Clear Sky Science · tr
PGS-hub platformu ile tek ve çok kökenli poligenik skor yöntemlerinin kapsamlı kıyaslaması
DNA risk skorunuzun önemi
Hekimler, kalp hastalığı, diyabet veya şizofreni gibi yaygın hastalıklara kimlerin daha yatkın olduğunu DNA’mızı okuyarak daha iyi tahmin ediyor. Poligenik skorlar olarak adlandırılan bu tahminler, çok sayıda genetik varyantın küçük etkilerini tek bir sayıda birleştirir. Ancak bu skorları hesaplamanın artık birçok farklı yolu var ve bu yöntemler farklı atasal geçmişe sahip kişiler için eşit derecede iyi çalışmıyor. Bu çalışma, önde gelen yöntemleri karşılaştırmayı ve araştırmacıların bu skorları tutarlı ve kolay bir şekilde hesaplamasını sağlayan çevrimiçi bir hizmet olan PGS-hub’u geliştirmeyi amaçladı.
DNA risk hesaplayıcıları için tek duraklı platform
Yazarlar, poligenik skorların teknik karmaşıklığının çoğunu saklayan bir web platformu olan PGS-hub’u oluşturdu. Kullanıcılar, milyonlarca DNA işaretçisinin bir hastalık veya özellik ile nasıl ilişkili olduğunu özetleyen genetik çalışma sonuçlarını yüklüyor. Ardından ilgilendikleri popülasyonun atasal kökenini —örneğin Avrupa veya Afrika— seçiyor ve popüler skorlama yöntemleri menüsünden birini seçiyorlar. Sahne arkasında PGS-hub, girişi doğru formatlara dönüştürüyor, yakın DNA işaretçileri arasındaki korelasyonu tanımlayan önceden oluşturulmuş referans panellerini kullanıyor ve yüksek performanslı bilgi işlem sisteminde çok sayıda işi yürütüyor. Çıktı, her bireyin genomuna uygulanarak her kişi için bir skor üretilmesini sağlayan kompakt bir ağırlık dosyası oluyor. 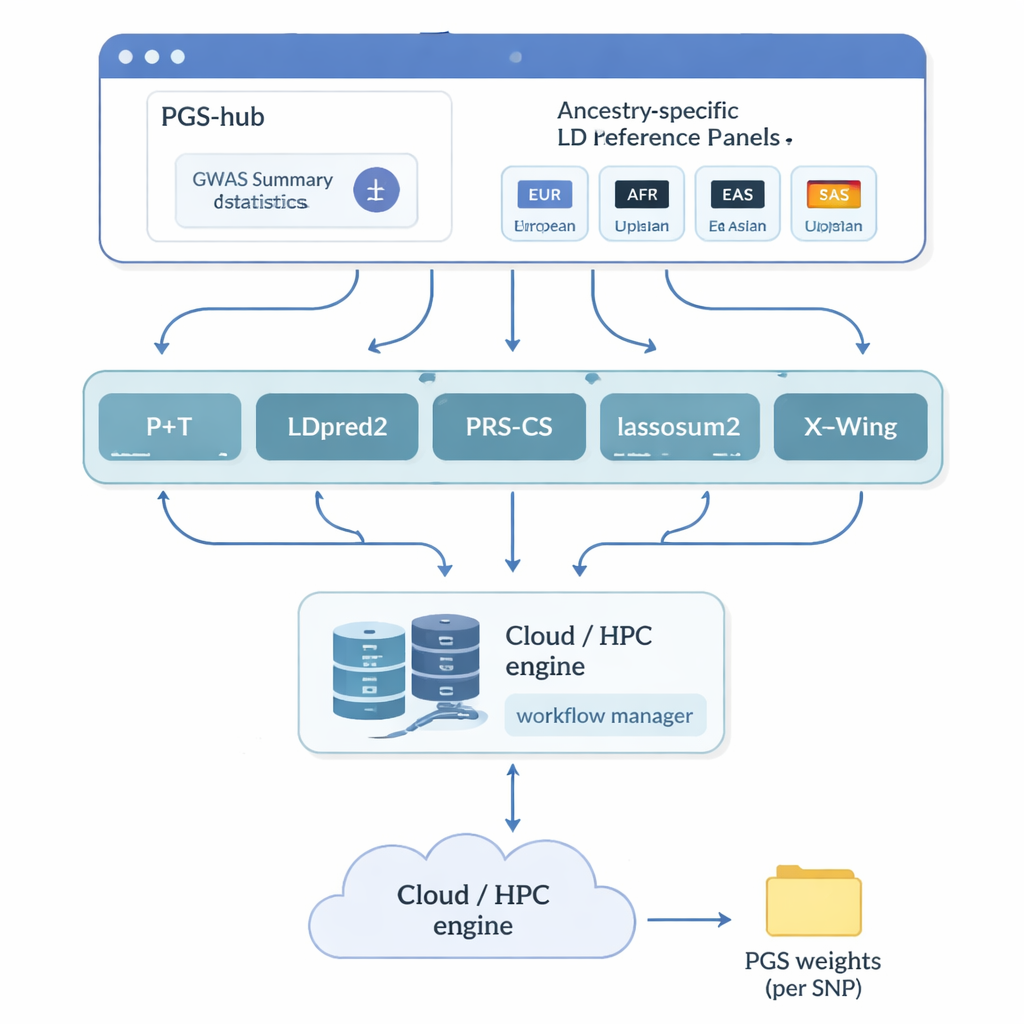
13 skorlama yönteminin sınanması
Hangi yaklaşımların en iyi çalıştığını görmek için ekip, İngiltere Biobank’tan Avrupa kökenli yaklaşık 380.000 kişi ve Afrika kökenli biraz üzerinde 8.000 kişi olmak üzere 36 hastalık ve özelliği kapsayan 13 son teknoloji yöntemi karşılaştırdı. Her skoru yalnızca bir hastalığı veya daha yüksek bir özellik değerini ne kadar iyi tahmin ettiğine göre değil, aynı zamanda her yöntemin ne kadar