Clear Sky Science · tr
Kymata Soto Dil Veri Kümesi: doğal konuşma işleme için elektromanyetoensefalografik bir veri kümesi
Beynin Gerçek Konuşmaları Nasıl İşittiğini Dinlemek
Günlük hayatta söylediğimiz ve duyduğumuz çoğu şey tek kelimeler veya dikkatle okunan cümleler değil, günlük konuşmalardır. Buna rağmen dil üzerine yapılan birçok beyin araştırması yapay görevler kullanmıştır. Kymata Soto Dil Veri Kümesi, insanlardan İngilizce ve Rusça canlı radyo tartışmalarını dinlerken elde edilen zengin, açık beyin kayıtları sağlayarak bunun önünü açıyor ve bilim insanlarına beynimizin doğal konuşmayı nasıl işlediğine dair güçlü yeni bir pencere sunuyor.
Gerçek Konuşmalara Karşı Beyin Yanıtlarının Yeni Bir Kütüphanesi
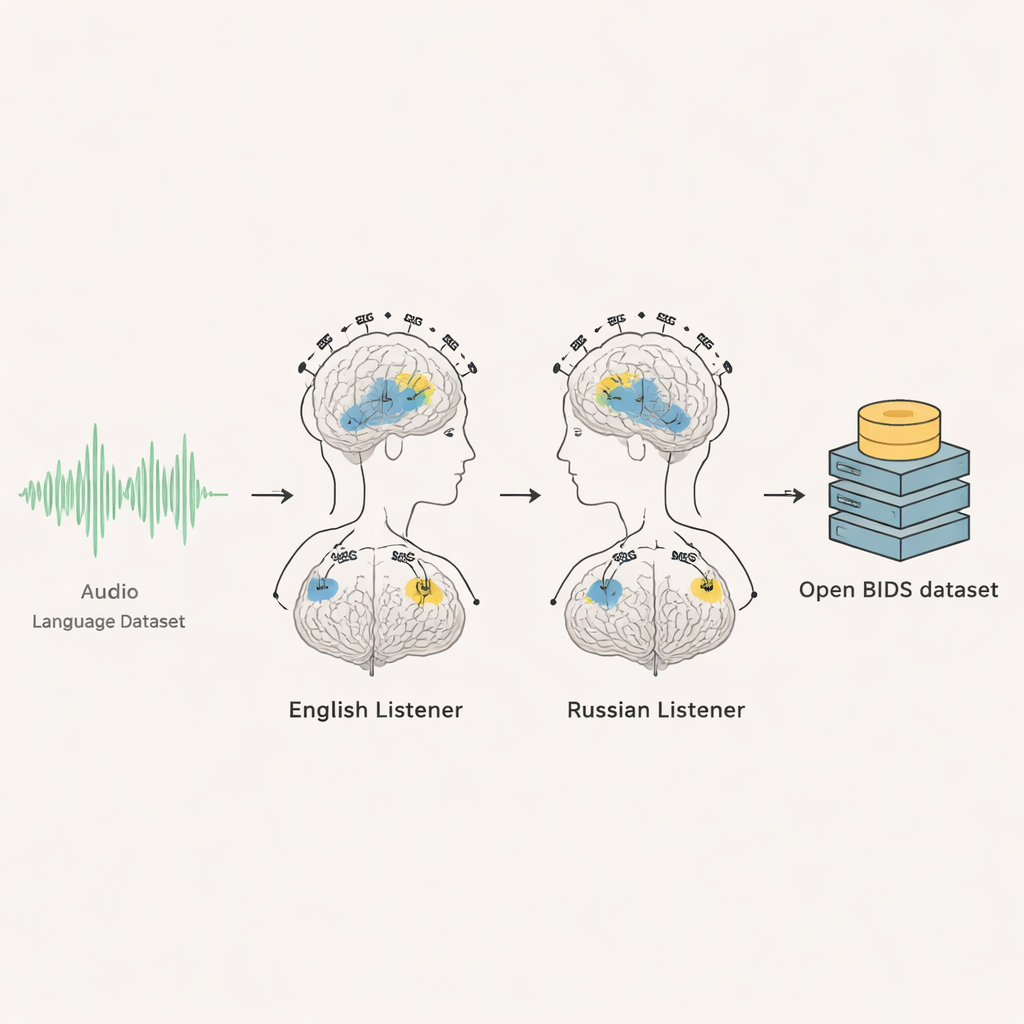
Bu proje, 35 yetişkinden elde edilen iki gelişmiş beyin kayıt yöntemini—elektroensefalografi (EEG) ve magnetoensefalografi (MEG)—bir araya getiriyor: 20 ana dili İngilizce olan ve 15 ana dili Rusça olan katılımcı. Katılımcılar sessizce oturup kendi dillerinde radyo tarzı yaklaşık altı buçuk dakikalık konuşmaları dinlerken, beyin aktiviteleri saniyede bin kez kaydedildi. Her kişi aynı ses kaydını birkaç kez dinledi, bu da araştırmacıların yinelenen kayıtlar üzerinden ortalama alıp arka plandaki gürültüden beynin güvenilir yanıtlarını ayıklamasına olanak verdi. Sonuç, insanların gelişen bir tartışmayı takip ederken beynin her an nasıl tepki verdiğinin detaylı, zamanla kilitlenmiş bir kaydıdır.

