Clear Sky Science · tr
Almanya İnsan Genom-Fenotip Arşivi metadata modelinin Avrupa genomik alanındaki anlamsal uyumu
Genom verilerinin paylaşılması neden sadece dosyalardan fazlasını gerektirir
Modern tıp, hastalıkları teşhis etmek ve tedavileri kişiselleştirmek için giderek DNA’yı okumaya dayanıyor. Ancak genomik verinin gerçek gücü, birçok hastane ve ülkeden gelen veriler birleştirilebildiğinde ortaya çıkıyor. Bu yalnızca her veri kümesinin açık, uyumlu bir şekilde tanımlanması ve Avrupa’nın GDPR gibi gizlilik yasalarına titizlikle uyulması durumunda mümkün. Bu makale, Alman İnsan Genom-Fenotip Arşivi’nin (GHGA) değerli verilerin Avrupa genelinde bulunması, anlaşılması ve güvenle paylaşılması için genomik çalışmaları ayrıntılı biçimde “tanımlayan bir sistem” nasıl kurduğunu açıklıyor.
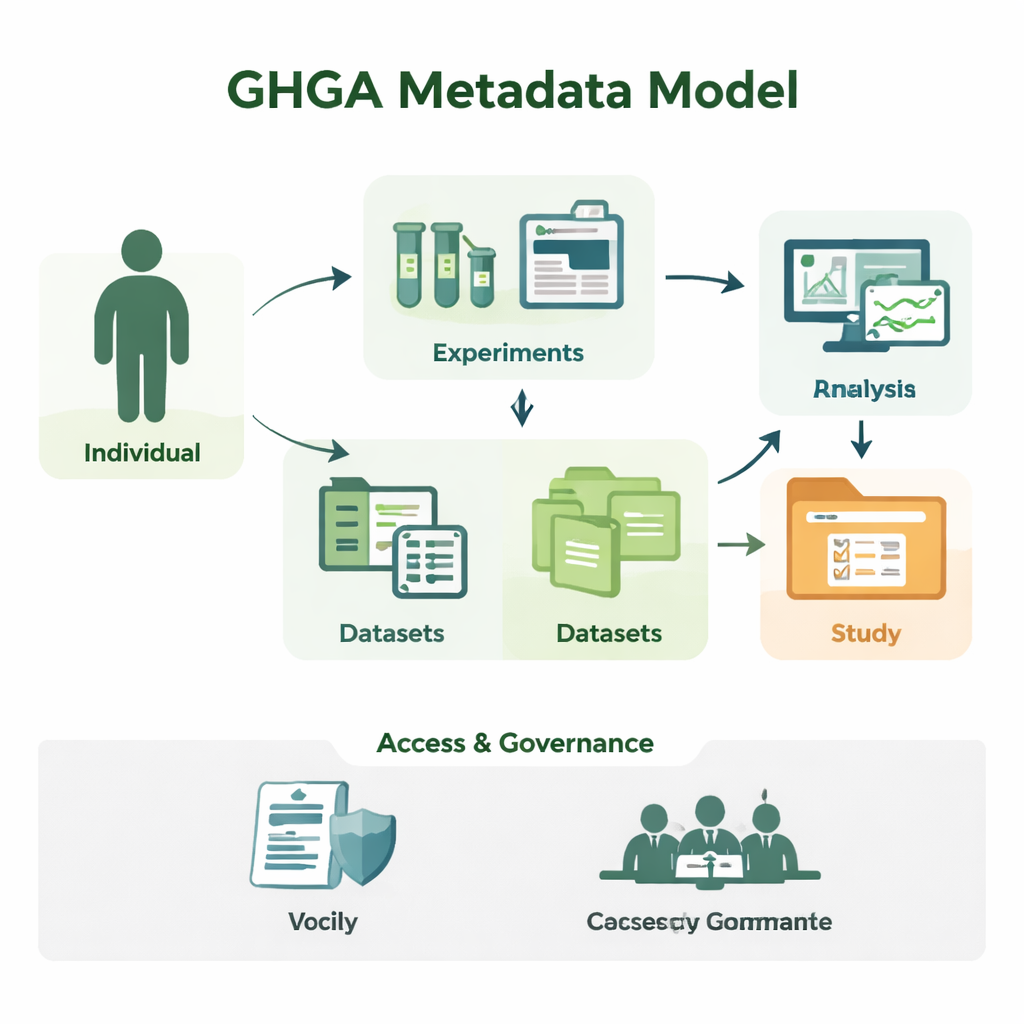
Ham dizilerden anlaşılabilir çalışmalara
Genomik araştırma büyük miktarda dizi verisi üretir, ancak tek başına bir DNA harfleri dosyası anlamsızdır. Araştırmacıların örneğin kimden alındığını, hangi dokunun kullanıldığını, deneyin nasıl yapıldığını ve verinin hangi koşullarda yeniden kullanılabileceğini bilmesi gerekir. GHGA bu çevresel bilgiyi metadata olarak yakalar. Modeli, çalışmaya katılan kişi ("Birey"), alınan örnek, gerçekleştirilen deney ve analiz, oluşturulan veri dosyaları ve bunları bir araya getiren veri setleri ve çalışmalar gibi 16 yapı taşı halinde düzenler. Bilimsel ayrıntıları erişim koşulları gibi idari unsurlardan ayırarak model, gerçek bir laboratuvar ve veri portalının işleyişini yansıtır; ancak bilgisayarların güvenilir şekilde işleyebileceği biçimdedir.
