Clear Sky Science · tr
Etiketlenmiş bir klinik çalışmaları korpusunu kullanarak dönüştürücü tabanlı ilişki çıkarımı ve kavram normalizasyonu
Doktorların Doğru Hastaları Daha Hızlı Bulmasına Yardım Etmek
Her klinik çalışma, uzun bir tıbbi koşullar, tedaviler ve zaman dilimleri listesine uyan hastaların bulunmasına dayanır. Bugün doktorlar sıklıkla elektronik sağlık kayıtlarını ve çalışma tanımlarını elle okumak zorunda kalıyor; bu yavaş ve hata yapmaya açık bir süreç. Bu makale, büyük ve dikkatle kontrol edilmiş bir İspanyol klinik çalışma metinleri koleksiyonunu sunar ve modern yapay zekanın bu yapılandırılmamış dili nasıl düzenli verilere dönüştürebileceğini gösterir; bu da daha hızlı, daha adil ve daha hassas tıbbi araştırmalara zemin hazırlar.
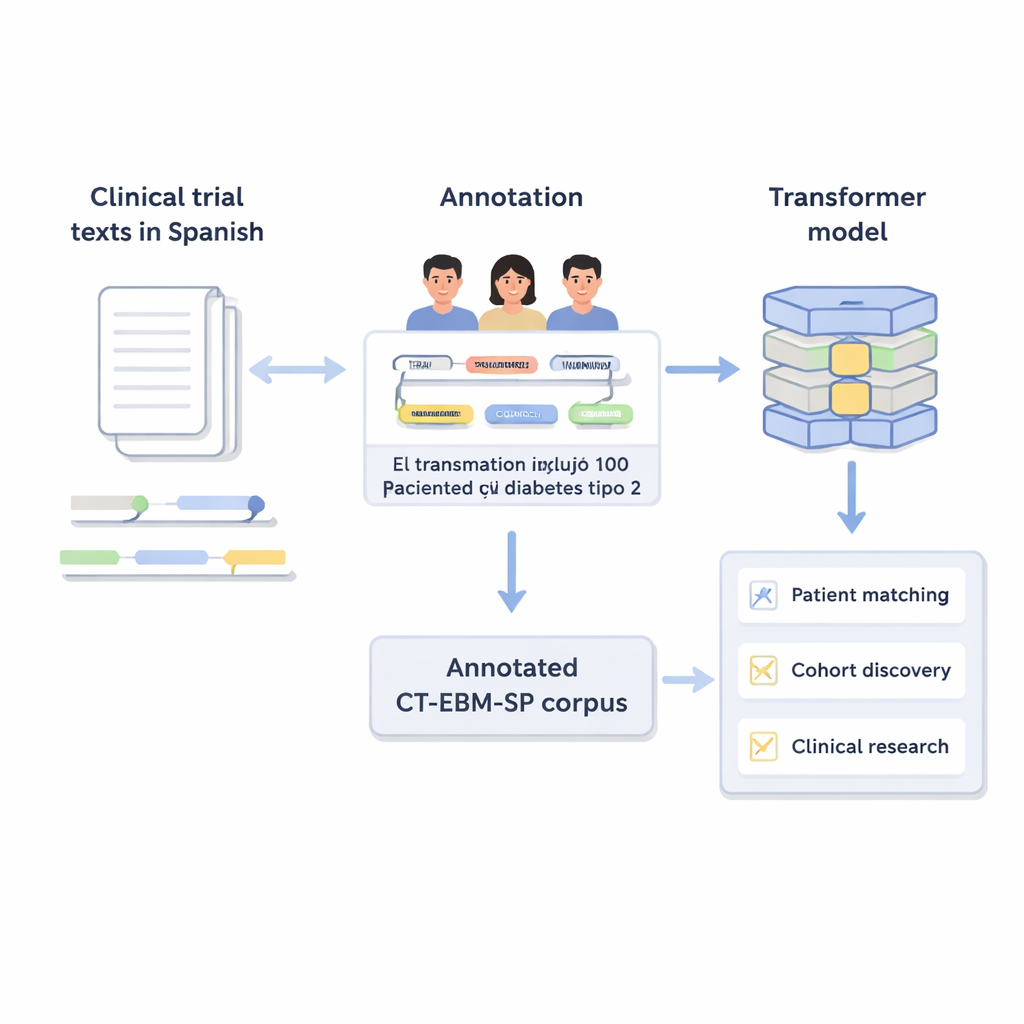
Serbest Metni Düzenli Bilgiye Dönüştürmek
Klinik çalışmalar, kimlerin katılıp katılamayacağını günlük tıbbi dilde açıklar: yaş sınırları, geçmiş hastalıklar, laboratuvar sonuçları ve denenmiş tedaviler. Bilgisayarlar bu tür serbest metinle zorlanır. Yazarlar, yaklaşık 300.000 kelime içeren 1.200 İspanyolca klinik çalışma metninden oluşan CT‑EBM‑SP korpusunun 3. sürümünü oluşturdular. İnsan uzmanlar bu metinleri gözden geçirip hastalıklar, ilaçlar, test sonuçları ve zaman ifadeleri gibi 23 tür tıbbi varlığı işaretlediler ve aynı zamanda “öyküsü yok” gibi olumsuzluk ve belirsizlik işaretlerini not ettiler. Ayrıca bir olayın geçmişte mi yoksa gelecekte mi olduğu ve hastaya mı yoksa aile üyesine mi ait olduğu gibi ayrıntıları yakalayan 11 niteliği de etiketlediler.
