Clear Sky Science · tr
Geri Getirmeli Dil Modelleriyle bilimsel literatür sentezlemek
Bilimde güncel kalmanın neden bu kadar zor olduğu
Her yıl çevrimiçi ortama milyonlarca yeni bilimsel makale düşüyor. Hiçbir insan araştırmacı bunların hepsini okuyamaz; oysa önemli tıbbi tedaviler, iklimle ilgili içgörüler ve teknolojik atılımlar bu bilgi seli içinde saklı olabilir. Bu makale, gelişmiş yapay zeka sistemlerinin bilim insanlarının bu çalışma okyanusunu taramasına ve bunları uydurma yapmadan açık, güvenilir özetler halinde birleştirmelerine yardımcı olup olamayacağını inceliyor.
Yeni türden bir araştırma asistanı
Yazarlar OpenScholar’ı tanıtıyor: bilimsel literatürü okumak ve sentezlemek üzere özel olarak inşa edilmiş bir yapay zeka sistemi. Genel sohbet botlarından farklı olarak OpenScholar, yaklaşık 45 milyon araştırma makalesinden oluşan devasa açık bir veritabanı olan OpenScholar DataStore’a sıkı şekilde bağlıdır. Bir bilim insanı bir soru sorduğunda —örneğin levite nanoparçacıkları nasıl soğutacağı veya beyin görüntülemede hangi yöntemlerin en iyi olduğu gibi— sistem önce bu veritabanında ilgili pasajları arar, ardından insan yazısı bir derleme makalesi gibi satır içi atıflarla bir yanıt taslağı oluşturur. Bu süreci birkaç kez tekrarlayarak kendi taslaklarını eleştirir ve açıklık, bütünlük ile atıf kalitesini iyileştirir.
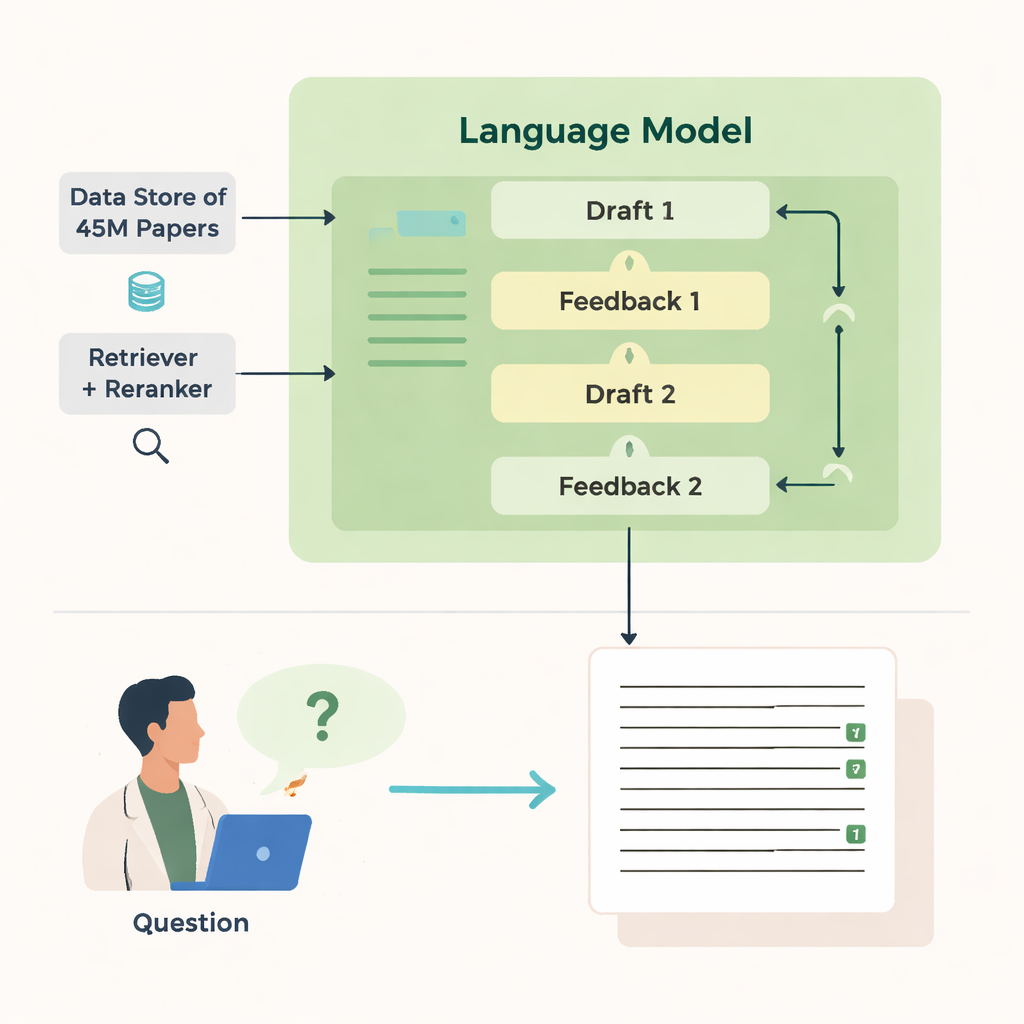
Nasıl arıyor ve yazıyor
OpenScholar’ın gücü, birbiriyle koordineli birkaç bileşenden gelir. Bir “getirici” modül, milyonlarca makaleden önceden hesaplanmış metin gömme (embedding) verilerini tarayarak umut vaat eden parçaları bulur; bir “yeniden sıralayıcı” ise bu parçaları en alakalı olanları öne alacak şekilde yeniden düzenler. Dil modeli sonra bu kanıtı kullanarak numaralandırılmış referanslarla uzun biçimli bir yanıt üretir. İlk taslaktan sonra model kendi kendine geri bildirim üretir —eksik perspektifleri, zayıf yapıyı veya yetersiz kanıtı işaret eder— ve gerektiğinde daha hedefli aramalar tetikler. Ardından yanıtı tekrar yazar, yeni makaleleri örer ve atıfları ayarlar. Son bir kontrol, destek gerektiren ifadelerin en az bir getirilen kaynakla desteklendiğinden emin olur.
