Clear Sky Science · tr
Yetişkin olmayan ürünlerin ıslahı için makine öğrenmesi ve genomik uygulamaları
Büyük Potansiyele Sahip Gizli Ürünler
Afrika, Asya ve Latin Amerika genelinde milyonlarca insan sorgum, teff, manyok (cassava) ve yer fıstığı gibi sözde “yetim ürünlere” dayanıyor. Bu bitkiler nadiren manşetlere çıkar, ancak genellikle buğday veya pirinç gibi küresel temel ürünlere göre ısı, kuraklık, zararlılar ve zayıf toprak koşullarına daha iyi dayanırlar. Bu derleme makalesi, genomik ve makine öğrenmesi adlı iki güçlü aracın bu göz ardı edilmiş ürünlerin potansiyelini nasıl açığa çıkarabileceğini inceliyor; yerel gıda güvenliğini artırırken aynı zamanda dünya çapındaki ana ürünleri güçlendirebilecek değerli genleri de sağlayabilir.
Neden Göz Ardı Edilmiş Ürünler Önemli?
Yetim ürünler bazen “ihmal edilmiş” veya “az kullanılan” olarak adlandırılır çünkü büyük ihracat ürünlerine kıyasla çok daha az bilimsel ve ticari ilgi görmüşlerdir. Yine de birçok topluluk için besleyici ana besin kaynaklarıdır ve sıklıkla diğer bitkilerin başarısız olduğu zorlu, marjinal ortamlarda yetiştirilirler. Buğday veya pirinçten farklı olarak, çoğu yetim ürün Yeşil Devrim’in ıslah ilerlemelerinden ve işaretçi destekli ıslah veya genom düzenleme gibi modern araçlardan mahrum kaldı. African Orphan Crops Consortium gibi genomik projeler DNA’larını dizilemeye ve kataloglamaya başladı, ancak ham genetik veriyi pratik iyileştirmelere dönüştürmek hâlâ büyük bir zorluktur.
Bilgisayarlara Bitkileri Okutmak
Makine öğrenmesi—büyük veri kümelerinden desenleri öğrenen bilgisayar yöntemleri—zaten ana ürünlerde ıslahı dönüştürüyor. Genom dizileri, hava ve toprak kayıtları, sensör okumaları ve drone veya akıllı telefonlardan gelen görüntüleri birleştirerek algoritmalar verim, hastalık direnci veya tane kalitesi gibi karmaşık özellikleri tahmin edebilir. Karar ağaçlarından derin sinir ağlarına kadar farklı model türleri farklı ortamlarda üstünlük sağlar. Bazen geleneksel istatistiksel araçlar hâlâ derin öğrenmeyi yakalar veya geçer, ancak genel olarak birden fazla veri kaynağını ve modeli harmanlamak, ıslahçılara tek bir yaklaşımdan daha doğru ve tutarlı tahminler sunma eğilimindedir.
Kıt Veriden En İyi Şekilde Yararlanmak
Yetim ürünler için temel engel bilgisayar gücü değil, veri kıtlığıdır. Yalnızca birkaç halka açık genomik ve görüntü koleksiyonu var ve az sayıda olanlar bile geleneksel makine öğrenmesi boru hatları için yeterince büyük değil. Buna rağmen ilk göstermeler ümit verici. Örneğin sorgumda, derin öğrenme modelleri tane fotoğraflarını kullanarak protein ve antioksidan düzeylerini yüksek doğrulukla tahmin etti; bu, laboratuvar testlerine göre daha ucuz bir alternatif sundu. Başka bir örnekte, yakın kızılötesi ışık ölçümleri ve derin öğrenme, Perilla bitkisindeki (bir bitki türü) besin özelliklerini tahmin etmek için kullanıldı. Derleme, yetim ürünler için genomlar, görüntüler ve kimyasal profiller içeren paylaşılan veri tabanlarının oluşturulmasının bu tür araçların etkisini hızla artıracağını savunuyor.
