Clear Sky Science · tr
Topluluk Sorumluluğu ve Katılımı ile Proteomik Veri Mezarlarının Önlenmesi
Tıbbi verilerinizin dijital bir mezarlığa dönüşmemesi neden önemli
Modern tıp, hücrelerimizde çalışan binlerce proteini tanımlayan devasa veri kümelerine giderek daha fazla dayanıyor. Bu dosyalar genellikle diğer araştırmacıların sonuçları iki kez kontrol etmesine veya yeni sorular sormasına olanak tanıyacak şekilde çevrimiçi olarak açıkça paylaşılıyor. Ancak veriler kafa karıştırıcı formatlarda yayınlanırsa, önemli ayrıntılar eksikse veya tescilli yazılıma bağlıysa, bunlar “veri mezarları”na dönüşüyor: herkesin görebildiği ama pratikte kullanışsız olan kaynaklar. Bu makale, bir üniversite dersinin öğrencileri veri dedektifine çevirerek bu gizli sorunu nasıl ortaya çıkardığını gösteriyor ve paylaşılan verilerin gerçekten yeniden kullanılabilir hâle gelmesi için basit düzeltmeler öneriyor.
Gerçek çalışmaları yeniden yaparak bilimi öğrenmek
Helsinki Üniversitesi’nde kütle spektrometrisi proteomik dersi alan lisansüstü öğrencilerden iddialı bir şey yapmaları istendi: büyük bir arşivden gerçek, herkese açık protein veri setleri seçip yayımlanmış bulguları yeniden üretmeyi denemek. Küçük ekipler halinde çalışan öğrenciler, dünya çapındaki birçok laboratuvardan kütle spektrometrisi sonuçlarını barındıran ProteomeXchange ağına ait altı projeyi indirdiler. R programlama dilinde paylaşılan bir analiz boru hattını kullanarak, öğrenciler orijinal araştırmacıların izlediği geniş adımları takip ettiler: proteinleri tanımlamak, bolluklarını ölçmek, veriyi temizlemek ve hastalık ile sağlıklı doku gibi koşullar arasında hangi proteinlerin değiştiğini test etmek.
Büyük vaatler, eksik talimatlar
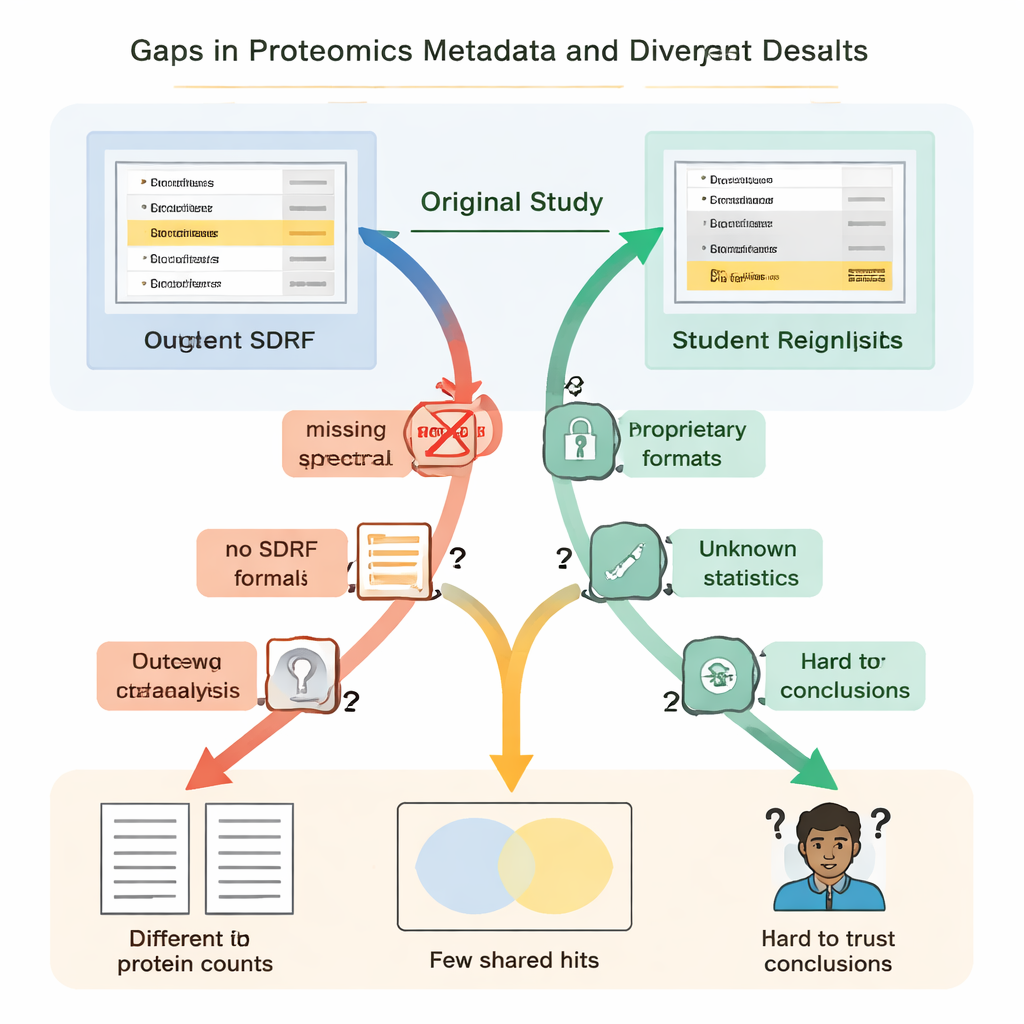
Öğrenciler hızla fark ettiler ki “açık” her zaman “yeniden kullanılabilir” demek değildi. Her durumda temel talimatlar eksik ya da bulunması zordu. Örnekler ile veri dosyaları arasındaki kilit bağlantılar basit, makine tarafından okunabilir bir formatta tanımlanmamıştı; bu yüzden ekiplerin ham dosyaların hangi biyolojik grupla eşleştiğini anlamak için makaleleri okumaları ve dosya adlarını çözümlemeleri gerekti. Yanlış pozitiflerin nasıl kontrol edildiğine dair ayrıntılar—özellikle özel “decoy” protein dizilerinin kullanımı gibi—yer almıyordu, bu da rapor edilen protein listelerinin ne kadar güvenilir olduğuna titizlikle karar vermeyi imkânsız kıldı. Birkaç projede ana sonuçlar tescilli dosya formatlarının içinde kilitliydi veya öğrencilerin erişemediği ticari yazılımlara bağımlıydı; bu durum, öğrencileri analizin büyük bölümlerini baştan yapmaya zorladı.
