Clear Sky Science · tr
Büyük dil modellerinin halka yönelik tıbbi asistan olarak güvenilirliği: rastgele atanmış, önkayıtlı bir çalışma
Telefonunuz neden en iyi ilk doktor olmayabilir
Giderek daha fazla insan, kendini iyi hissetmediğinde endişelenip endişelenmemeleri, semptomlarının ne anlama gelebileceği ve hastaneye gidip gitmemeleri gerektiği konusunda hızlı yanıtlar umuduyla yapay zeka sohbet botlarına başvuruyor. Bu çalışma basit ama acil bir soruyu soruyor: sıradan insanlar evde güçlü dil modellerini tıbbi yardımcı olarak kullandığında, sağlıklarıyla ilgili daha iyi kararlar mı alıyorlar yoksa teknoloji yanlış bir güven duygusu mu yaratıyor?
Akıllı makineleri gerçek hayata benzer vakalarda test etmek
Bunu anlamak için Birleşik Krallık’tan araştırmacılar, ani şiddetli baş ağrısı veya nefes almada zorluk gibi, birçok kişinin karşılaşabileceği yaygın durumlara dayanan on gerçekçi tıbbi hikâye tasarladı. Deneyimli bir doktor ekibi her öykü için en iyi “bir sonraki adım” konusunda—evde kalıp kendine bakmaktan ambulans çağırmaya kadar—uzlaştı ve dikkatli bir kişinin göz önünde bulundurması gereken temel durumları listeledi. Ardından Birleşik Krallık’tan 1.298 yetişkin rastgele dört seçenekten birine atandı: üç önde gelen yapay zeka sohbet botundan birini kullanmak ya da web araması veya kişisel deneyim gibi normalde evde güvendikleri yöntemleri kullanmak.
İnsanların ve makinelerin performansı—ayrı ayrı ve birlikte
Dil modelleri, vaka tanımlarının tamamı verilerek ve doğrudan tanı ve önerilen eylem sorularak kendi başlarına test edildiğinde etkileyici performans gösterdi. Üç sistem genelinde, vakaların yaklaşık %95’inde en az bir ilgili tıbbi durumu doğru şekilde önerdiler ve aciliyet düzeyini yarıdan fazla durumda doğru seçtiler—rastgele tahminden çok daha iyi. Kağıt üzerinde bu sistemler endişeli hastalara rehberlik edecek güçlü adaylar gibi görünüyordu.
AI tavsiyesi gerçek insanlarla buluştuğunda
Ancak sıradan kullanıcılar devreye girince tablo değişti. Yapay zekâ kullanan katılımcılar, bir sonraki ne yapılacağı konusunda kontrol grubundan daha doğru değildi ve altta yatan ilgili durumları isimlendirmede aslında daha kötüydü. AI dışı gruptaki kişiler, sohbet botlarını kullananlara kıyasla doğru bir durumu tanımlama olasılığı yaklaşık 1,8 kat daha yüksekti. Tüm gruplardaki çoğu katılımcı durumun ne kadar ciddi olduğunu olduğundan daha az tahmin etti. Başka bir deyişle, gelişmiş bir dil modeline erişim insanların semptomlarını daha iyi anlamasına yardımcı olmadı ve onları açıkça daha güvenli seçimlere yönlendirmedi.
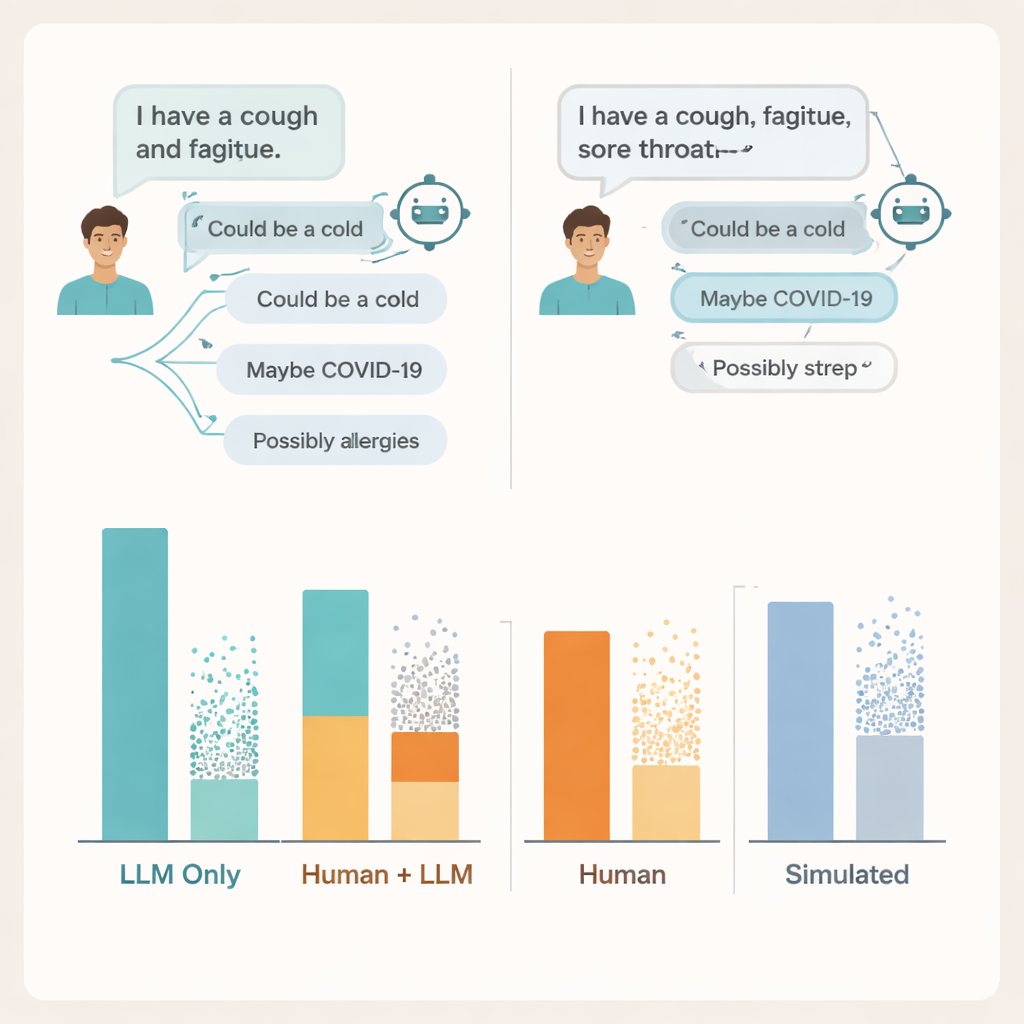