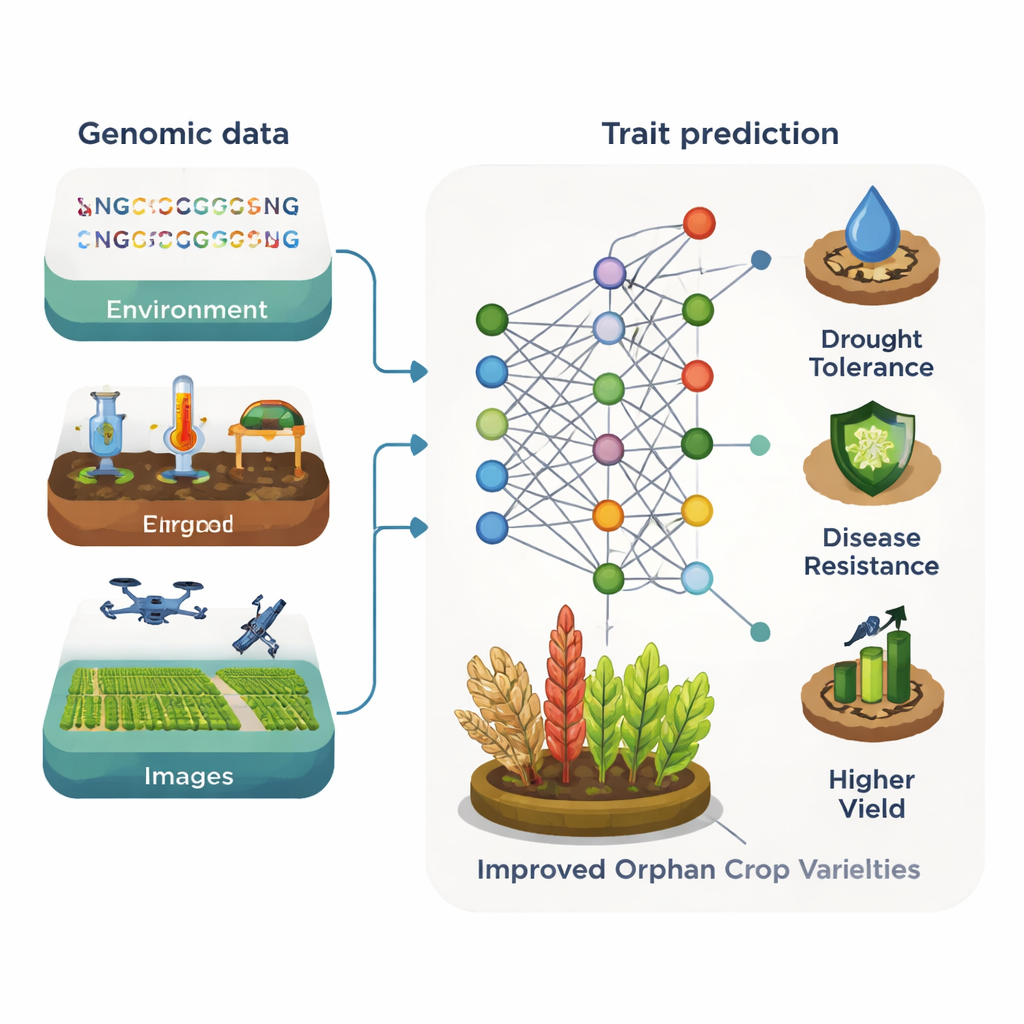
Büyük Ürünlerden Bilgi Ödünç Almak
Makalede merkezi bir fikir türler arasındaki “bilgi aktarımı”dır. Birçok yetim ürün, geniş DNA parçalarını ve benzer genleri paylaşarak ana ürünlerin yakın akrabasıdır. Makine öğrenmesi modelleri bu akrabalıktan yararlanabilir. Önce iyi çalışılmış bitkiler üzerinde eğitilmiş araçlar—örneğin Arabidopsis veya mısır—daha az bilinen bir akrabada bitki boyu, tohum kalitesi veya stres toleransı gibi özellikler için genleri belirlemede yardımcı olabilir. Başlangıçta insan veya bitki genomları için geliştirilen büyük dil modelleri de DNA’yı bir tür metin olarak ele alabilir ve düzenleyici bölgeleri veya önemli genleri işaretleyen desenleri öğrenebilir. Zengin veri kümeleri üzerinde eğitildikten sonra bu modeller, sınırlı yetim ürün verisiyle ince ayar yapılabilir; böylece gen işlevini tahmin etmek, genom düzenleme hedeflerini vurgulamak ve daha verimli ıslahı yönlendirmek mümkün olur.
Algoritmalardan Tarlalara ve Çiftçilere
Yazarlar teknolojinin tek başına yetim ürünleri dönüştürmeyeceğini vurguluyor. İlerleme, yerel bilim insanlarına yatırım, küçük çiftçilerle ortaklıklar ve toplulukların yeni çeşitlerden fayda sağlamasını güvence altına alan politikalar gerektirir. Çiftçilerin kendi arazilerinde çeşitleri doğrudan test ettiği vatandaş bilimi yaklaşımları, makine öğrenmesi için değerli veriler üretebilir ve araştırmayı yerel ihtiyaçlara ve tatlara uygun hale getirebilir. Finansman sınırlı olduğu için makale dengeli bir strateji öneriyor: düşük maliyetli geleneksel ıslah ve agronomi ile dikkatle hedeflenmiş genomik ve makine öğrenmesi projelerini birleştirin ve araçları ile verileri ülkeler arasında ve yetim ile ana ürünler arasında paylaşın.
Bu, Gıda Geleceğimiz İçin Ne Anlama Geliyor?
Basitçe söylemek gerekirse makale, daha akıllı bilgisayarların ve daha iyi genetik bilginin bugünün “unutulmuş” ürünlerini yarının iklime dayanıklı temel ürünlerine dönüştürmeye yardımcı olabileceği sonucuna varıyor. Büyük ürünlerden öğrenip bu dersleri daha küçüklerine uygulayarak—ve sonra bulguları ters yönde geri besleyerek—makine öğrenmesi ve genomik dayanıklı, besleyici çeşitlerin bulunmasını hızlandırabilir. Düşünceli politika ve çiftçi topluluklarıyla gerçek iş birliğiyle desteklenirse, bu yaklaşım diyetleri iyileştirebilir, iklim değişikliğine karşı direnci güçlendirebilir ve dünyanın tarımsal araç setini dar bir temel ürünü yelpazesinin ötesine genişletebilir.
Atıf: MacNish, T.R., Danilevicz, M.F., Bayer, P.E. et al. Application of machine learning and genomics for orphan crop improvement. Nat Commun 16, 982 (2025). https://doi.org/10.1038/s41467-025-56330-x
Anahtar kelimeler: yetim ürünler, makine öğrenmesi, genomik, bitki ıslahı, gıda güvenliği