Dondurma ve Kahve Hakkında Konuşmalar
Klasik öyküler veya yapay cümleler kullanmak yerine ekip, ilgi çekici ama gündelik konuları seçti: İngilizce dinleyiciler için dondurmanın tarihi ve Rusça dinleyiciler için Kolombiya kahvesinin tarihi. Her iki kayıt da üç konuşmacının (iki erkek ve bir kadın) yer aldığı BBC stüdyo tartışmalarından alındı. Konuşmalar yaklaşık 400 saniyeye düzenlendi ve kulaklıklar aracılığıyla rahat dinleme seviyelerinde sunuldu. Her tekrarın ardından katılımcılar içeriğe dair bir veya iki basit çoktan seçmeli soruyu yanıtladı—amaç onları uyanık tutup hikâyeyi takip etmelerini sağlamak, agresif bir test uygulamak değildi.
Gözleri Meşgul Tutup Zihni Sese Odaklama
Katılımcılar dinlerken ekrandaki ortadaki bir haça baktılar. Etrafında, renklendirilmiş noktalar bulutu rastgelemiş gibi hareket edip değişiyordu. Bu hareketli noktalar iki amaca hizmet etti: insanların bakışlarını sabit tutmaya yardımcı olarak veri kalitesini artırdılar ve diğer araştırmacıların daha sonra analiz edebileceği kontrollü görsel hareket ve renk örüntüleri yarattılar. Önemli olarak, noktalar konuşma içeriğiyle senkronize değildi; dolayısıyla hikâyeyi “görselleştirmiyor” ya da ekstra anlam katmıyordu, ancak seslerle birlikte incelenebilecek tutarlı bir görsel arka plan sağladı.
Ham Beyin Sinyallerinden Kullanıma Hazır Veriye
Araştırmacılar deneyin her bölümünü dikkatle belgelendirdi ve veri kümesini BIDS adı verilen uluslararası bir beyin veri standardına göre düzenledi. Her gönüllü için ham EEG ve MEG kayıtları, sesin başladığı zaman için zaman işaretleri, saniye saniye görsel olaylar ve alıştırma bölümleri bulunuyor. Ekip ayrıca orijinal ses dosyalarını, tam transkriptleri ve her kelimenin hatta her tek konuşma sesinin başladığı kesin zamanlamayı sağlıyor. Kullanıcıların tam olarak kullanılan ses parçalarını otomatik olarak yeniden üretebilmeleri için betikler de dahil edilmiş. İngilizce grubu için kişilerin kimliği gizlenmiş MRI beyin taramaları paylaşılıyor, böylece beyin yanıtları bireysel beyin anatomisine eşlenebiliyor; Rusça grupta ise onay MRI görüntülerinin paylaşılmasına izin vermediği için kullanıcıların standart ortalama beyin şablonlarına güvenmeleri tavsiye ediliyor.
Sinyallerin Mantıklı Olduğunu Kontrol Etme
Verilerin bilimsel olarak güvenilir olduğundan emin olmak için yazarlar, beynin zaman içinde ses şiddetindeki değişimleri nasıl izlediğine odaklanan doğrulama analizleri yürüttüler. Sesi birkaç matematiksel “zaman‑değişken şiddet” betimlemesine dönüştürdular ve ardından beyin yanıtlarının bu şiddet desenleriyle nerede ve ne zaman hizalandığını incelediler. Hem İngilizce hem de Rusça dinleyicilerde beyin benzer zamanlama desenleri gösterdi; bu da önceki çalışmalarda bildirilenlerle tutarlı. Diller arası ve geçmiş çalışmalarla uyum, kayıtların temiz, güvenilir ve başkalarının üzerine inşa etmesi için hazır olduğunun güçlü bir göstergesidir.
Gelecekteki Beyin ve Dil Araştırmaları İçin Neden Önemli
Uzman olmayanlar için temel çıkarım şudur: bu veri kümesi, birçok farklı araştırma ekibinin gerçek, kendiliğinden konuşmanın beyinde nasıl işlendiğini incelemesine olanak tanıyan yeni, ortak bir kaynaktır. Açık, iyi açıklanmış ve iki farklı dilde kaydedilmiş olması; konuşmayı nasıl anladığımıza dair temel sorulardan dil karşılaştırmalarına, hatta beyin aktivitesinden doğrudan konuşma çözümlemeye kadar geniş bir proje yelpazesini destekleyebilir. Kısacası, Kymata Soto Dil Veri Kümesi tek bir soruyu cevaplamaktan ziyade bilim topluluğuna günlük hayatımızı dolduran konuşmaları beynimizin nasıl anlamlandırdığını keşfetmek için yüksek kaliteli, paylaşılmış bir temel sunuyor.
Atıf: Yang, C., Parish, O., Klimovich-Gray, A. et al. Kymata Soto Language Dataset: an electro-magnetoencephalographic dataset for natural speech processing. Sci Data 13, 254 (2026). https://doi.org/10.1038/s41597-026-06579-8
Anahtar kelimeler: beyin ve dil, konuşma algısı, EEG MEG, doğalcı konuşma, açık nörogörüntüleme verisi