Clear Sky Science · tr
Lipidomik ve metabolomik verilerinin istatistiksel işlenmesi ve görselleştirilmesinde R ve Python için en iyi uygulamalar ve araçlar
Laboratuvar sayılarının anlaşılır görsellere dönüşmesi neden önemli
Günümüz cihazları artık tek bir kan damlası veya doku örneğinde binlerce küçük molekülü—lipidler ve diğer metabolitleri—ölçebiliyor. Bu ölçümler hastalık riskleri, tedaviye yanıtlar ve vücudumuzun beslenme yaşı veya yaşlanma gibi etkenlere nasıl tepki verdiği hakkında ipuçları taşır. Ancak ham çıktı hazır bir cevap değildir: temizlenmesi, analiz edilmesi ve anlaşılır görsellere dönüştürülmesi gereken büyük bir sayı tablosudur. Bu makale, araştırmacıların bu süreci güvenilir, şeffaf ve yayımlanabilir kalitede grafiklerle gerçekleştirmek için iki popüler programlama dili olan R ve Python'u nasıl kullanabileceklerini açıklar.
Kimyasal ölçümlerden karmaşık veri tablolarına
Lipidomik ve metabolomik çalışmalarda kütle spektrometrisi ve kromatografi, her satırın bir örnek ve her sütunun bir molekül olduğu büyük veri setleri üretir. Bu tablolar nadiren ders kitabı örnekleri gibi düzenlidir. Eksik değerler, aykırı gözlemler ve birkaç molekülün aşırı yüksek düzeyler gösterdiği çarpık dağılımlar içerirler. Konsantrasyonlar birkaç mertebe arasında değişebilir ve yaş, cinsiyet, beslenme, ilaçlar, günlük ritimler ve cihaz kayması ya da parti etkileri gibi teknik sorunlardan etkilenebilir. Uluslararası uzman gruplar örneklerin toplanması, işlenmesi ve raporlanması için kılavuzlar yayınlamıştır, ancak iyi laboratuvar uygulamalarına rağmen, gürültülü arka plandan gerçek biyolojik sinyalleri çıkarmak için dikkatli istatistiksel işlem hâlâ esastır.
Sayıları temizleme ve hazırlama
Sağlıklı ve hasta grupları arasında yapılacak herhangi bir karşılaştırma anlamlı olmadan önce veriler hazırlanmalıdır. Derleme, eksik değerlerin nasıl ortaya çıktığını—rastgele aksaklıklar, cihaz sınırlamaları veya sinyal enterferansı yoluyla—ve ne zaman güvenle göz ardı edilebileceğini, ne zaman yeniden ölçülmesi gerektiğini ve k-en yakın komşu, rastgele ormanlar veya basit düşük değer ikamesi gibi yöntemler kullanılarak nasıl makul şekilde tahmin (impute) edilebileceğini açıklar. Ardından, istenmeyen varyasyonu azaltan normalizasyon stratejileri özetlenir; örneğin kalite kontrol örnekleriyle parti etkilerinin düzeltilmesi veya örnek miktar farklarının ayarlanması gibi. Daha sonra veride sağa çarpık uzun kuyrukları yatıştıran logaritma gibi dönüşümler ve sonraki analizlerde çok değişken bileşiklerin baskın olmasını önlemek için tüm molekülleri karşılaştırılabilir bir düzeye getiren ölçekleme yöntemleri tartışılır. 
