Clear Sky Science · tr
DNA elması, DNA veri depolama için ayrıştırılabilir bir bileşik harf takımyıldızı modeli formüle ediyor
Geleceğin verileri neden DNA’da yaşayabilir
Telefonlarımız, şirketler ve bilimsel cihazlar, sabit diskler ve manyetik bantların yetişemeyeceği hızda veri üretiyor. Canlılarda genetik bilgiyi taşıyan aynı molekül olan DNA, dijital dosyaları son derece kompakt ve uzun ömürlü bir biçimde depolamak için de kullanılabilir. Bu makale, sentetik DNA iplikçiklerine daha fazla bilgi paketlemenin yeni bir yolunu tanıtıyor; okunabilirliği pratik ve güvenilir tutarken maliyeti düşürebilecek ve ölçeklenebilirliği artırabilecek bir yaklaşım sunuyor.
Dört DNA harfinden daha zengin karışımlara
Geleneksel DNA depolama, disk üzerindeki sıfırlar ve birler gibi dijital bitleri temsil etmek için dört doğal DNA bazı—A, T, G ve C—kullanır. Bu düzenekte bir DNA ipliğinin her konumu en fazla iki bit bilgi taşıyabilir çünkü dört seçeneğin birine sınırlıdır. Yazarlar, ortaya çıkan bir fikri geliştiriyor: her konuma tek bir baz yerleştirmek yerine, bileşik harfler olarak adlandırılan özenle kontrol edilen baz karışımları oluşturmak. Örneğin bir konum %50 A ve %50 T karışımı ya da tüm dört bazın %25:%25:%25:%25 karışımı olabilir. Her ipliğin birçok kopyası sentezlendiğinde, bu karışımların dizilenmesi baz oranlarını açığa çıkarır ve bu oranlar iki bitten fazla bilgi temsil edebilen dijital bir sembole karşılık gelir.
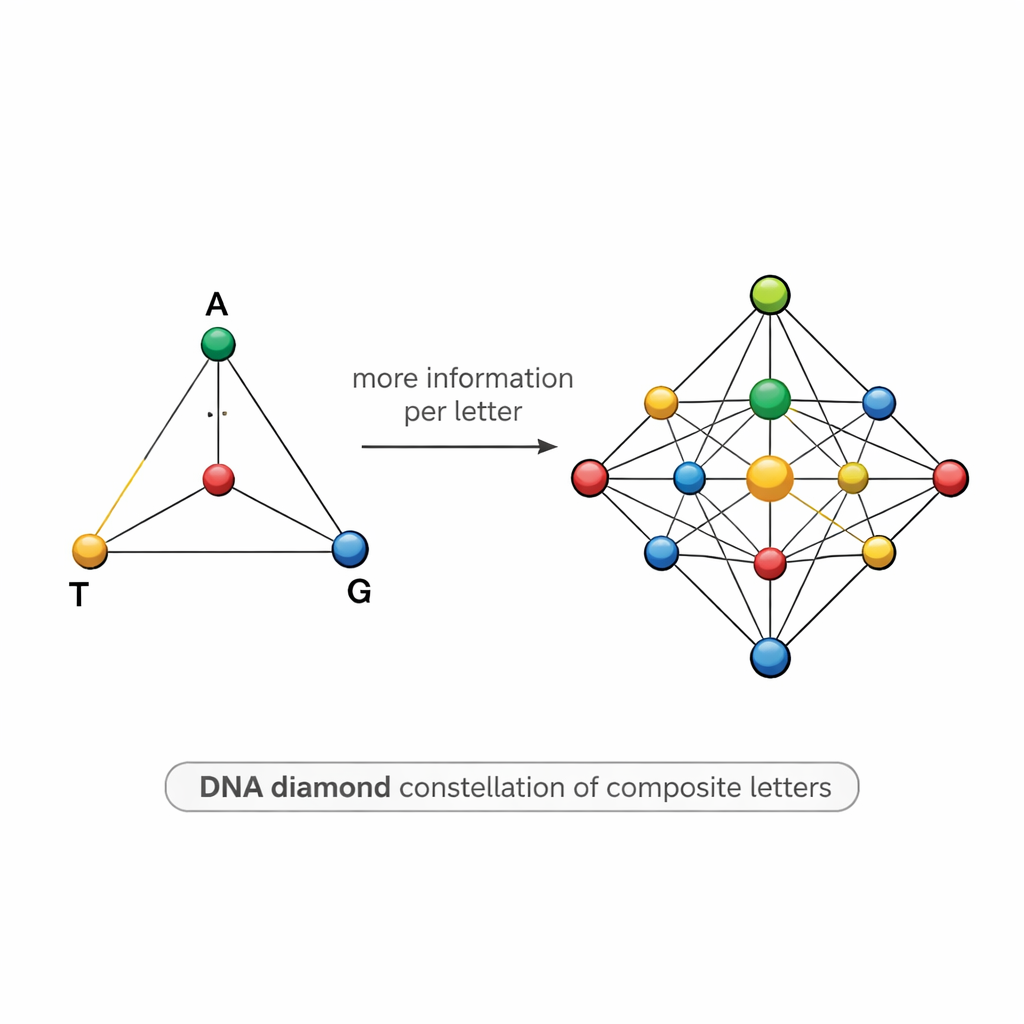
DNA sembollerinin elmas biçimli haritası