hesaplama süresi ve bellek tükettiğine göre de değerlendirdiler. Avrupalılarda LDpred2 adlı bir yöntem genel olarak en doğru skorları verdi ve sıklıkla diğerlerini belirgin bir farkla geride bıraktı. Birkaç alternatif —lassosum2, PRS-CS ve SDPR— birçok özellik için neredeyse aynı düzeyde performans gösterirken, bazı daha eski yöntemler geride kaldı. Boy veya Crohn hastalığı gibi özellikler için en iyi skorlar genetik riskin kayda değer bir payını açıklarken; böbrek fonksiyonu gibi diğerlerinde tüm yöntemler zayıf çıktı; bu da altta yatan genetik sinyallerin daha zayıf olduğunu yansıtıyor.
Farklı popülasyonlar ve birleşik yöntemler için çıkarımlar
Genetik tahminde büyük bir endişe, çoğunlukla Avrupalılarda eğitilmiş yöntemlerin farklı atasal geçmişe sahip kişilere iyi aktarılamayabileceğidir. Yazarlar kıyaslamalarını Afrika kökenli genetik çalışmalarını kullanarak tekrarladıklarında, her yöntemin daha kötü performans gösterdiğini buldular; bu da bu popülasyonlardaki büyük çalışmalardaki eksikliğe dikkat çekiyor. Yine de LDpred2 ve SDPR genellikle daha iyi seçenekler arasında yer aldı. Ekip ayrıca popülasyonlar arasında bilgiyi açıkça birleştiren “çok kökenli” yaklaşımları inceledi. Burada nispeten basit bir strateji—en iyi köken-spesifik LDpred2 skorlarını doğrusal olarak birleştirip tek bir LDpred2-multi skoru oluşturmak—hem Avrupa hem Afrika grupları için PRS-CSx ve X-Wing gibi daha karmaşık çok kökenli modelleri geride bıraktı. Bunun üzerine yazarlar, birden fazla yöntemden en güçlü skorları harmanlayan bir topluluk (ensemble) oluşturmanın, özellikle şizofreni ve koroner arter hastalığı gibi yüksek heritabiliteye sahip hastalıklarda, tüm özellikler genelinde tahmini daha da artırdığını gösterdi. 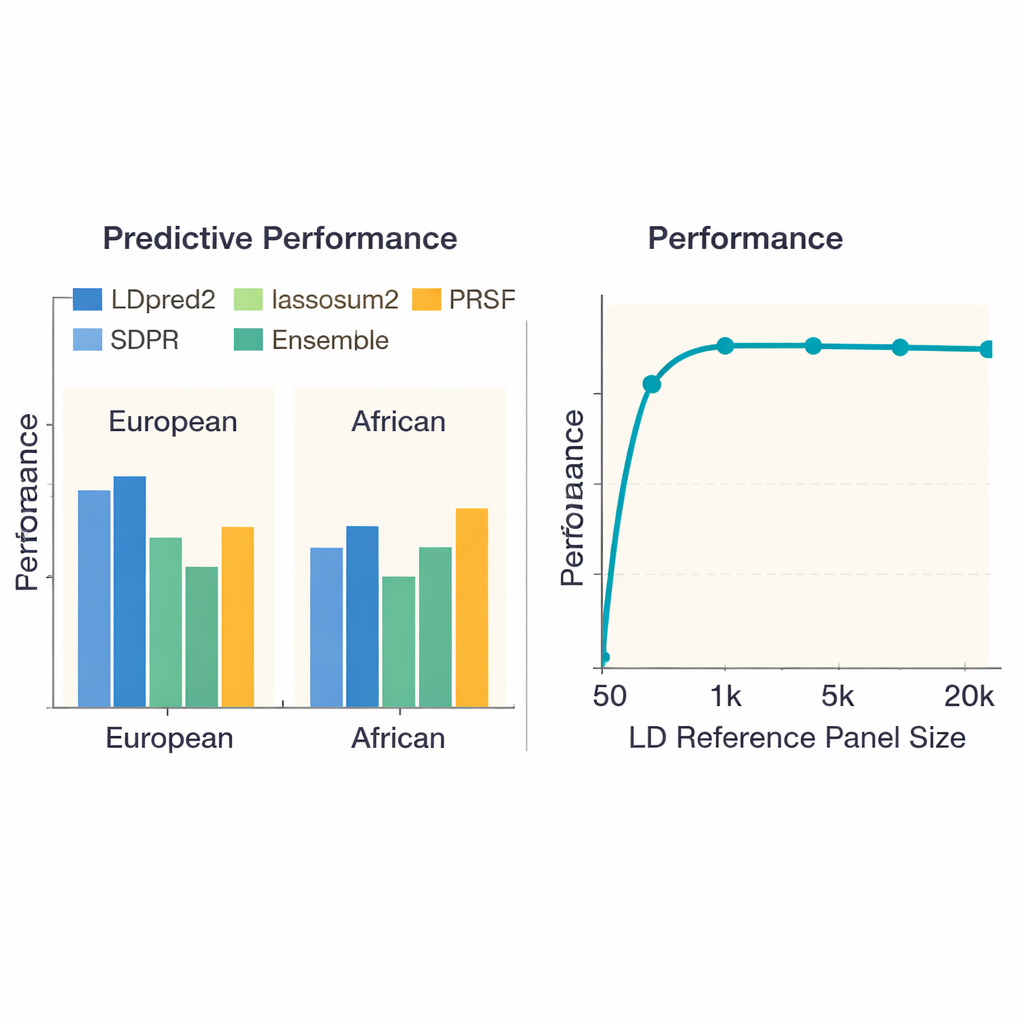
Veri tercihleri ve hesaplama sınırlamalarının skorlara etkisi
