Clear Sky Science · tr
Biyomedikal Veri Manifestosu: Yapay Zeka/ML için şeffaflığı artıran hafif veri dokümantasyonu eşlemesi
Sağlığınız İçin Daha Akıllı Veri Notları Neden Önemli
Hastaneler ve araştırmacılar hastalığı öngörmek ve tedaviyi yönlendirmek için yapay zekayı hızla kullanmaya çalışırken, bu araçlara veri sağlayan bilginin kalitesi sessizce kimin yarar sağladığını—ve kimin geride kalabileceğini—belirler. Bu makale, biyomedikal veri kümeleri için “kutunun etiketini” pratik bir şekilde koymayı tanıtıyor; böylece yapay sistemler inşa eden herkes verinin nereden geldiğini, kimi temsil ettiğini ve nasıl—ve nasıl olmaması gerektiğini—hızla görebilir. Bu tür dokümantasyonu kolaylaştırarak yazarlar, tıbbi yapay zekayı daha adil, daha güvenli ve güvenmesi daha kolay hâle getirmeyi hedefliyor.
Tıbbi Verilerin İçindeki Gizli Öyküler
Çoğu büyük biyomedikal veri kümesi—laboratuvar sonuçları, görüntüler veya tedavi sonuçları koleksiyonları—hiçbir zaman yapay zeka göz önünde bulundurularak oluşturulmamıştır. Genellikle verinin nasıl toplandığına, hangi hastaların dahil edildiğine veya zaman içinde nelerin değiştiğine dair net kayıtlar eksiktir. Bu eksik ayrıntılar, belirli grupların az temsil edilmesi veya anahtar bilgilerin tutarsız kaydedilmesi gibi önyargıları gizleyebilir. Bu tür veriler makine öğrenmesi sistemlerini eğitmek için kullanıldığında, ortaya çıkan araçlar bazı hastalar için iyi çalışırken diğerleri için kötü performans göstererek mevcut bakım eşitsizliklerini pekiştirebilir. Yazarlar, algoritmalar uygulanmadan önce bu riskleri ortaya çıkarmak ve yönetmek için daha iyi, standartlaştırılmış dokümantasyonun gerekli olduğunu savunuyor.
En İyi Fikirleri Tek Bir Basit Rehberde Birleştirmek
AI topluluğunda halihazırda Datasheets for Datasets, Data Cards ve HealthSheets gibi birkaç veri “bilgi formu” yaklaşımı mevcut. Her biri bir veri kümesinin amacı, içeriği, toplama yöntemleri ve sınırları hakkında yapılandırılmış sorular sunar. Ancak bunlar çoğunlukla bilgisayar bilimciler tarafından AI'ya özgü veri kümeleri için tasarlanmıştır ve yoğun çalışan biyomedikal araştırmacıların doldurması için uzun ve zor olabilir. Yeniden tekerleği icat etmemek için ekip önce dört yaygın atıf yapılan şablondan alanları eşledi ve uyumlaştırdı, en önemli kavramları yakalayan aynı zamanda tekrarları kaldıran 136 soruluk konsolide bir liste oluşturdu. Ardından bu listeyi yedi sezgisel kategoriye gruplanmış 100 alana indirgeyerek temel bilgilerden verinin kullanımına, etik ve yasal kısıtlamalar ile etiketlerin nasıl oluşturulduğu gibi konulara kadar uzanan bir yapı sundular.
Veriyi Kullanan ve Oluşturan İnsanları Dinlemek
Sonrasında araştırmacılar gerçek dünya biyomedikal paydaşlarına—klinikler, laboratuvar bilim insanları, veri yöneticileri ve hesaplamalı uzmanlar dahil—her dokümantasyon alanının işlerinde ne kadar gerekli olduğunu derecelendirmelerini istediler. Çok merkezli bir kanser araştırma ağından yirmi üç katılımcı ankete cevap verdi. Ekip, yanıt verenleri veri toplama sürecine daha yakın olanlar ile esasen veriyi yöneten, düzenleyen veya analiz edenler olmak üzere iki geniş “persona”ya ayırdı. Bu, önceliklerde belirgin farklılıklar ortaya koydu. Örneğin her iki grup da bir veri kümesinin en son ne zaman güncellendiğini ve tekrar ne zaman değişebileceğini bilmeyi yüksek derecede değerli buldu. Ancak yalnızca veri yöneticileri ve hesaplamalı uzmanlar etiketlerin nasıl atandığı veya gelecekteki güncellemelerin nasıl olacağına dair ayrıntıları güçlü bir şekilde önceliklendirirken, klinisyenler ve laboratuvar bilimcileri verinin amaçlanan ve uygun olmayan kullanımları üzerinde daha fazla vurgu yaptı.