Tıbbi Terimleri Aynı Dilde Konuşturmak
Tıptaki temel zorluklardan biri, aynı kavramın birçok farklı şekilde yazılabilmesidir. Bunu çözmek için ekip, işaretlenen varlıkların çoğunu çokdilli büyük bir tıbbi sözlük olan Birleşik Tıbbi Dil Sistemi (UMLS) içindeki standart kodlara bağladı. Kavram normalizasyonu olarak adlandırılan bu adım, farklı yazımların veya ifadelerin aynı tekil tanımlayıcıya işaret etmesini sağlar. Örneğin, “25‑hidroksivitamin D”nin birkaç varyantı tek bir UMLS kavramına eşlenmiştir. Toplamda korpus 87.000'den fazla varlık ve 68.000'den fazla ilişki içerir ve varlıkların yaklaşık %82'si başarıyla normalizasyonu yapılmıştır. İki uzman bu bağlantıları bağımsız olarak kontrol etti ve çok yüksek bir uyum sağlandı; bu da açıklamaların güvenilir olduğunu gösterir.
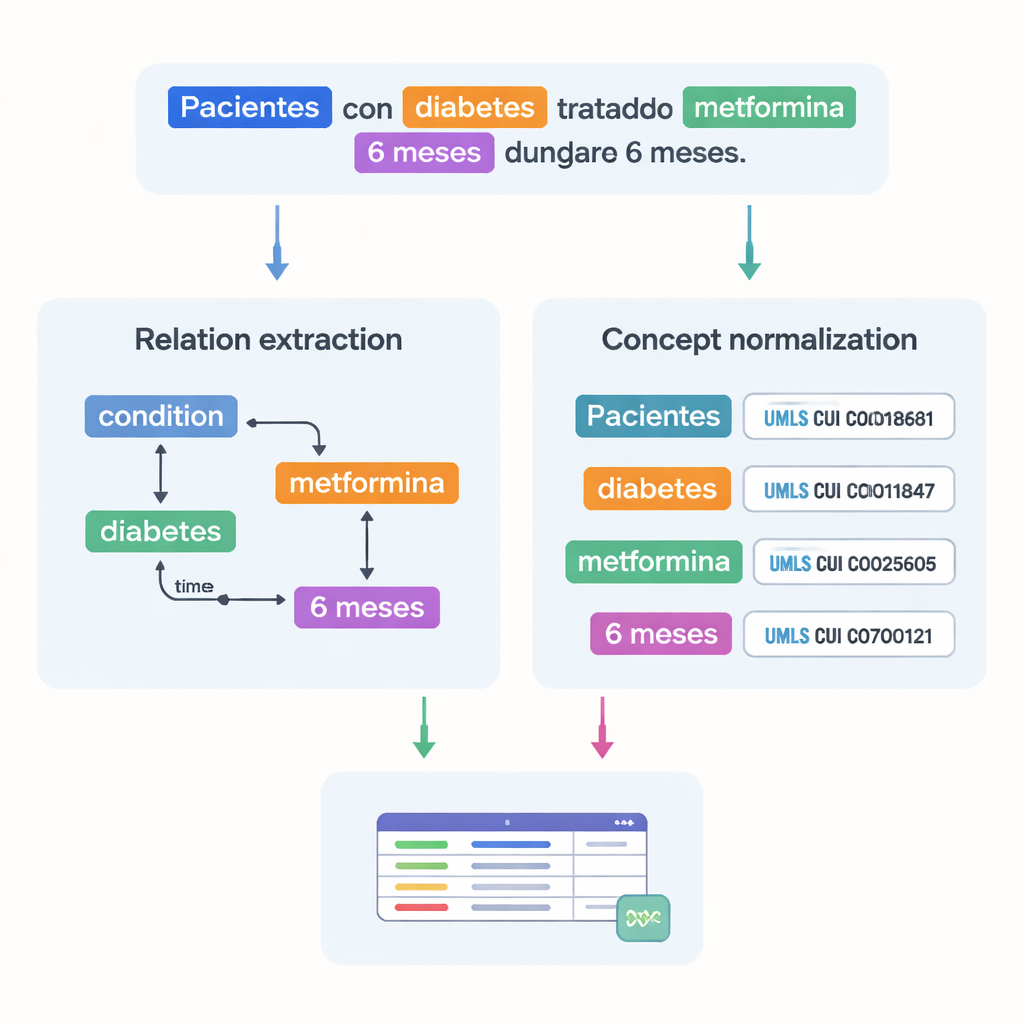
Tıbbi Gerçeklerin Birbiriyle Nasıl İlişkilendiğini Yakalamak
Tıbbi terimleri listelemenin ötesinde, veri seti bunların nasıl bağlandığını kaydeder. Yazarlar, hangi dozun hangi ilaca ait olduğu, bir tedavinin ne kadar sürdüğü veya bir hastanın hangi durumu yaşadığı gibi çalışmalarda önemli olan kalıpları yakalamak için 18 tür ilişki tasarladı. Zaman ilişkileri bir olayın başka bir olaydan önce mi sonra mı olduğunu gösterir ve diğer bağlantılar bir hastalığın vücudun nerede meydana geldiğini ya da bir ifadenin olumsuzluk veya varsayım ifade edip etmediğini işaretler. Bu ilişkiler bir araya geldiğinde, bilgisayarların izole kelimeleri tanımaktan ziyade bir hastanın durumunun—hasta kimdir, hangi durumu vardır, hangi tedaviyi almaktadır ve hangi zamanlamayla—grafiklerini kurmasına olanak tanır.
Modern Yapay Zeka Modellerini Eğitmek ve Test Etmek