İddiaları ve atıfları teste sokmak
OpenScholar’ın gerçekten yardımcı olup olmadığını görmek için yazarlar ScholarQABench’i oluşturdu; gerçek literatür-taraması sorularını taklit etmek üzere tasarlanmış büyük bir ölçüt. Bu ölçüt, bilgisayar bilimi, fizik, sinirbilim ve biyomedikal alanlarda uzmanlar tarafından yazılmış neredeyse 3.000 soru ve yüzlerce uzun yanıt içeriyor. Önemli olarak, bu sorular genellikle yalnızca bir özetin okunmasını değil, birden fazla makalenin okunmasını gerektiriyor. Ekip sistemleri birden çok eksende değerlendirdi: olgusal doğruluk, yanıtların ana noktaları ne kadar kapsadığı, yazının açıklığı ve atıfların temel aldığı makaleleri ne kadar doğru yansıttığı. Otomatik kontrolleri, yapay zekâ tarafından üretilen yanıtları insan yazılarıyla karşılaştıran doktora düzeyindeki uzmanların ayrıntılı puanlamalarıyla birleştirdiler.
Güçlü sohbet botlarını geçmek ve uzmanlarla eşleşmek
Bu ölçütte OpenScholar, standart dil modellerinin ve basitçe bir genel sohbet botuna getiriyi ekleyen önceki araçların her ikisinden de daha iyi performans gösterdi. Tamamen açık verilerle eğitilmiş kompakt, sekiz milyar parametreli bir versiyon, daha büyük özel modellere dayanan GPT-4o ve PaperQA2 adlı rakip bir sistemden, çoklu makale sentezi gerektiren zorlu bir görevde daha iyi sonuç aldı. Çarpıcı bulgulardan biri sıradan sohbet botlarının atıf uydurmasıydı: durumların %78–90’ında atıf listelerinde var olmayan ya da iddiaları desteklemeyen makaleler yer alıyordu. Buna karşılık OpenScholar’ın atıf doğruluğu insan uzmanlarınkine rakip oldu. Uzmanlar yanıtları doğrudan karşılaştırdığında, OpenScholar-8B’yi insan uzmanların yazdığı yanıtlara yaklaşık yarı zaman tercih etti ve GPT-4o üzerine kurulu bir OpenScholar boru hattını yaklaşık %70 oranında tercih etti; bu tercihin büyük bölümünü AI’nın daha fazla ilgili çalışmayı kapsaması ve bunları açıkça düzenlemesi oluşturdu.
