Clear Sky Science · tr
Otomatik Raporlamaya Doğru: Çok Modlu Büyük Dil Modellerini Geliştirmek İçin Bir Bronkoskopi Raporu Veri Kümesi
Akciğer Doktorlarına Daha Akıllı Destek
Doktorlar havayollarının içine küçük bir kamera ile baktıklarında hastanın akciğerleri hakkında çok şey öğrenirler — fakat gördüklerini açık, ayrıntılı raporlara dönüştürmek zaman ve deneyim gerektirir. Bu çalışma, gelişmiş yapay zeka sistemlerini bu yazımda destekleyecek şekilde eğitmek için tasarlanmış, özenle oluşturulmuş gerçek bronkoskopi görüntüleri ve raporlarından oluşan yeni bir koleksiyonu tanıtıyor. Hastalar için bu, bir gün daha hızlı, daha tutarlı raporlar ve önemli ayrıntıların gözden kaçma olasılığının azalması anlamına gelebilir.
Akciğerlerin İçine Bakmanın Önemi
Bronkoskopi, ince bir tüpün ucundaki kamera ile soluk borusu ve akciğerlerin dallanmış tüplerinin incelendiği bir işlemdir. Enflamasyon, enfeksiyon, tümörler veya kanama gibi sorunların tespit edilmesine yardımcı olur ve yabancı cisim çıkarma veya hava yollarını açık tutmak için küçük destekler yerleştirme gibi tedavilere rehberlik edebilir. İşlem sonrasında doktor, görülenleri resmi bir raporda tanımlamak zorundadır; bu rapor hastanın tıbbi kaydının bir parçası olur ve tedavi kararlarını yönlendirir. Bu raporları yazmak ayrıntılı ve tekrara dayalı bir iştir ve büyük ölçüde doktorun eğitimi ile hafızasına bağlıdır.
Neden Mevcut Veriler Yeterli Değildi
Son yıllarda görüntüleri ve metni birlikte işleyebilen güçlü yapay zeka modelleri tıbbi taramaları okumada ve rapor taslakları hazırlamada ilerleme kaydetti. Ancak bronkoskopi için bu tür sistemleri eğitmekte kullanılan mevcut veri dar ve eksik kaldı. Önceki veri kümeleri genellikle yalnızca tümör tespiti veya kameranın pozisyonunun işaretlenmesi gibi birkaç görevi kapsıyordu; doktorların rutin olarak tanımladığı mukus, hafif kanama veya şişlik gibi günlük bulgular çoğu zaman göz ardı edildi. Bazı koleksiyonlar özel, küçük veya yalnızca basit evet-hayır kararlarına odaklıydı; bu da kameranın gördüklerini zengin, insan benzeri açıklamalarla yazması gereken bir yapay zeka için yetersiz öğretmenler anlamına geliyordu.