İstatistiksel testler ve görsel anlatılar
Veriler uygun şekilde hazırlandıktan sonra çeşitli istatistiksel araçlar devreye girer. Tek tek moleküller için araştırmacılar katlanma değişimlerini hesaplayabilir ve düz t-testi veya Mann–Whitney testi gibi parametrik olmayan karşılıkları gibi klasik testleri kullanarak düzeylerin gruplar arasında farklı olup olmadığını sorgulayabilir. Birden çok grubun karşılaştırıldığı durumlar için ANOVA veya Kruskal–Wallis testi gibi yöntemler tanıtılır ve hangi grupların farklı olduğunu belirlemek için post hoc prosedürler eşlik eder. Bu testlerin gücü, sonuçlar net görselleştirildiğinde açığa çıkar. Makale, kutu grafikleri (çarpık veriler için geliştirilmiş versiyonları dahil), keman grafikleri ve etki büyüklüğü ile istatistiksel anlamlılığı birleştiren volkan grafikleri gibi görselleri vurgular. Lipidler için tüm sınıflar boyunca eş koordineli değişimleri gösteren lipid ağları ve karbon zincir uzunluğu ile doygunluktaki desenleri ortaya koyan yağ asidi zincir grafikleri gibi daha özelleşmiş görseller tanımlanır.
Birden çok değişkende kalıpları görmek
Her örnekte yüzlerce hatta binlerce ölçülen molekül olabileceği için çok değişkenli yöntemler hayati önemdedir. Derleme, temel bileşen analizi (PCA)nin bu karmaşıklığı birkaç yeni eksene sıkıştırarak varyasyonun ana yönlerini yakaladığını, grup ayrımı, parti etkileri veya analitik kararlılık için hızlı kontroller yapılmasını sağladığını açıklar. t-SNE ve UMAP gibi daha gelişmiş doğrusal olmayan yöntemler yüksek boyutlu alanda ince kümelenmeleri ve yapıları ortaya çıkarabilir. Örnekleri sınıflandırmayı amaçlayan durumlar—örneğin hastaları kontrollerden ayırma—için yazarlar Kısmi En Küçük Kareler ve ortogonal uzantısı (PLS-DA ve OPLS-DA) gibi denetimli yaklaşımları tarif eder. Bu yöntemler moleküler profilleri örnek etiketlerine bağlar, özellik seçimini destekler ve genellikle skor grafikleri, yük grafikleri ve alıcı işletim karakteristiği eğrileri ile özetlenir.