Çalışma, yakın DNA işaretçilerinin birlikte nasıl değiştiğini öğrenmek için kullanılan referans panelinin boyutunun performansı nasıl etkilediğini inceledi. Bu panel çok küçük olduğunda (1.000’in altında birey), skorlar belirgin şekilde daha az doğruydu. Panel yaklaşık 5.000 kişiye çıktığında performans keskin biçimde iyileşti ve sonra plato yaptı; bu da her geçen daha büyük panellerin azalan getiri sağladığını gösteriyor. İlginç şekilde, daha fazla DNA işaretçisini doğrudan karışıma eklemek her zaman yardımcı olmadı: yaklaşık 6,6 milyon varyant kullanmak bazen yaklaşık 1,1 milyon dikkatle seçilmiş set kullanmaktan daha kötü tahminler verdi; muhtemelen fazladan işaretler yararlı sinyalden çok gürültü kattı. Yazarlar ayrıca hesaplama maliyetlerinde büyük farklılıklar kaydetti. Temel budama-ve-eşikleme gibi basit yöntemler özellik başına bir saatin altında biterken, bazı Bayesçi yaklaşımlar yüzlerce CPU saati gerektirdi; bu, büyük projeler veya sınırlı kaynaklı gruplar için önemli bir bilgi.
Geleceğin DNA tabanlı tahmini için çıkarımlar
Uzman olmayanlar için temel mesaj, tüm DNA risk skorlarının eşit yaratılmadığı ve bunların nasıl inşa edildiğine dair ayrıntıların kimlerin bundan yararlanacağını güçlü şekilde etkilediğidir. Bu çalışma pratik rehberlik sağlar: LDpred2 ve iyi tasarlanmış topluluk modelleri büyük Avrupa veri setlerinde en güvenilir tahminleri verme eğilimindedir ve çok kökenli kombinasyonlar daha karmaşık popülasyonlararası modellerden daha iyi performans gösterebilir. Aynı zamanda Afrika kökenli bireylerdeki doğruluk düşüşü, daha büyük ve daha çeşitli genetik çalışmalara acil bir ihtiyaç olduğunu vurguluyor. Birçok yöntemi tek, standartlaştırılmış bir çevrimiçi platformda paketleyerek PGS-hub, dünya çapındaki araştırmacıların poligenik skorlar üretmesini ve karşılaştırmasını kolaylaştırıyor; bu da bu tür skorların tıp alanında adil ve etkili bir şekilde kullanılmasına doğru atılmış önemli bir adım.
Atıf: Chen, X., Wang, F., Zhao, H. et al. Comprehensive benchmarking single and multi ancestry polygenic score methods with the PGS-hub platform. Nat Commun 17, 2014 (2026). https://doi.org/10.1038/s41467-026-68599-7
Anahtar kelimeler: poligenik skorlar, genetik risk tahmini, PGS-hub platformu, çok kökenli genomik, UK Biobank