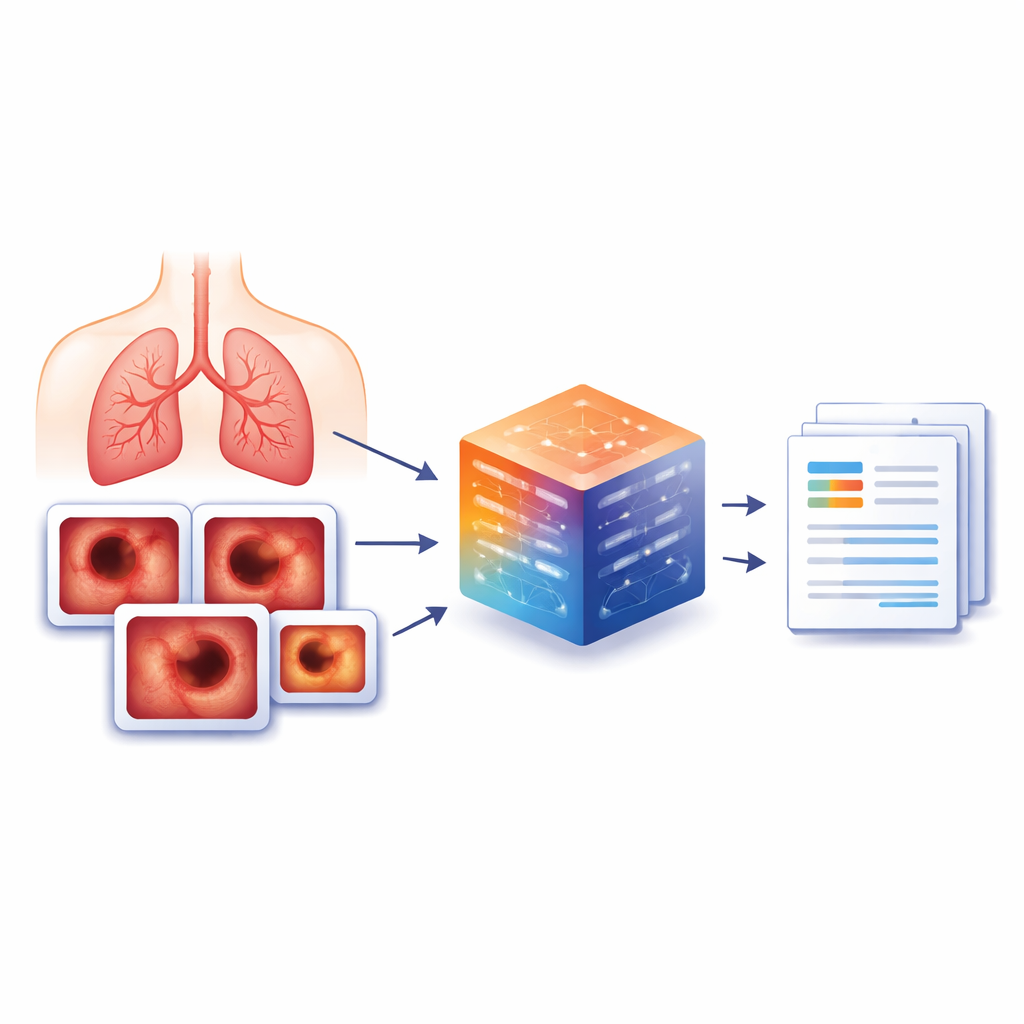
Daha Zengin Bir Görsel Kütüphane Oluşturmak
Bu boşluğu kapatmak için yazarlar, Çin’deki büyük bir hastanede yapılan gerçek prosedürlerden oluşturulmuş yeni bir bronkoskopi muayene raporu veri kümesi olan BERD’i oluşturdu. 2022–2023 yılları arasında yapılan 8.477 bronkoskopiden 3.692 temsil edici hasta vakası ve doktorların özellikle bilgi verici olarak işaretlediği 6.330 anahtar görüntü seçildi. Her görüntü için eğitimli klinisyenler, görüntüde görülen tümörler, şişlikler, birikintiler veya normal doku gibi görünenleri kesin yazılı açıklamalarla ilişkilendirdi. Bir görüntüde sorun yoksa verinin tutarlı kalması için basit bir standart ifade olan “Normaldir” kullanıldı. Kişisel bilgiler kaldırıldı ve özgün Çince raporlar gizliliği korumak amacıyla yerel olarak çalıştırılan bir dil modeliyle İngilizceye çevrildi.
Uzmanlar ve Yapay Zeka Nasıl Birlikte Çalıştı
Basit açıklamaların ötesinde, ekip her görüntünün “tümör”, “konjesyon” veya “ödem” gibi bir veya daha fazla tıbbi kategoriyle etiketlenmesini de istedi; böylece yapay zeka modelleri hem etiketlemeyi hem de bulguları tanımlamayı öğrenebilsin. Bunu verimli yapmak için kıdemli bronkoskopi uzmanları önce tıbbi yönergelere dayalı ayrıntılı bir kategori listesi tanımladı. Yerel olarak dağıtılmış bir dil modeli daha sonra metin altyazılarını tarayarak hangi kategorilerin her görüntüye uygulanabileceğini önerdi. İnsan uzmanlar bu önerileri dikkatle kontrol edip düzeltti ve tıbbi kalite üzerinde nihai kontrolü ellerinde tuttu. Sonuç, her görüntünün net bir açıklama, anatomik konum ve uzman onaylı etiketlerle ilişkilendirildiği; araştırmacıların doğrudan kullanabileceği basit dosyalar halinde düzenlenmiş ince şekilde açıklanmış bir kaynaktır.
