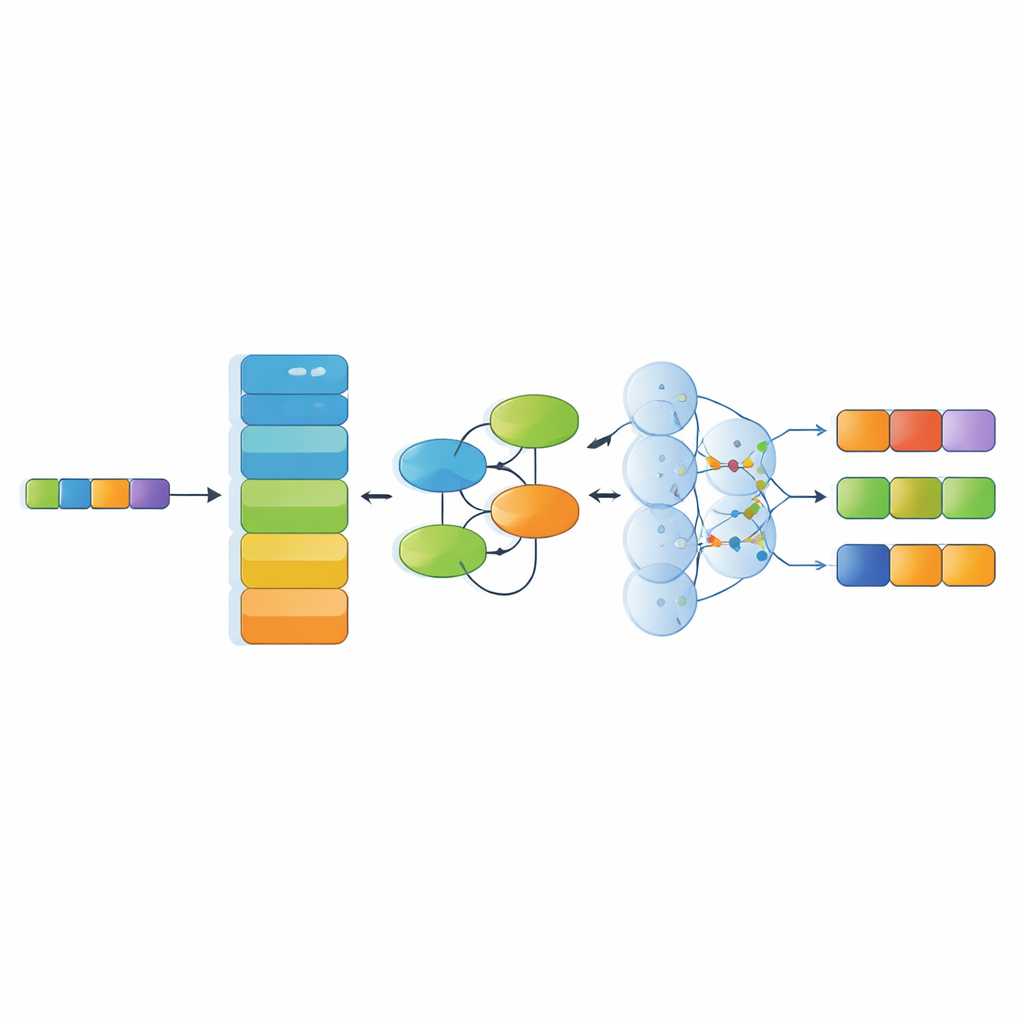
Sistemin miras metnini anlama başarısı
Yazarlar, modellerini dil araştırmalarında yaygın olarak kullanılan birkaç güçlü temel yöntemle karşılaştırdı; bunlar arasında tekrarlayan ağlara dayalı sistemler, Çince metin için ızgara/lattice yapıları ve varlıkları segmentler olarak ele alıp adım adım rafine eden yakın tarihli bir yöntem yer aldı. ICH-NER veri kümesinde, modern ön-eğitimli dil modellerine dayanan yöntemler açıkça daha eski yaklaşımlardan üstün performans gösterdi. Birleştirilmiş RoBERTa–KAN–dikkat–çözücü sistemleri, özellikle veri görece kısıtlı ve tanımların sıklıkla karmaşık veya belirsiz olduğu malzemeler, kuruluşlar ve zanaat teknikleri gibi zor kategorilerde en iyi genel hassaslık ve geri çağırma dengesine ulaştı.
Dijital çağda yaşayan kültür için anlamı nedir
Pratik açıdan yeni veri kümesi ve model, bilgisayarların geleneksel zanaatların zengin tanımlarından kim, ne, nerede ve ne zaman gibi bilgileri çıkarmasını kolaylaştırıyor. Bu yapılandırılmış bilgi, tekniklerin nasıl yayıldığını, belirli ailelerin veya bölgelerin bir zanaatı nasıl şekillendirdiğini ve uygulamaların zaman içinde nasıl evrildiğini araştırmacıların, küratörlerin ve kamunun keşfetmesine yardımcı olacak bilgi grafikleri, etkileşimli haritalar veya arama araçlarına aktarılabilir. Çalışma teknik olsa da etkisi insani: yaşayan geleneklerin dağınık, metin odaklı betimlerini daha iyi destekleyecek şekilde düzenlenmiş bilgiye dönüştürmenin bir yolunu sunuyor ve somut olmayan kültürel mirasın korunması ile anlaşılmasını güçlendiriyor.
Atıf: Long, S., Li, W. A Chinese Named Entity Recognition Dataset for Intangible Cultural Heritage. Sci Data 13, 335 (2026). https://doi.org/10.1038/s41597-026-06700-x
Anahtar kelimeler: somut olmayan kültürel miras, adlandırılmış varlık tanıma, Çince dil işleme, kültürel veri kümeleri, dijital koruma