Korpusun pratik olarak işe yarar olduğunu göstermek için yazarlar, BERT ve RoBERTa'nın çokdilli sürümleri de dahil olmak üzere birkaç dönüştürücü tabanlı AI modelini ince ayar yaptılar. Bu modelleri iki görev üzerinde eğittiler: varlıklar arasındaki bağlantıları öğrenen ilişki çıkarımı ve metni UMLS kodlarına eşleyen tıbbi kavram normalizasyonu. İlişki çıkarımında en iyi model yaklaşık 0,88 F1 skoruna ulaştı; bu, çoğu ilişkiyi nispeten az hata ile doğru şekilde tanıdığı anlamına gelir. Kavram normalizasyonunda, ek eğitim olmaksızın kullanılan SapBERT adlı çokdilli bir model doğru kavramı ilk denemede neredeyse %90 oranında tahmin etti. Bu sonuçlar, iyi etiketlenmiş, orta ölçekli veri setlerinin, devasa genel amaçlı dil sistemleri olmadan bile doğru ve verimli modelleri destekleyebileceğini gösterir.
Bu Kaynağın Gelecekteki Bakım İçin Önemi
CT‑EBM‑SP korpusu ve ilgili modeller, İspanyolca klinik çalışma metinlerini otomatik olarak çözümleyebilecek, bunları hasta kayıtlarıyla eşleştirebilecek ve hastanelerde kohort keşfini destekleyebilecek araçlar için bir temel sağlar. Veriler uluslararası tıbbi standartlarla uyumlu ve uzmanlar tarafından dikkatle kontrol edildiği için, dijital araçları daha az olan diğer diller için benzer kaynakların geliştirilmesine de yardımcı olabilir. Günlük ifadeyle, bu çalışma doğru hastaların doğru çalışmalara daha kolay ve güvenli şekilde teklif edilmesini sağlamayı, tıbbi keşifleri hızlandırmayı ve sağlık çalışanlarının yükünü azaltmayı amaçlıyor.
Atıf: Campillos-Llanos, L., Valverde-Mateos, A., Capllonch-Carrión, A. et al. Transformer-based relation extraction and concept normalization using an annotated clinical trials corpus. Sci Data 13, 280 (2026). https://doi.org/10.1038/s41597-026-06608-6
Anahtar kelimeler: klinik çalışmalar, tıbbi metin madenciliği, İspanyol sağlık hizmetleri, dönüştürücü modeller, kanıta dayalı tıp