Clear Sky Science · tr
Yirmi Dört Tarih antik-modern sözcük türü etiketli korpusunun oluşturulması
Yapay Zeka Çağında Neden Eski Kronikler Önemli?
İki milenyumdan fazla bir süredir Çinli tarihçiler savaşları, sarayları, kıtlıkları ve günlük yaşamı Yirmi Dört Tarih adı verilen devasa dizide kaydetti. Bugün bu klasikler yalnızca akademisyenler tarafından değil, bilgisayarlar tarafından da yeniden keşfediliyor. Bu çalışma, araştırmacıların bu eski kronikleri ve onların modern Çince çevirilerini nasıl dikkatle etiketlenmiş bir dil veritabanına dönüştürdüğünü anlatıyor. Bu kaynak, yapay zekânın tarihsel metinleri daha doğru okumasına, çevirmesine ve analiz etmesine yardımcı olabilir—ve uzak geçmişi halk için çok daha erişilebilir kılabilir.
Tozlu Ciltlerden Dijital Metne
Proje temel ama göz korkutucu bir görevle başlıyor: milyonlarca basılı karakteri temiz, doğru dijital metne dönüştürmek. Ekip iki kaynağa dayandı—Yirmi Dört Tarih’in kesin modern baskısı ve büyük bir çevrimiçi koleksiyon—optik karakter tanıma sistemine besleme yapmak için. Ardından karışık pasajları titizlikle çıkardılar, yanlış okunan karakterleri düzelttiler ve sayfa başlıkları ile altbilgiler gibi gürültüyü temizlediler. Sonuç, orijinal kitaplara sadık kalan ancak hesaplamalı analiz için hazır durumda olan antik Çince ve modern Çince olmak üzere paralel dosya setiydi. 
Antik Cümleleri Modern Cümlelerle Eşleştirmek
Dilin zaman içinde nasıl değiştiğini karşılaştırmak amaçlandığı için, eski ve yeni sürümleri cümle cümle hizalamak şarttı. Araştırmacılar önce paragrafları, sonra da bunları karşılık gelen cümlelere bölmek için özel hizalama yazılımları kullandı. Otomatik araçlar ağır iş yükünü üstlendi, ancak antik Çince dilbilgisi modern Çinceden çok farklı olabildiğinden insan uzmanlar her önerilen çifti gözden geçirmek zorunda kaldı. Yazılımın hata yaptığı—düşünceyi yanlış yerde böldüğü veya bir karakteri yanlış okuduğu—durumlarda, betimleyiciler orijinal taranmış sayfaları kontrol edip dijital metni düzelterek her antik cümlenin modern muadiliyle düzgünce hizalanmasını sağladı.
Bilgisayarlara Dilbilgiyi Öğretmek
Basit transkripsiyonun ötesinde, projenin özü dilbilgisel etiketlemedir. Hem antik hem modern metinlerdeki her sözcük, örneğin isim, fiil veya zaman sözcüğü olup olmadığına işaret eden bir sözcük türü etiketiyle işaretlendi. Antik Çince için tek bir standart bulunmadığından, ekip sistemlerini modern ulusal yönergelere dayandırdı ve sonra bunları eski kullanım biçimlerine uyarladı. “Yaşatmak için neden olma” veya “ülke uğruna ölme” gibi özgün antik fiil kullanımlarına özel bir etiket içeren 22 etiketlik bir şema geliştirdiler. Antik metin dil modeli ve sıra-etiketleme katmanlarına dayalı özelleştirilmiş bir sinir ağı ilk etiketleri üretti; bunlar daha sonra iyi eğitilmiş çok sayıda yüksek lisans öğrencisinden oluşan bir ekip tarafından kontrol edilip düzeltildi. Etiketleyiciler arasındaki sıkı uyum testleri çok yüksek tutarlılık gösterdi ve nihai etiketlenmiş korpusun hem büyük hem güvenilir olduğunu doğruladı.