R ve Python'da pratik araç setleri
Başlangıç düzeyindekilerin kuramsaldan pratiğe geçmesine yardımcı olmak için makale geniş bir yazılım paketleri ekosistemini tarar. R'de tidyverse ve tidymodels gibi koleksiyonlar veri düzenleme ve modellemeyi kolaylaştırırken, ggplot2 ve ggpubr, ggstatsplot ve tidyplots gibi eklenti paketler yayımlanabilir kalitede şekiller oluşturmayı basitleştirir. Uzmanlaşmış kütüphaneler PCA, kümeleme ve PLS tabanlı modelleri ele alır ve Bioconductor paketleri karmaşık ısı haritaları ve etkileşimli grafikler için destek sağlar. Python'da pandas tablo işlemleri sağlarken matplotlib, seaborn ve plotly görselleştirmeyi, scikit-learn ise geniş bir çok değişkenli yöntem setini kapsar. Makale boyunca yazarlar, okuyucuların iş akışlarını tekrarlayabilmesi ve kendi verilerine uyarlayabilmesi için eşlik eden bir GitBook'ta adım adım örneklerin sunulduğunu vurgular. 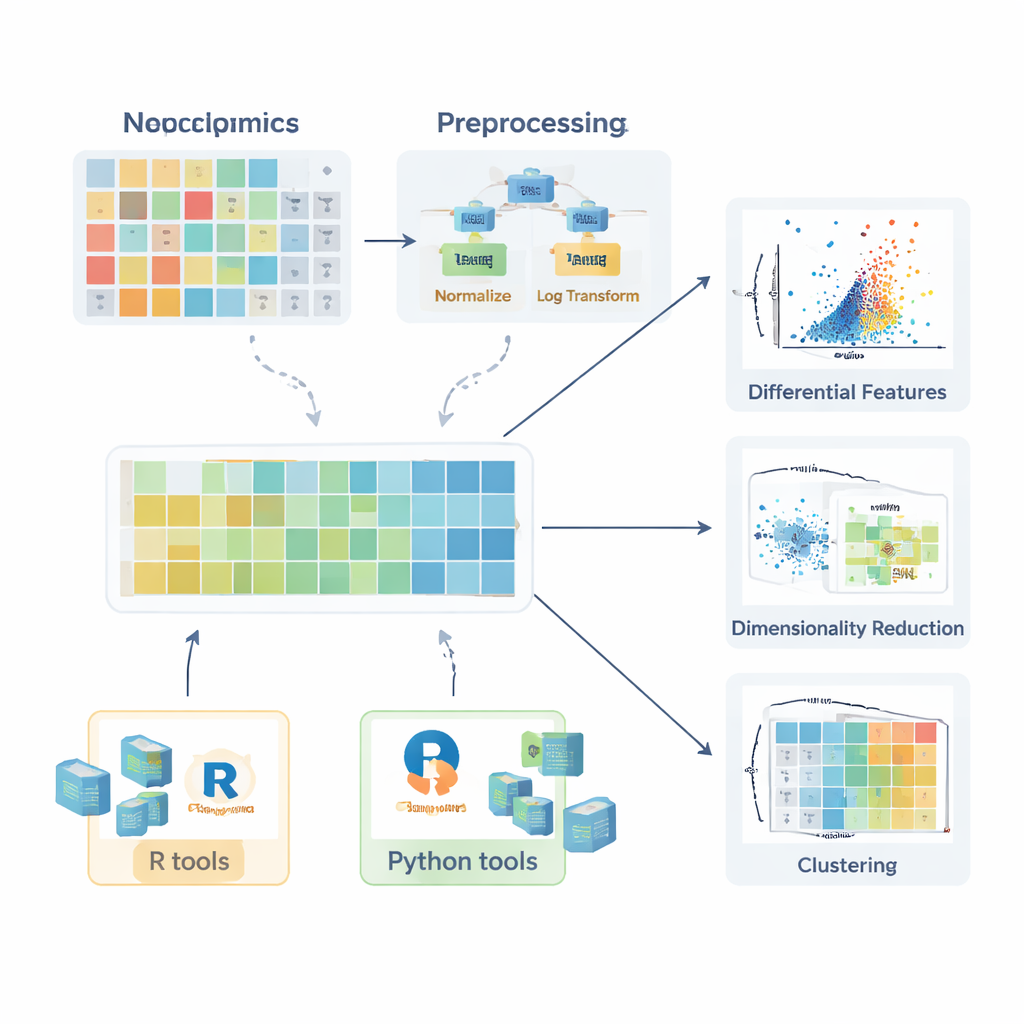
Karmaşık kimyayı güvenilir içgörülere dönüştürmek
Makale, lipidomik ve metabolomik çalışmaların gerçek vaadinin yalnızca güçlü cihazlarda değil, aynı zamanda çıktılarının ne kadar düşünceli işlendiği ve görselleştirildiğinde yattığını sonucuna bağlar. İyi istatistiksel uygulamaları takip ederek, R ve Python'da açık ve iyi belgelendirilmiş araçlar kullanarak ve paylaşılan kod örneklerine dayanarak araştırmacılar sağlam ve tekrarlanabilir iş akışları oluşturabilir. Bu, küçük moleküllerde bulunan kalıpların güvenilir biyobelirteçlere, hastalık mekanizmalarının daha iyi anlaşılmasına ve nihayetinde hastalara daha fazla fayda sağlayacak daha kişiselleştirilmiş tıbbi yaklaşımlara dönüşme olasılığını artırır.
Atıf: Idkowiak, J., Dehairs, J., Schwarzerová, J. et al. Best practices and tools in R and Python for statistical processing and visualization of lipidomics and metabolomics data. Nat Commun 16, 8714 (2025). https://doi.org/10.1038/s41467-025-63751-1
Anahtar kelimeler: lipidomik, metabolomik, veri görselleştirme, R programlama, Python