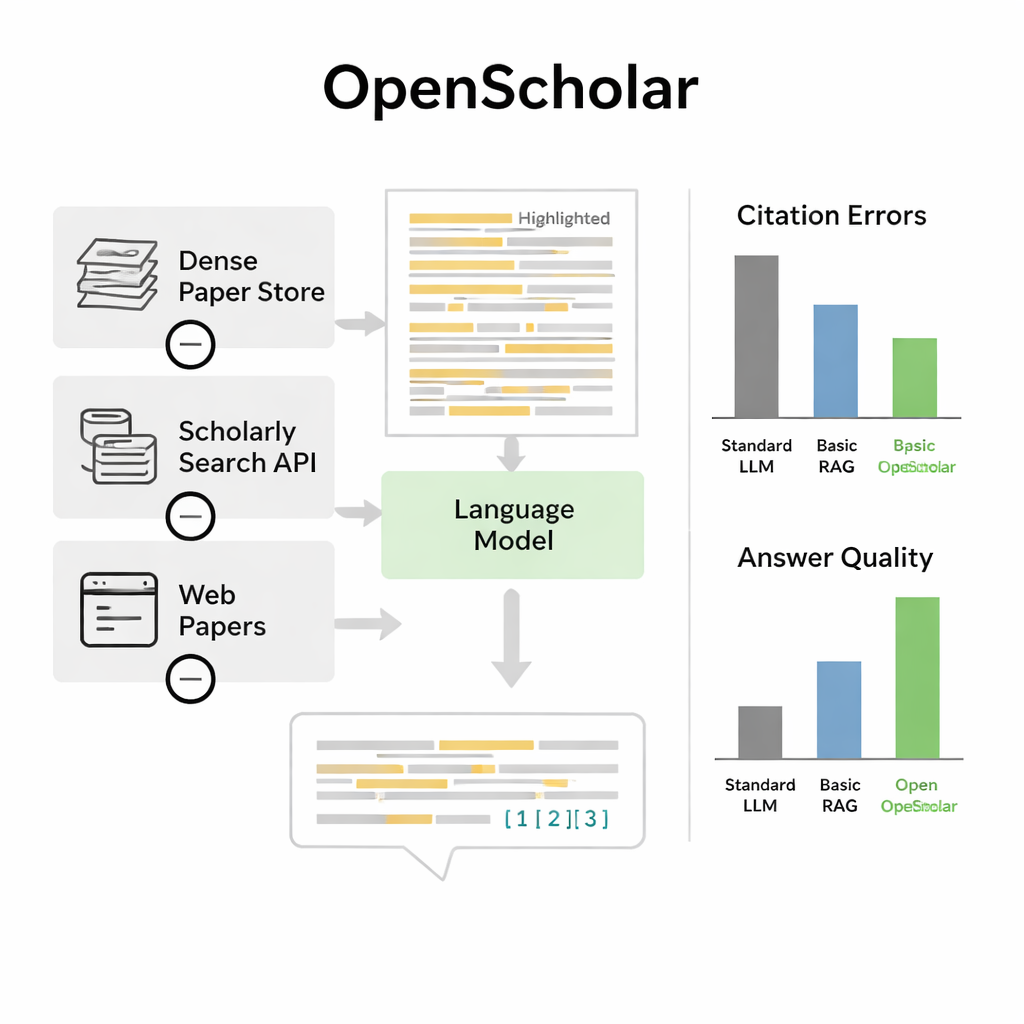
Sınırlamalar ve gelecekteki iyileştirmeler
Bu kazanımlara rağmen yazarlar OpenScholar’ın bilim insanlarının yerini almadığını vurguluyor. Sistem hâlâ en temsil edici makaleleri kaçırabilir, daha az önemli çalışmalara aşırı önem verebilir veya özellikle daha kompakt modellerde olgusal hatalar yapabilir. Ölçütün kendisinin de sınırları var: ağırlıklı olarak bilgisayar bilimi, biyomedikal ve fizik üzerine odaklanıyor ve dikkatle açıklanmış sorular hâlâ nispeten az çünkü uzman zamanının maliyeti yüksek. Değerlendirmeler ayrıca atıfların gerçekten çığır açıcı çalışmaları vurgulayıp vurgulamadığı veya bir yanıtın yeni bir deneyi gerçekten yönlendirip yönlendirmeyeceği gibi daha ince nitelikleri tam olarak yakalamakta zorluk çekiyor.
Günlük bilim için bunun anlamı
Uzman olmayanlar için ana çıkarım şu: dikkatle tasarlanmış yapay zeka araçları, gerçek verilere bağlı oldukları ve kanıt ile şeffaflık için sıkı standartlara tabi tutuldukları sürece, bilim insanlarının literatürü daha etkili gezmelerine zaten yardımcı olabilir. OpenScholar, bir yapay zeka sistemi temelinden itibaren gerçek makaleleri getirmek, doğrulamak ve atıf yapmak üzere inşa edildiğinde —ve performansı insan uzmanlara karşı test edildiğinde— okunabilir olmanın ötesinde doğrulanabilir literatür özetleri üretebileceğini gösteriyor. Pratikte bu tür araçlar, araştırmacıların deney tasarımı ve sonuçların yorumlanmasına daha fazla odaklanabilmesi için zaman açabilir; yine de gerçek ve önemli olanı değerlendirme sorumluluğu nihayetinde insanlarda kalmalıdır.
Atıf: Asai, A., He, J., Shao, R. et al. Synthesizing scientific literature with retrieval-augmented language models. Nature 650, 857–863 (2026). https://doi.org/10.1038/s41586-025-10072-4
Anahtar kelimeler: bilimsel literatür taraması, geri getirmeli dil modelleri, OpenScholar, atıf doğruluğu, Yapay zeka araştırma araçları