Böyle karışımlar tasarlamak zordur. İki sembol çok benzerse—örneğin biri %50 A, %50 T ve diğeri %55 A, %45 T ise—dizileme kaynaklı gürültü bunları birbirine karıştırabilir, hatalara yol açar ve bilim insanlarını daha fazla kopya dizilemeye zorlar. Bunu aşmak için ekip, yapılandırılmış bir “DNA elması” modeli öneriyor: köşeleri A, T, G ve C olan bir tetrahedron üzerinde noktalar gibi düzenlenmiş 15 bileşik harften oluşan bir küme. Küme, köşelerde saf bazları, kenarlarda iki bazın eşit karışımlarını, yüzeylerde üç bazın karışımlarını ve merkezde dört bazın tamamen eşit karışımını içeriyor. Bu özenle seçilmiş takımyıldızı, teoride bir konum başına bilgiyi yaklaşık 3.9 bite çıkarırken, sembolleri pratikte birbirinden ayırt edilebilir tutuyor.
Entropi ve indekslemeyle daha akıllı çözümler
Veriyi DNA’dan geri okumak, baz frekanslarının gürültülü ölçümlerinden her konumda hangi bileşik harfin kastedildiğini çıkarmak demektir. Yazarlar, telekomünikasyondan set bölümlendirmesi (set partitioning) adı verilen bir strateji ödünç alıyor. Önce, bir konumun ne kadar “karışık” göründüğüne bakıyorlar; saf bazlar için düşük, karmaşık karışımlar için daha yüksek olan entropi isimli bir nicelik kullanıyorlar. Bu, her konumu hızlıca dört gruptan birine atıyor: saf bazlar, iki bazlı karışımlar, üç bazlı karışımlar veya dört bazlı karışım. Ardından seçilen grup içinde daha hassas bir olasılık hesabı en muhtemel harfi seçiyor. Bu iki aşamalı yaklaşım, semboller arasındaki karışıklığı azaltıyor ve önceki yöntemlere kıyasla hesaplama süresini kısaltıyor. Ayrıca iplikçiklerin birbirine karıştırılmasını önlemek için her DNA parçası iki ucunda hata korumalı indeks dizileri taşıyor ve ekleme/silme hatalarının sık yol açtığı yanlış uzunluktaki okumalar çözüme başlamadan önce eleniyor.