Yeni Merceğin Ortaya Çıkardıkları
Etiketlenmiş korpus yerinde olduğunda, yazarlar bunun görünür kıldığı bazı kalıpları inceledi. Antik Çince’de tek karakterli sözcükler hakimdir; bu, ünlü derecede sıkıştırılmış bir yazı stilini yansıtırken, modern Çince iki karakterli sözcükleri tercih eder. En yaygın antik öğeler “之” ve “以” gibi küçük dilbilgisel partiküllerdir; öte yandan fiiller ve sıradan isimler her iki dönemde de sözcüklerin yaklaşık yarısını oluşturur. Veriler ayrıca hangi sözcüklerin birlikte görünme eğiliminde olduğunu da gösteriyor—örneğin görevliler, ordular veya diplomatik görevleri tanımlayan yapılar. Antik–modern eşleştirmeleri karşılaştırarak ekip işlevlerin zaman içinde nasıl kaydığına dair iz sürdü: bazı eski edatlar ve zarflar artık tam modern fiillere karşılık geliyor ve bazı fiiller sabit unvanlar veya hukuki terimler haline gelmiş. Bir vaka çalışması tüm yer adlarını çıkarıp bunların farklı hanedanlıklarda nerede kümelendiğini haritalandırdı; bu da siyasi ve ekonomik merkezlerin kuzeybatıdan Aşağı Yangtze bölgesine ve ötesine nasıl kaydığını ortaya koydu. 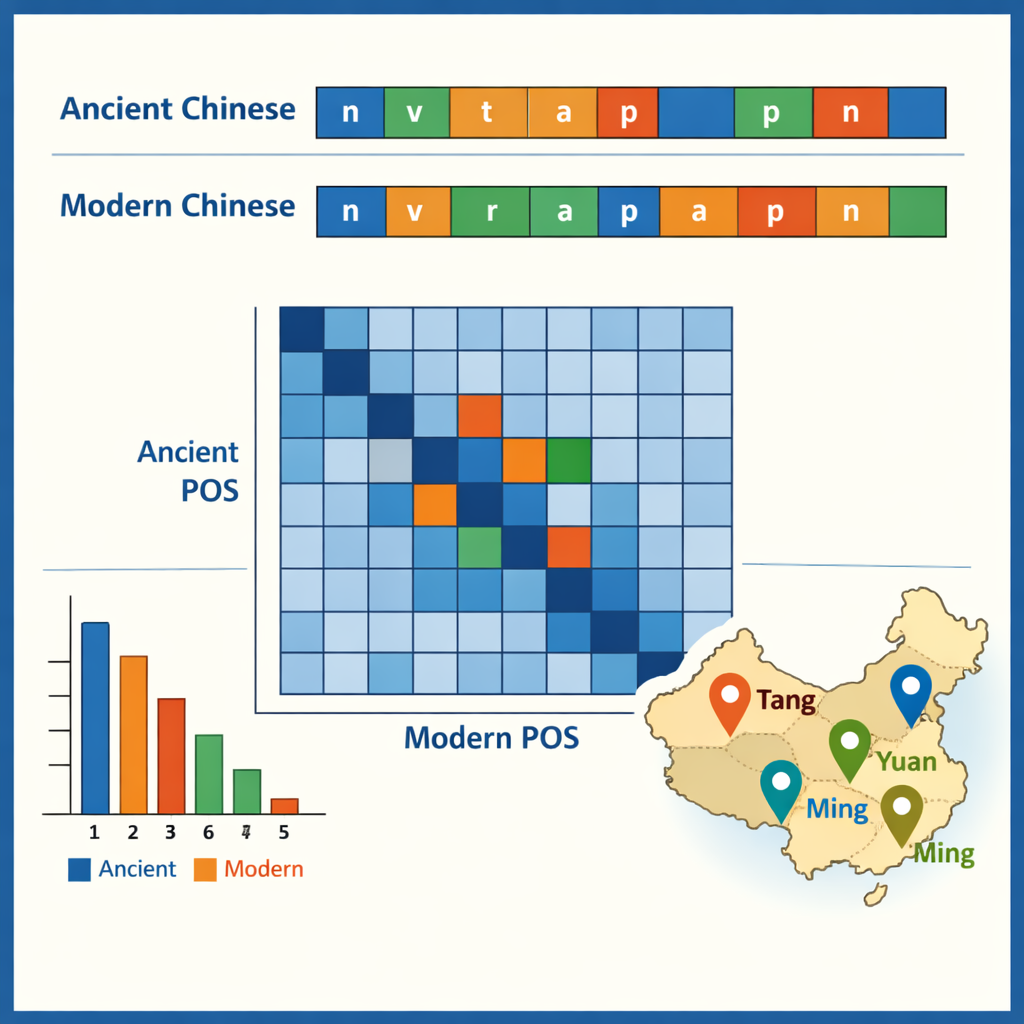
Geçmişi Dijital Geleceğe Taşımak
Basitçe söylemek gerekirse, bu proje klasik düzyazı duvarını hem insanlar hem makineler tarafından gezilebilecek yapılandırılmış verilere dönüştürüyor. Tarihçiler ve dilbilimciler için bu, sözcüklerin, dilbilgisinin ve hatta devlet sınırlarının yüzyıllar boyunca nasıl evrildiğini izlemek için güçlü bir araç sağlıyor. Yapay zekâ geliştiricileri için, klasik Çinçesini karakter karışıklığı olarak ele almak yerine gerçekten işleyebilen dil modelleri oluşturmak üzere yüksek kaliteli eğitim materyali sunuyor. Öğrenciler ve genel okuyucular için ise antik ve modern metnin cümle-cümle eşleştirilmesi klasikleri okuma bariyerini düşürüyor. Yirmi Dört Tarih’i dikkatle etiketleyip hizalayarak yazarlar geçmişin el yazması parşömenlerinden günümüzün ve geleceğin akıllı sistemlerine bir köprü kurmuş oldu.
Atıf: Ye, W., Xu, Q., Zhao, X. et al. Construction of the twenty-four histories ancient-modern part-of-speech tagged corpus. npj Herit. Sci. 14, 97 (2026). https://doi.org/10.1038/s40494-026-02309-w
Anahtar kelimeler: antik Çin korpusu, sözcük türü etiketleme, dijital beşeri bilimler, paralel metinler, tarihsel dil değişimi