Veriyi kullanışlı tutup kişileri tanımlanamaz kılmak
GHGA hassas insan sağlık verileriyle ilgilendiğinden, ekip modeli bilimsel olarak zengin tutarken verinin arkasındaki herhangi bir kişiyi tanımlamayı kolaylaştırmamak üzere tasarlamak zorunda kaldı. Avrupa GDPR kuralları, adlar çıkarılsa bile makul şekilde bir bireye bağlanabilecek bilgilerin kişisel veri sayılacağını belirtir. Makalede, yaş, posta kodu ve nadir tanılar gibi ayrıntıların birleştirilmesinin kimlikleri ortaya çıkarabileceğini gösteren titiz bir gizlilik analizi anlatılıyor. Buna karşılık GHGA’nın kamu portalı ince ayrıntılı konum verilerinden kaçınıyor, yaşları tam yıllar yerine geniş bantlara ayırıyor ve ayrıntılı tanı kodlarını daha kaba kategorilerde birleştiriyor. Bu sayede araştırmacılar bir veri kümesinin işlerine uygun olup olmadığını görebiliyor, ancak bir kişiyi tekil hale getirmek için gereken çaba gerçekçi olmayan düzeye çıkıyor.
Avrupa genomik ekosistemiyle uyumluluğu kontrol etmek
Gerçekten faydalı olmak için GHGA’nın metadata’sı, daha geniş bir Avrupa genom arşivleri ve araçları ağına uyumlu olmalı. Bu nedenle yazarlar modellerini madde madde dört diğer yaygın çerçeve ile karşılaştırdılar: Avrupa Genom-Fenotip Arşivinin (EGA) iki versiyonu, ISA-tab standardı ve Hollanda sağlık hizmetlerinden FAIR Genomes modeli. Her GHGA alanı için karşı modellerde eşdeğeri olup olmadığını soran ayrıntılı bir “karşılıklı eşleme” (crosswalk) gerçekleştirdiler. GHGA’nın ana özelliklerinin çoğunun, özellikle çalışmaların, örneklerin, deneylerin, analizlerin ve dosya formatlarının tanımlanmasında başka yerlerde açık karşılıkları olduğunu buldular. Bu, GHGA veri setlerinin diğer Avrupa sistemlerinde depolanan verilerle birlikte anlaşılabileceği ve entegre edilebileceği anlamına geliyor.
Ortak zemin bulmak – ve hâlâ eksik olanlar
Bu karşılaştırmadan ekip, beş modelin en az üçünde görünen 25 “uzlaşı” metadata alanı çıkardı. Bunlar, katılımcıların cinsiyeti ve sağlık durumu, kullanılan doku, dizileme türü ve cihazı, analiz yöntemi, dosya formatları ile temel çalışma açıklamaları ve iletişim bilgileri gibi temel öğeleri kapsıyor. Bu paylaşılan alanlar mevcut asgari raporlama yönergeleriyle örtüşüyor ve yeni genomik veri portalları tasarlayanlar için bir temel kontrol listesi olarak hizmet edebilir. Aynı zamanda analiz, bazı modellerin topladığı ancak GHGA’nın şu anda ihmal ettiği ya da esnek serbest metin şeklinde kabul ettiği bilgileri ortaya koydu; örneğin örnekleme ve dizileme tarihleri, hariç tutulan tanılar ve ayrıntılı iletişim isimleri. Bu eksikliklerin birçoğu gizlilik ve anonimlik lehine bilinçli alınmış takaslardır.
Geleceğin sağlık araştırmaları için anlamı
Genel olarak çalışma, GHGA’nın metadata modelinin ayrıntılı, esnek ve uluslararası uygulamalarla yakından uyumlu olduğunu, aynı zamanda sıkı Avrupa gizlilik kuralları içinde kaldığını gösteriyor. Model, diğer arşivlerin zorunlu gördüğü tüm alanları zaten kapsıyor ve tek hücre ile mekânsal omikler gibi yeni teknolojilere genişletilebilir. Bir genomik çalışmanın kimleri ve neleri içerdiğini, verilerin nasıl üretildiğini ve hangi koşullarda yeniden kullanılabileceğini açıkça tanımlama yolu sunarak GHGA, izole veri silolarını bağlantılı bir araştırma kaynağına dönüştürmeye yardımcı oluyor. Hastalar için bu, bağışlanan verilerinin sınırlar ötesinde keşiflere ve daha iyi tedavilere güvenle katkıda bulunma şansını yıllarca artırıyor.
Atıf: Mauer, K., Iyappan, A., Parker, S. et al. Semantic alignment of the German Human Genome-Phenome Archive metadata model in Europe’s genomics field. Sci Data 13, 242 (2026). https://doi.org/10.1038/s41597-026-06575-y
Anahtar kelimeler: genomik veri paylaşımı, metadata standartları, gizlilik ve GDPR, GHGA, kişiselleştirilmiş tıp