Clear Sky Science · tr
Japonya’da kazılan antik cam boncukların sınıflandırılması için bilgi damıtımıyla çoklu görünüm görüntü birleştirme
Boncuklar Zaman Kapsülleri Gibi
Bin yılı aşkın bir süredir, küçük cam boncuklar Akdeniz ve Hindistan’dan Japon takımadasına ticaret yolları boyunca taşındı. Bugün bu renkli parçalar Japonya’da çıkarılan en yaygın arkeolojik buluntular arasında—600.000’den fazlası bulundu—ancak bunların tam olarak nerede üretildiğini belirlemek genellikle yavaş, pahalı kimyasal testler ve uzman gözü gerektirir. Bu çalışma basit ama güçlü bir soru soruyor: sıradan fotoğraflar ve modern yapay zeka laboratuvarın yerini alabilir mi, arkeologların bu boncukların izini hızla ve zararsız şekilde sürmesine yardımcı olabilir mi?
Neden Antik Cam Önemli
Cam boncuklar yalnızca takı değil; Avrasya boyunca uzun mesafeli temasların ipuçlarıdır. Farklı bölgeler, hammadde ve renklendirici karışımlarında farklılıklar kullanmış; bu da uzmanların boncukları Doğu Asya, Hindistan, Güneydoğu Asya, Orta Asya ve Akdeniz gibi bölgelere bağlı ailelere ayırırken kullandığı kimyasal “imzalar” oluşturur. Geleneksel kaynak belirleme çalışmaları kimyasal bileşenleri ölçen cihazlara ve biçim, renk ve üretim izlerini büyüteç altında inceleyen uzmanlara dayanır. Bu yaklaşımlar antik ticaret hakkında zengin hikâyeler ortaya koydu, ancak Japonya’daki müzeler ve depolarda saklanan yüzbinlerce kırılgan nesne için ölçeklenmesi zordur.
Laboratuvar Ölçümlerinden Basit Fotoğraflara
Bu darboğazı aşmak için yazarlar sadece boncukların görüntülerini kullanan bir yöntem araştırıyor. Camdan bir parçacığı çözerek analiz yapmak yerine, her bonuğun iki açıda fotoğrafını çekiyorlar: yüzeyi ve halka şeklindeki deliği ve genel renk desenlerini gösteren üst görünüş ve kalınlık ve profili gösteren yan görünüş. Bu çift bakış açısı, insan uzmanların nesneleri ellerinde döndürerek yüzey dokusu ve formdaki ince değişiklikleri yakalamasına benzer. Amaç iddialı: sadece bu fotoğraflara dayanarak, bir bilgisayar her boncuğu arkeologların zaten kullandığı 16 yerleşik kimyasal ve bölgesel gruptan birine otomatik olarak atayabilir mi?
Makinalara Uzmanlar Gibi Görmeyi Öğretmek
Araştırma ekibi MidNet adlı hibrit bir yapay zeka sistemine yöneliyor. Bu sistem iki önde gelen görüntü analiz stratejisini birleştiriyor. Birincisi, küçük çukurlar, renk sıyrıkları veya yüzey hasarı gibi ince ayrıntıları yakalamada özellikle iyi olan konvolüsyonel sinir ağı. Diğeri ise renkler ve biçimlerin tüm boncuk çapında nasıl ilişkilendiğini görmek üzere tasarlanmış bir görsel dönüştürücü (vision transformer). MidNet her iki görüntüyü (üst ve yan) her iki model türünden geçiriyor ve sonra onların “aynı görüşte” olmasını teşvik ediyor. Eğitim sırasında her model yalnızca doğru etiketten değil, aynı zamanda partnerinin tahminlerinden ve alternatif bakış açısından da öğreniyor. Bu karşılıklı öğrenme, sistemin belirli bir açıya veya model türüne özgü tuhaflıklara takılma riskini azaltıp kökenle ilişkili kalıcı görsel özelliklere odaklanmasını sağlıyor.
Düzensiz ve Kusurlu Verilerle Çalışmak
MidNet’in arkasındaki veri kümesi, sınıfları daha önce uzman incelemesi ve kimyasal analizle belirlenmiş 3.434 boncuk görüntüsünden oluşuyor. Bazı boncuk türleri bol iken, diğerleri yalnızca birkaç örnekle temsil ediliyor—arkeolojide sık görülen bir sorun. Yapay zekânın en yaygın sınıfları tercih etmesini önlemek için araştırmacılar iki hile kullandı. Birincisi, çok nadir türler için modern bir görüntü sentezi tekniği kullanarak ek eğitim görüntüleri ürettiler; böylece nesnelere dokunmadan inandırıcı varyasyonlar yarattılar. İkincisi, sistemi küçük hasar veya aydınlatma farklarına karşı daha az hassas hale getirmek için eğitim fotoğraflarını kasıtlı olarak biraz renklendirip, kırparak veya küçük bölgeleri gizleyerek bozdular. Ardından yöntemin görülmemiş boncuklara ne kadar iyi genelleşeceğini görmek için titiz bir çapraz doğrulama prosedürü ile performansı değerlendirdiler.