Küçük boşluklar büyük farklar yarattığında
Bu eksik parçalar sadece rahatsız edici değildi; dramatik şekilde farklı bilimsel sonuçlara yol açtılar. Bir böbrek hastalığı çalışmasında orijinal yazarlar yaklaşık beş bin protein bildirmişken, öğrencilerin yeniden analizi—açık bir araç ve ev yapımı spektral kütüphane kullanarak—on üç binden fazla protein buldu. Orijinal makalede özellikle önemli olduğu vurgulanan bir protein, temel tanımlama dosyasında ikna edici biçimde görünmüyordu ve öğrencilerin iş akışında hiç tespit edilmedi. Başka bir durumda, orijinal çalışma koşullar arasında değiştiği belirtilen 108 proteini listelerken, öğrenciler aynı ham verilerden yola çıkıp orijinal istatistiklerin nasıl yapıldığı hakkında eksik bilgiyle güvenle yalnızca 11 proteini işaretleyebildiler. Yüklenen dosyalarda biyolojik tekrarların eksikliği, doğru istatistiksel testlerin uygulanmasını basitçe imkânsız kıldı.
Gerçekten “yeniden kullanılabilir” bir veri setinde neler olmalı
Bu altı vaka çalışmasından belirgin bir desen çıktı: yeniden üretilebilirliğin önündeki ana engeller kütle spektrometresi makineleri değil, sonuçların paketlenme ve paylaşılma biçimiydi. Yazarlar, her proteomik veri setinin minimum bir yeniden-analiz paketi ile birlikte gelmesi gerektiğini savunuyor. Buna ham veriler ve açık, topluluk-standardı sonuç formatları; her örneği deneysel koşullarına bağlayan standartlaştırılmış bir tablo; temel kalite kontrol özetleri; aramayı tekrarlamak için gereken herhangi bir spektral kütüphane veya protein dizi dosyası; ve tercihen sürümlenmiş yazılım konteynerleriyle saklanan eksiksiz analiz parametreleri ve kodu dahildir. Depolar, dergiler ve hakemler, göndericileri bu paketi baştan sağlamaya yönlendirerek veya zorunlu kılarak yardımcı olabilir, böylece başkalarının çalışma akışını dağınık ipuçlarından yeniden inşa etmek zorunda kalmasının önüne geçilir.
Sistemi düzeltirken bilim insanlarını eğitmek
Dersin kendisi çift amaçlı bir işlev gördü. Öğrenciler için bu, karmaşık proteomik yöntemleri, istatistikleri ve kodlamayı uygulamalı olarak öğrenmenin yanı sıra belgelendirme eksik olduğunda yayımlanmış sonuçların ne kadar kırılgan olabileceğini göstermesi açısından faydalı oldu. Daha geniş toplum içinse öğrencilerin yaşadığı zorluklar mevcut veri paylaşım uygulamalarının bir stres testini sağladı ve meta verilerin ve analiz kayıtlarının nerede eksik kaldığını net olarak ortaya koydu. Yazarlar, benzer derslerin başka yerlerde de yürütülebileceğini, sınıfları sürekli daha açık ve şeffaf veri talep eden kalite kontrol motorlarına dönüştürebileceğini öneriyor.
Veri mezarlarından yaşayan kaynaklara
Düz bir ifadeyle makale, kamu depolarında şu anda duran birçok protein veri setinin dijital mezarlıklara dönüşme riski taşıdığını—yani sonuçları güvenilir biçimde doğrulanamayan veya genişletilemeyen pahalı deneyler olduğunu—sonuçlandırıyor. Buna rağmen çözüm görece basit: meta verileri, açık formatları ve paylaşılabilir kodu deneyin ayrılmaz parçaları olarak ele almak, sonradan eklenen ayrıntılar olarak görmek yerine. Araştırmacılar, hakemler ve depolar birleşik şekilde proteomik veriler paylaşıldığında basit, iyi belgelenmiş bir paket talep eder veya zorunlu kılarsa, bu veri setleri "yaşar" kalabilir: yeniden analiz edilmeye, yeni çalışmalarla birleştirilmeye ve biyomedikal keşiflerin kanıtını güçlendirmeye hazır hale gelirler.
Atıf: Vadadokhau, U., Soliman, M., Castillon, L. et al. Preventing Proteomics Data Tombs Through Collective Responsibility and Community Engagement. Sci Data 13, 287 (2026). https://doi.org/10.1038/s41597-026-06614-8
Anahtar kelimeler: proteomik, veri yinelenebilirliği, açık bilim, kütle spektrometrisi, araştırma veri paylaşımı