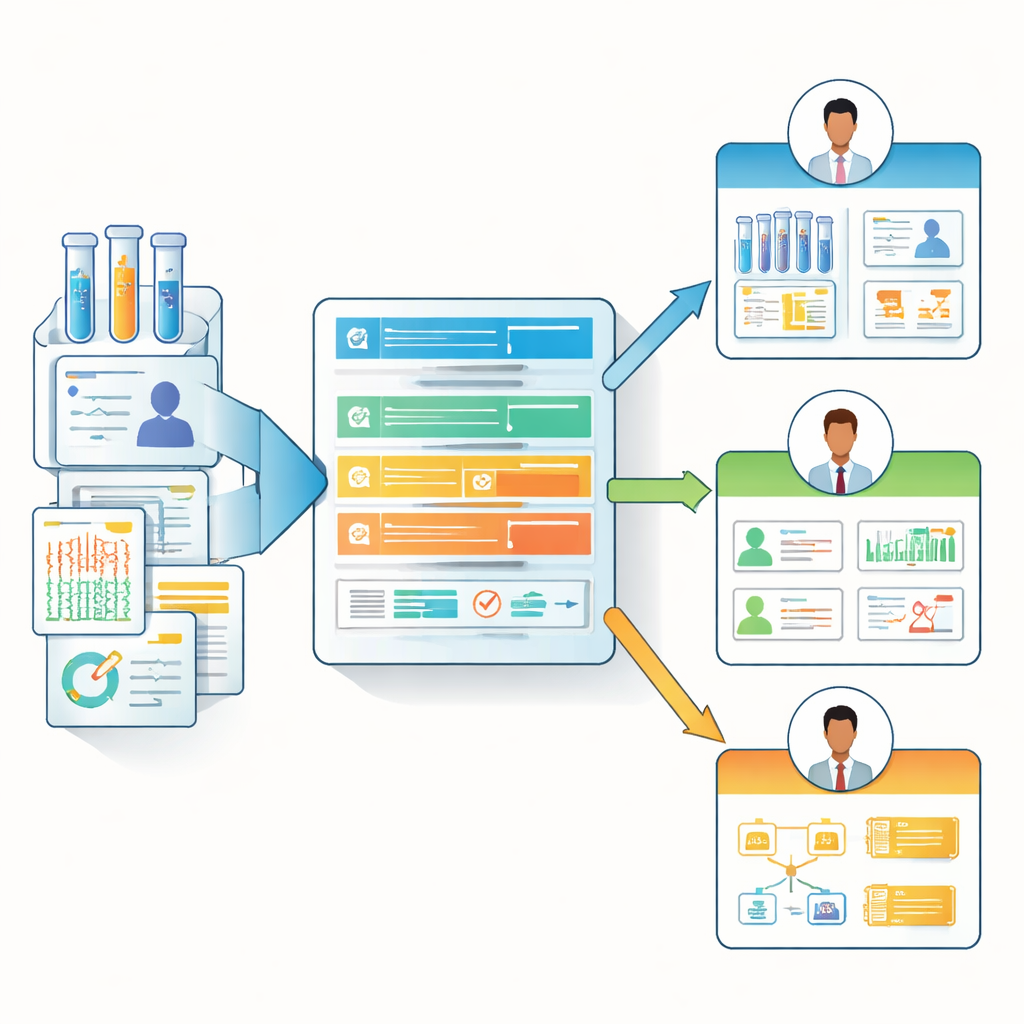
Herkese Uyan Tek Modelden Role Duyarlı Veri Notlarına
Bu anket içgörülerine dayanarak yazarlar, farklı rollere uyum sağlayan hafif, web tabanlı bir dokümantasyon şablonu olan “Biyomedikal Veri Manifestosu”nu tasarladı. Her katkı sahibini devasa bir kontrol listesini doldurmaya zorlamak yerine, manifesto çekirdek sorular ve isteğe bağlı, daha ayrıntılı sorulardan oluşan bir hiyerarşi kullanır. Her persona için en uygun alanları ön plana çıkarabilir—örneğin analistler için veri soy ağacı ve güncelleme ayrıntılarını görünür kılarken, ön saflardaki araştırmacılar ve klinisyenler için klinik bağlam ve kısıtlamaları vurgular. Ekip, kullanıma hazır bir form (örneğin Microsoft Forms'ta), bir HTML görüntü şablonu ve BioDataManifest adlı açık kaynak bir R paketi sağlıyor. Bu yazılım, anket yanıtlarını otomatik olarak net manifesto sayfalarına dönüştürebilir ve mevcut veri kümeleri için kısmi manifestolar oluşturmak üzere Genomic Data Commons ve dbGaP gibi büyük halka açık depozitlerden bilgi çekebilir.
Geleceğin Tıbbi Yapay Zekası İçin Anlamı
Sonuç olarak, Biyomedikal Veri Manifestosu, biyomedikal veri kümelerinin “ince yazısını” oluşturmayı, paylaşmayı ve anlamayı kolaylaştıran pratik bir araçtır. Veriye dair dokümantasyon ile belirli AI modellerine dair dokümantasyonu ayırarak ve gösterilenleri farklı kullanıcı rollerine göre uyarlayarak, çerçeve araştırmacıların yükünü azaltırken son kullanıcıların bir veri kümesinin belirli bir amaç için uygun olup olmadığını değerlendirmek için ihtiyaç duyduğu bağlamı sağlar. Günlük terimlerle, opak tıbbi veri kümelerini açıkça etiketlenmiş paketlere dönüştürür; bu da AI geliştiricilerin hasta sonuçlarını etkilemeden önce sınırlamaları ve olası önyargıları fark etmelerine yardımcı olur. Yaygın şekilde benimsenirse, bu tür role duyarlı, yeniden kullanılabilir dokümantasyon biyomedikal yapay zekayı daha şeffaf, tekrarlanabilir ve adil hale getirebilir.
Atıf: Bottomly, D., Suciu, C.G., Cordier, B. et al. Biomedical Data Manifest: A lightweight data documentation mapping to increase transparency for AI/ML. Sci Data 13, 414 (2026). https://doi.org/10.1038/s41597-026-06670-0
Anahtar kelimeler: biyomedikal veri dokümantasyonu, tıpta sorumlu yapay zeka, veri seti şeffaflığı, makine öğrenmesi önyargısı, veri yönetişimi