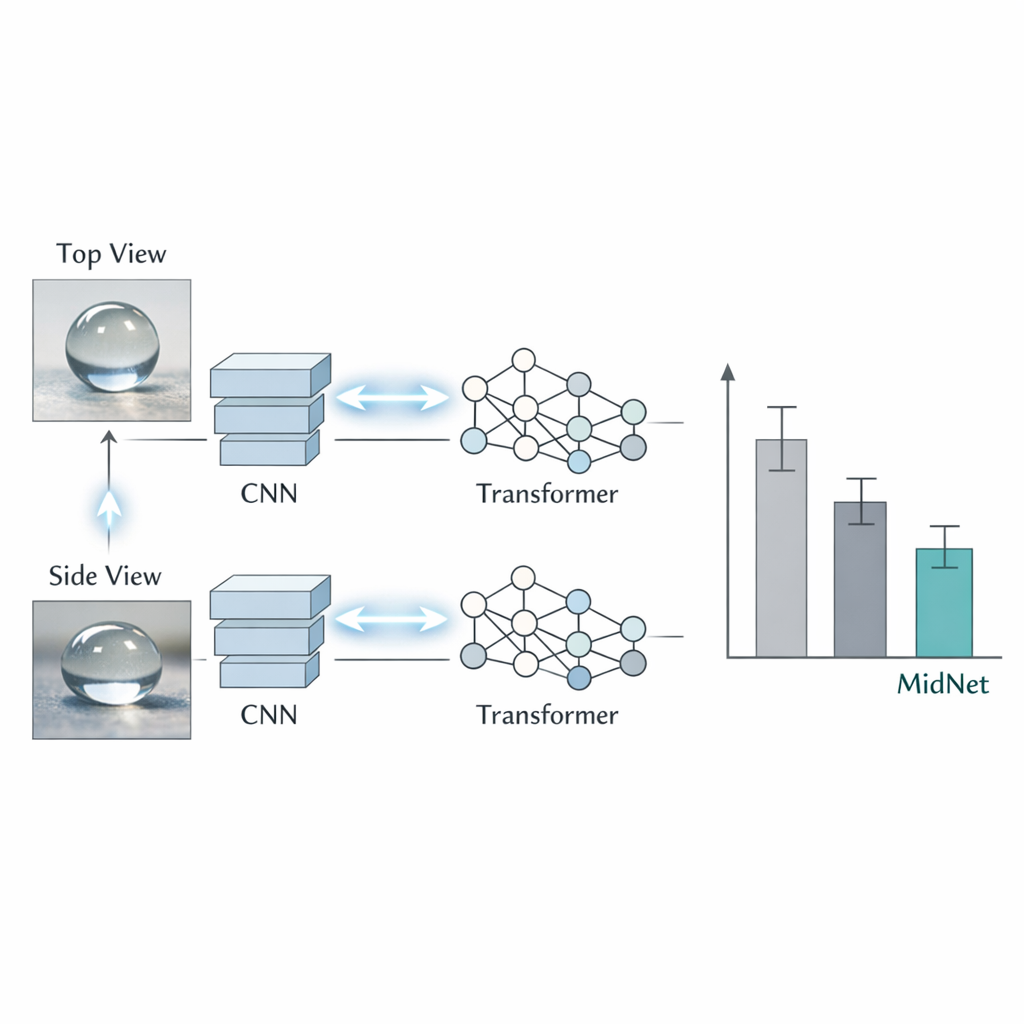
Sistem Ne Kadar İyi Çalışıyor?
Araştırmacılar hibrit MidNet’i daha standart görüntü modelleriyle karşılaştırdıklarında, hem üst hem yan görünüşün her zaman yardımcı olduğunu; iki açının tamamlayıcı ipuçları yakaladığını gördüler. Ham doğruluk açısından MidNet, binlerce örnekten sadece birkaç boncuk farkıyla en iyi rakip yönteme eşit performans gösterdi, ancak farklı test bölmelerinde en tutarlı davranışı sergiledi. Başka bir deyişle, performansı bir deneyden diğerine daha az değişti; bu, eğitim kümesinde hangi özel boncukların bulunduğuna karşı daha az duyarlı olduğunu gösteriyor—nadir eser türleriyle çalışırken kritik bir özellik. Yöntem hâlâ uzmanların bile ayırt etmekte zorlandığı bazı benzer görünen kategorilerde zorlanıyor; bu da fotoğraflarda neredeyse algılanamaz farkların bulunduğu “ultra-ince ayrıntılı” bir sorun olduğuna işaret ediyor.
Gelecek Kazılar İçin Anlamı
Bu çalışma, dikkatli fotoğrafçılık ve gelişmiş görüntü analizinin birçok antik cam boncuğun nerede yapıldığını güvenilir şekilde tahmin edebileceğini; kimyalarını incelemeden bunu yapabileceğini gösteriyor. Arkeologlar için bu, laboratuvarı olmayan küçük müzeler veya saha çalışmalarında bile büyük koleksiyonların hızlı, düşük maliyetli ve tahribatsız şekilde sınıflandırılmasının yolunu açıyor. Zorlu vakalar hâlâ uzman değerlendirmesi ve kimyasal test gerektirecek olsa da, MidNet benzeri bir sistem rutin sınıflandırmanın çoğunu üstlenebilir, olağan dışı parçaları vurgulayabilir ve camın kıtalar ve yüzyıllar boyunca hareketini izleyen geniş dijital arşivleri destekleyebilir. Kısacası, çalışma yapay zekânın insan tarihini, birer birer küçük boncuklar aracılığıyla, yeniden inşa etmeye nasıl yardımcı olabileceğini gösteriyor.
Atıf: Fukuchi, T., Tamura, T. & Fukunaga, K. Multi-view image fusion using knowledge distillation for classification of ancient glass beads excavated in Japan. npj Herit. Sci. 14, 41 (2026). https://doi.org/10.1038/s40494-026-02305-0
Anahtar kelimeler: arkeoloji, cam boncuklar, makine öğrenimi, görüntü tabanlı sınıflandırma, kültürel miras