Sohbetin nerede bozulduğu
Nedenini anlamak için araştırmacılar gerçek sohbet transkriptlerini inceledi. Konuşmanın her iki tarafında da sorunlar buldular. Birçok kullanıcı, yapay zekânın sağlam tavsiye vermesi için semptomları hakkında yeterince ayrıntı paylaşmadı—tıpkı hastaların bazen bir doktorla konuşurken kilit bilgileri atlaması gibi. Modellerin kendileri genellikle en az bir ilgili durumu söylemiş olsa da birkaç yanlış veya dikkat dağıtıcı olasılık da eklediler ve kullanıcılar hangi önerilerin önemli olduğunu ayırt etmekte zorlandı. Bazı vakalarda neredeyse aynı semptom betimlemeleri aynı modelden keskin şekilde farklı tavsiyelere yol açtı; bu da insanların ekranda gördüklerine ne zaman güveneceklerine dair net bir fikir edinmesini zorlaştırdı.
Standart testlerin gerçek riskleri neden kaçırdığı
Araştırma ekibi bu sonuçları tıbbi yapay zekâyı değerlendirmede yaygın kullanılan iki yöntemle de karşılaştırdı: çoktan seçmeli sınav soruları ve iki model arasında yürütülen tamamen simüle edilmiş “hasta” sohbetleri. Her ikisinde de sistemler yine güçlü görünüyordu; sınav tarzı sorularda tipik geçme puanlarına ulaştılar veya onları aştılar ve simüle edilmiş hastalarla gerçek hastalardan daha iyi performans gösterdiler. Yine de yüksek sınav puanları ve cilalanmış simülasyon konuşmaları, gerçek insanların aynı araçları kullandığında nasıl iş gördükleriyle örtüşmedi. Yazarlar, bilgiyi izole şekilde test eden kıyaslamaların, gerçek insan–AI etkileşimlerinin dağınık ve kırılgan doğasını kaçırdığını savunuyor.
Bu hastalar ve sağlık sistemleri için ne anlama geliyor
Şimdilik çalışma, genel amaçlı mevcut dil modellerinin halka denetimsiz ön saflarda tavsiye verecek kadar hazır olmadığını sonuç olarak belirtiyor. Bu modeller açıkça çok miktarda tıbbi bilgi içeriyor, ancak bu bilgi endişeli insanların evde kısmi, karışık sorular yazması durumunda otomatik olarak daha güvenli kararlara dönüşmüyor. Yapay zekâyı sağlık gibi yüksek riskli ortamlarda gerçekten yardımcı kılmak, daha iyi sınav puanlarından daha fazlasını gerektirecek—dikkatli tasarım, çeşitli gerçek kullanıcılarla test ve bilgi toplanması, açıklanması ve konuşma sürecinde güvenilmesinin daha sıkı denetlenmesini gerektirecek.
Atıf: Bean, A.M., Payne, R.E., Parsons, G. et al. Reliability of LLMs as medical assistants for the general public: a randomized preregistered study. Nat Med 32, 609–615 (2026). https://doi.org/10.1038/s41591-025-04074-y
Anahtar kelimeler: tıbbi sohbet botları, kendi kendine tanı, sağlık hizmetlerinde yapay zeka, hasta karar verme, büyük dil modelleri