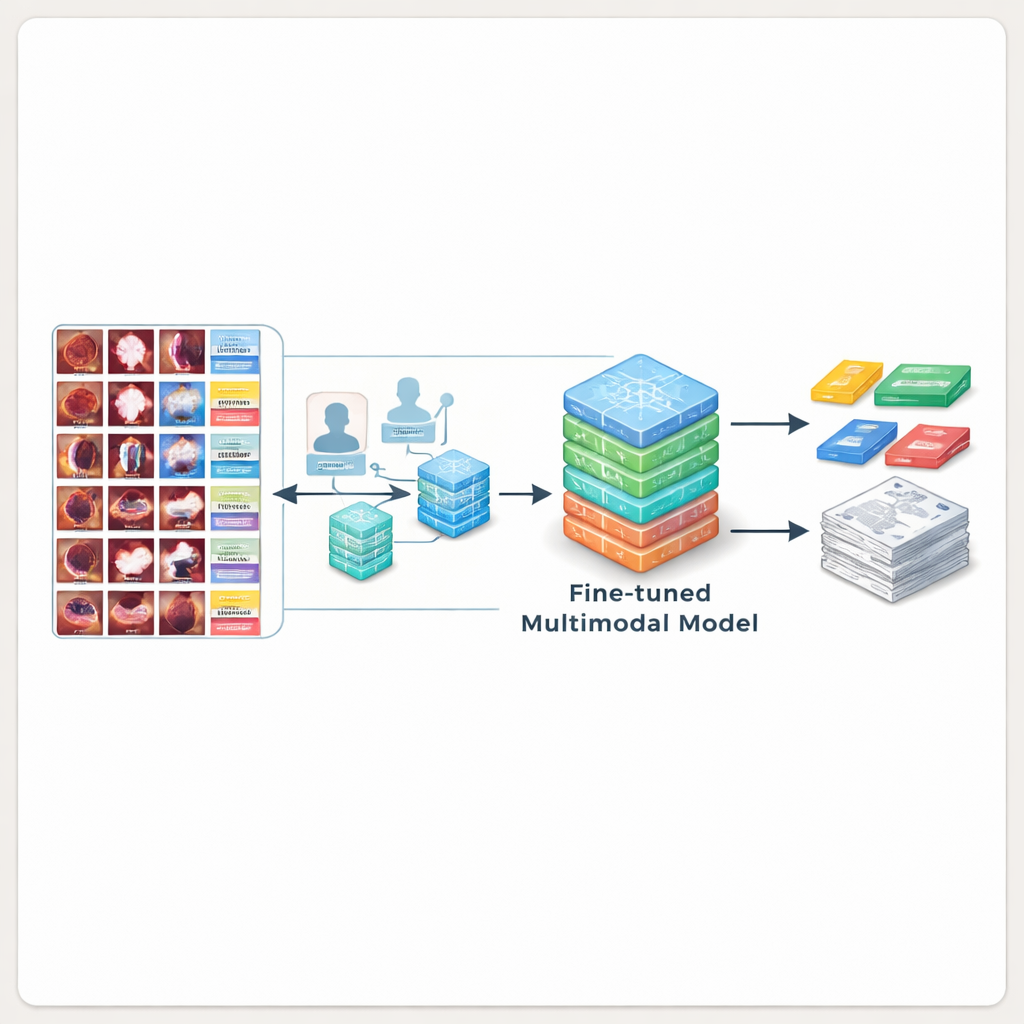
Yapay Zekaya Daha İyi Rapor Yazmayı Öğretmek
BERD’in gerçekten yararlı olduğunu göstermek için araştırmacılar bunu birkaç önde gelen çok modlu yapay zeka modelini eğitmekte kullandı. Önce bronkoskopi görüntülerini daha önce hiç görmemiş genel amaçlı ve tıbbi yapay zeka sistemleri test edildi. Bu modeller sık sık gördüklerini yanlış anladı, tümörleri kaçırdı veya ayrıntılar uydurdu ve uzmanların yazdığı metinlerle karşılaştırıldığında düşük puan aldı. Ekip ardından açık kaynak modelleri BERD görüntüleri ve altyazıları üzerinde ince ayardan geçirdi. Bu ek eğitimden sonra en iyi model, uzman ifadelerine çok daha yakın açıklamalar üretti ve klinisyenler tarafından %80’den fazla bir oranla kabul edilebilir bulundu — yani yapay zeka tarafından üretilen metin çoğu durumda gerçek bir rapora çok az düzenlemeyle doğrudan eklenebiliyordu.
Gelecekteki Bakım İçin Anlamı
Açıkça söylemek gerekirse, bu çalışma yapay zeka sistemlerinin bronkoskopi raporlamasında güvenilir yardımcılar haline gelmeleri için ihtiyaç duyduğu eksik “eğitim kütüphanesini” sağlıyor. Veriler tek bir hastaneden geliyor ve bazı sayı detayları modellerin yanıltmaması için kasıtlı olarak çıkarılmış olsa da, veri kümesi kamuya açık, iyi belgelenmiş ve bu alan için yeni bir standart belirleyecek kadar büyük. Araştırmacılar BERD üzerine inşa ettikçe, hastalar nihayetinde daha hızlı ve daha tutarlı bronkoskopi raporlarından fayda sağlayabilir; bu da doktorların kağıt işinden çok karar ve tedaviye odaklanması için daha fazla zaman sağlayacaktır.
Atıf: Luo, X., Huang, X., Liang, X. et al. Towards Automated Reporting: A Bronchoscopy Report Dataset for Enhancing Multimodality Large Language Models. Sci Data 13, 339 (2026). https://doi.org/10.1038/s41597-026-06692-8
Anahtar kelimeler: bronkoskopi, tıbbi görüntüleme, klinik raporlar, çok modlu yapay zeka, tıbbi veri kümeleri