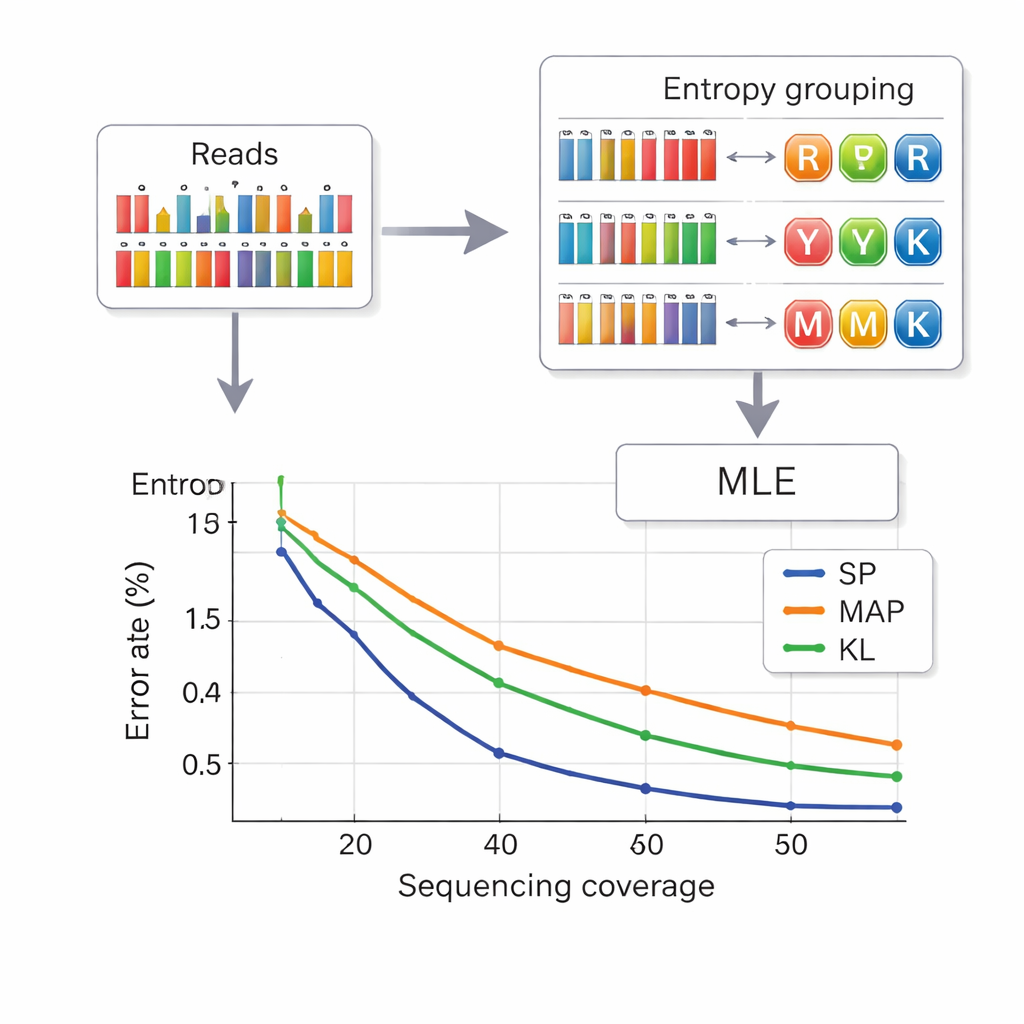
Daha az okumayla daha fazla veri paketleme
Araştırmacılar sistemlerini ticari sentez platformları kullanarak hem küçük hem büyük DNA havuzlarında test etti. Sekiz harfli bir bileşik alfabe ile konum başına 2.5 bitlik bir yük yoğunluğuna ulaştılar ve iplik başına ortalama 14 dizileme okuması ile dosyaları kusursuz şekilde geri elde edebildiler—altı harfli önceki şemalara göre daha iyi yoğunluk ve daha az okuma gereksinimi. Tam 15 harfli DNA elması alfabesiyle ana veri için konum başına 3.125 bit elde ettiler ve 33× örtülme ile hâlâ her şeyi hatasız kurtardılar. Simülasyonlar ve deneyler ayrıca entropiye dayalı yöntemlerinin en doğru ama daha yavaş çözümlemeye neredeyse eşdeğer performans gösterdiğini ve özellikle daha düşük dizileme derinliklerinde eski tekniklerden belirgin şekilde daha iyi olduğunu ortaya koydu.
Geleceğin hafızası için anlamı
Bilim dışı bir okuyucu için ana mesaj şudur: Yazarlar yeni bir kimya icat etmeden DNA’ya “yeni numaralar” öğretmenin bir yolunu buldular: mevcut dört bazı zekice karıştırıp daha akıllı bir şekilde çözümler uygulayarak molekül başına daha fazla bit depolayabiliyorlar ve maliyeti kontrol altında tutuyorlar. Elmas biçimli alfabeleri, sağlam indeksleme ve hata düzeltme ile birleştiğinde, göreli olarak mütevazı bir dizileme çabasıyla yüksek kapasiteli DNA veri depolamanın mümkün olduğunu gösteriyor. DNA sentezi ve dizileme ucuzlamaya devam ettikçe, bu tür tasarımlar DNA’yı laboratuvar merakı olmaktan dünyanın dijital anılarını arşivleyecek gerçekçi bir ortama dönüştürmeye yardımcı olabilir.
Atıf: Ge, Q., Ren, M., Qi, T. et al. DNA diamond formulates a decomposable composite letter constellation model for DNA data storage. Nat Commun 17, 1704 (2026). https://doi.org/10.1038/s41467-026-68861-y
Anahtar kelimeler: DNA veri depolama, bileşik harfler, bilgi yoğunluğu, hata düzeltme, dijital arşivleme