Clear Sky Science · tr
Az temsil edilen gruplar için poligenik skor tahminini aktarım öğrenimiyle iyileştirmek
DNA risk skorunuz neden sizin için işe yaramayabilir
Genetik "risk skorları", bir kişinin diyabet, kalp hastalığı veya yüksek tansiyon gibi yaygın durumları geliştirme olasılığını tahmin etmek için giderek daha sık kullanılıyor. Ancak bu skorların çoğu, Avrupa kökenli kişilerin DNA verileri kullanılarak oluşturuldu. Bunun sonucu olarak, bu skorlar diğer kökenlerden gelen kişiler için genellikle zayıf tahminler veriyor; bu da adalet ve gerçek dünyadaki tıp uygulamaları açısından düşündürücü. Bu çalışma basit bir soruyu soruyor: Büyük Avrupa veri setlerinden öğrendiklerimizi, kimsenin ham verisini paylaşmadan, az temsil edilen gruplar için daha iyi ve daha adil genetik skorlar oluşturmak üzere yeniden kullanabilir miyiz?
Milyonlarca DNA işaretinden tek bir risk skoruna
Poligenik skor, genom boyunca dağılan birçok genetik işaretin küçük etkilerini toplayan bir karneler gibi düşünülebilir. Her işaret, büyük genetik çalışmalara dayanarak bir özelliğe ne kadar güçlü bağlı olduğunu yansıtan bir ağırlık alır. Bu çalışmalar çoğunlukla Avrupalıları içerdiğinde ortaya çıkan skor da genellikle Avrupalılarda en iyi şekilde işe yarar. Genetik geçmişlerdeki farklılıklar—bazı DNA varyantlarının ne kadar yaygın olduğu ve birlikte nasıl aktarıldığı—aynı ağırlıkların Afrika kökenli Amerikalılar, Hispanikler ve diğer popülasyonlarda sıklıkla yanlış sonuçlar vermesine yol açar. Her grup için eşit büyüklükte veri toplamak pahalı ve yavaştır; bu yüzden yazarlar aktarım öğrenimi adlı bir makine öğrenimi stratejisine başvurdular: her popülasyonda sıfırdan başlamak yerine, başka yerde eğitilmiş mevcut bir modeli geliştirdiler.
Ham veriyi paylaşmadan bilgiyi nasıl ödünç alırsınız
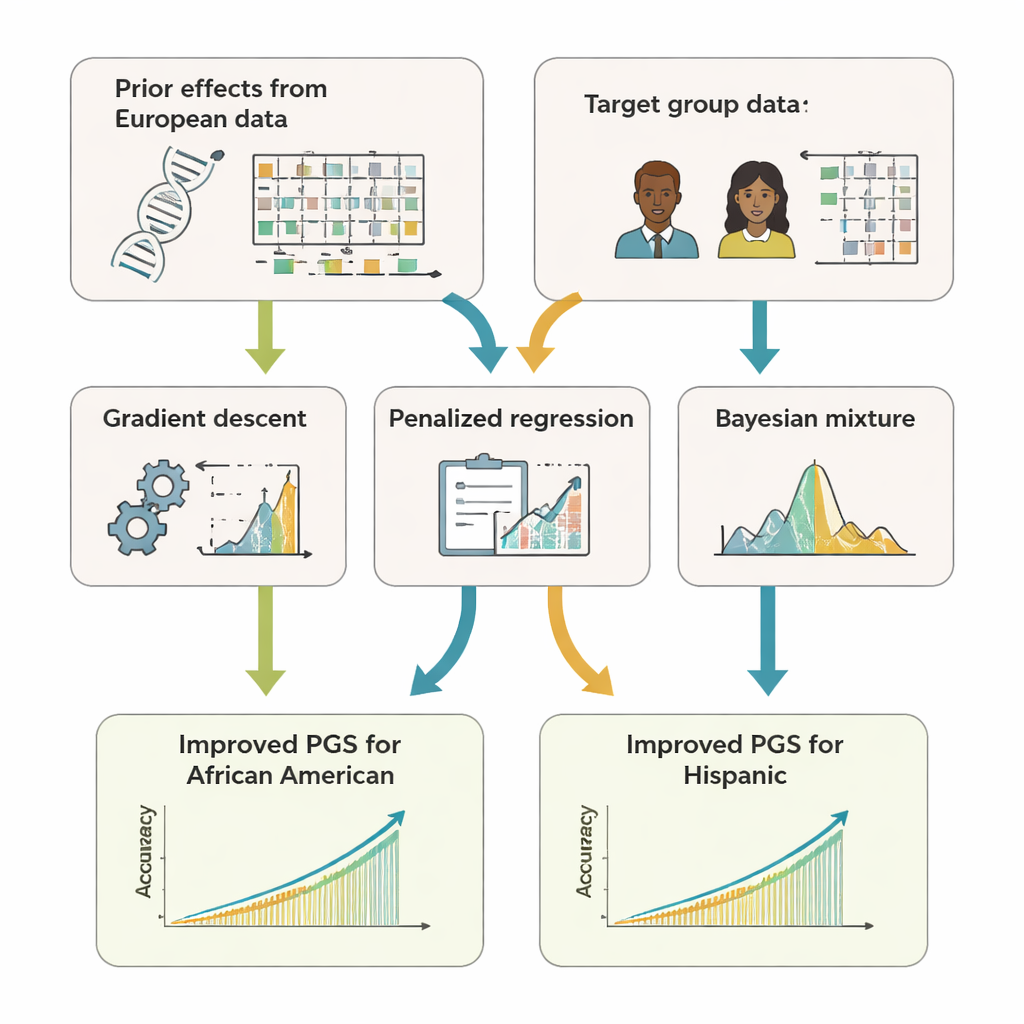
Ekip, genetik skorlar için üç aktarım öğrenimi yaklaşımını uygulayan açık kaynaklı bir R yazılım paketi olan GPTL’yi geliştirdi. Üç yaklaşımın tamamı, büyük bir Avrupa kökenli veri setinde elde edilmiş DNA etkilerine dair mevcut tahminlerden başlar ve ardından bu tahminleri Afrika kökenli Amerikalılar veya Hispanikler gibi hedef bir grubun verileriyle nazikçe ayarlar. Bir yöntem, Avrupa ağırlıklarını adım adım gradyan inişiyle ince ayar yaparak tamamen üzerine yazmadan erken durur. İkinci yöntem, cezalandırmalı regresyon olarak adlandırılır; hedef veriler güçlü kanıt sağlamadıkça yeni tahminleri orijinal değerlere çekmeye devam eder. Üçüncüsü ise bir Bayesçi karışım modelidir: her DNA işaretinin birden çok bilgi kaynağı—örneğin birden fazla köken grubu ya da "etkisiz" seçeneği—arasında seçim yapmasına izin verir ve hedef verileri en iyi açıklayan kaynaklara göre bunları harmanlar.
Yöntemleri teste sokmak
Bu yaklaşımların ne kadar iyi çalıştığını görmek için yazarlar hem bilgisayar simülasyonları hem de İngiltere Biobank ve ABD All of Us araştırma programındaki yüzbinlerce gönüllüden gerçek veriler kullandılar. Hedef gruplar olarak Afrika kökenli Amerikalılar ve Hispanikleri odaklandılar ve ön bilgi kaynağı olarak Avrupa kökenli verileri kullandılar. Boy, vücut kütle indeksi, kan lipitleri, kan basıncı ve böbrek belirteçleri de dahil olmak üzere 11 özelliğin tümünde aktarım öğrenimi skorları, yalnızca hedef grupta oluşturulan veya sadece Avrupalılardan yeniden kullanılan skorlardan tutarlı biçimde daha iyi tahmin etti. Çoğu durumda doğrulukları, ham verileri birden çok popülasyondan birleştirmeyi gerektiren daha karmaşık "çok-kökenli" yöntemlerle eşleşti veya biraz aştı. Kritik olarak, GPTL’nin yöntemleri yalnızca özet istatistiklere—genetik etkilerle ilgili toplanmış sayılara—ihtiyaç duyduğundan, kurumlar birey düzeyindeki genetik kayıtları ifşa etmeden işbirliği yapabilir.
Daha fazla DNA her zaman daha iyi değildir
Araştırmacılar ayrıca hangi genetik işaretlerin dahil edileceğini en iyi nasıl seçileceğini incelediler. Her kullanılabilir işareti eklemenin her zaman yardımcı olduğu yönündeki yaygın inanışın aksine, Afrika kökenli Amerikalılar ve özellikle Hispanik gruplar için milyonlarca çok zayıf sinyalin dahil edilmesinin performansa zarar verebileceğini buldular; bu durum, varyantlar arasındaki genetik korelasyonların oldukça basitleştirilmiş temsilinin kullanıldığı durumlarda özellikle belirgindi. Daha iyi desteklenen işaretlere odaklanmak ve varyantların birlikte nasıl aktarıldığına dair daha zengin bilgiler kullanmak genellikle daha doğru skorlar verdi. Çalışma ayrıca birden çok köken grubundan gelen ön bilgilerin eklenmesinin ve popülasyonlar arasındaki farklılıkların dikkatle modellenmesinin tahminleri daha da iyileştirdiğini gösterdi.
Adil genetik risk tahmini için ne anlama geliyor
Avrupa dışı popülasyonlar için piyasadaki genetik risk skorları bugün büyük farklarla yetersiz kalabilir ve bu durum sağlık eşitsizliklerini daha da genişletebilir. Bu çalışma, aktarım öğreniminin—Avrupa temelli mevcut skorları az temsil edilen gruplardan elde edilen mütevazı veri kümeleriyle akıllıca iyileştirmenin—bu farkın çoğunu kapatabileceğini gösteriyor. Pratikte bu, sağlık sistemleri ve araştırmacıların kurumlar veya kökenler arasında ham verileri birleştirmeye gerek kalmadan daha doğru ve eşitlikçi genetik araçlar oluşturabileceği, böylece gizlilik endişelerinin azalacağı anlamına geliyor. Her özellik ve popülasyon için tek bir yöntemin en iyi çözüm olmayacağı doğru olsa da, GPTL araç takımı, geçmiş modelleri sabit ürünler olarak görmek yerine herkes için uyarlanabilecek başlangıç noktaları olarak ele alırsak daha adil genetik tahminin teknik olarak erişilebilir olduğunu gösteriyor.
Atıf: Wu, H., Pérez-Rodríguez, P., Boehnke, M. et al. Improving polygenic score prediction for underrepresented groups through transfer learning. Nat Commun 17, 1973 (2026). https://doi.org/10.1038/s41467-026-68696-7
Anahtar kelimeler: poligenik risk skorları, aktarım öğrenimi, genetik tahmin, sağlık eşitsizlikleri, popülasyon genetiği