Clear Sky Science · sv
Tematisk analys med öppen källkodsbaserad generativ AI och maskininlärning: en ny metod för induktiv utveckling av kvalitativa kodböcker
Varför detta spelar roll för vardagliga frågor
När människor fyller i enkäter eller svarar på intervjufrågor lämnar de efter sig rika berättelser om arbete, skola, hälsa eller samhällsliv. Att läsa några dussin sådana svar är enkelt; att tolka tusentals är det inte. Den här artikeln beskriver ett nytt sätt för forskare att använda öppen källkodsbaserad artificiell intelligens för att hjälpa till att sålla genom stora mängder skriftliga kommentarer och lyfta fram huvudidéerna, samtidigt som människor behåller tolkningsansvaret. Målet är att göra noggrann, nyanserad kvalitativ forskning möjlig i de skalor som vanligtvis är reserverade för stordata-statistik.
Ett smartare sätt att läsa tusentals kommentarer
Författarna fokuserar på en populär ansats inom samhällsvetenskapen kallad tematisk analys, där forskare läser text och söker efter återkommande mönster eller ”teman” som besvarar deras forskningsfrågor. Traditionellt innebär detta att man långsamt kodar varje kommentar för hand och bygger en kodbok—en strukturerad lista över teman och under-teman. Den processen kan fungera väl för några dussin intervjuer, men den blir överväldigande när det finns tiotusentals öppna svar. Artikeln ställer frågan: kan fritt tillgängliga generativa textmodeller och andra öppna verktyg hjälpa till med de tidiga, repetitiva delarna av detta arbete utan att ersätta mänskligt omdöme?
Introduktion av GATOS-arbetsflödet
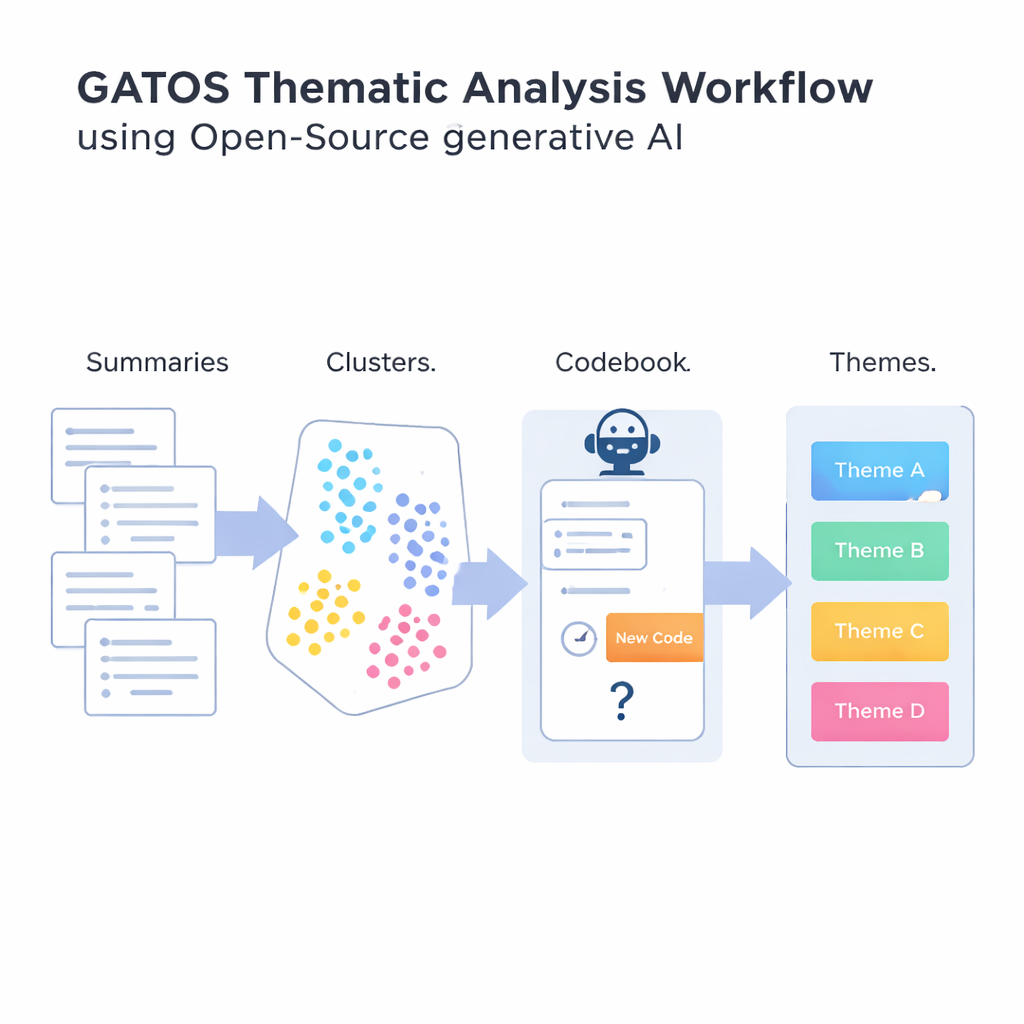
För att besvara den frågan introducerar författarna Generative AI-enabled Theme Organization and Structuring-arbetsflödet, eller GATOS. Detta arbetsflöde kedjar ihop flera steg. Först läser en öppen källkodsbaserad språkmodell individuella svar och skriver korta, fokuserade sammanfattande punkter av vad varje person uttrycker. Nästa verktyg omvandlar dessa sammanfattningar till numeriska representationer så att en dator kan jämföra och gruppera liknande idéer. Dessa sammanfattningar klustras i grupper som sannolikt speglar delade teman, till exempel oro för balans mellan arbete och privatliv eller frustration över otydlig kommunikation.
Låta AI föreslå, men inte översvämma, nya idéer
Det mest nyskapande steget kommer när systemet börjar bygga en utkast-kodbok. För varje kluster av relaterade sammanfattningar granskar en annan generativ modell idéerna i det klustret och de koder som redan finns i kodboken. Den resonerar sedan kring om en genuint ny kod behövs eller om befintliga koder räcker. Om en ny vinkel dyker upp—till exempel ”pålitliga verktyg för videokonferens” som en specifik oro—föreslår den en kort etikett och definition som läggs till. Om inte, väljer den att återanvända det som redan finns. Ett slutligt steg grupperar relaterade koder i bredare teman och skapar en strukturerad karta från råa kommentarer till organiserade insikter. Genomgående ligger fokus på att undvika en översvämning av nästan identiska koder samtidigt som subtila skillnader i människors upplevelser fångas upp.
Testa metoden med realistiska simulerade data
Eftersom verkliga studier sällan kommer med ett känt ”facit” testade teamet GATOS med syntetiska (datorgenererade) data där de dolda temana var kända i förväg. De skapade tre stora, livlika datamängder: kamratåterkoppling om lagarbete, åsikter om etisk kultur på arbetsplatsen och uppfattningar om att återvända till kontoret efter COVID-19-pandemin. För varje datamängd definierade de först åtta teman och flera under-teman, och använde sedan en språkmodell för att skriva hundratals realistiska svar från olika personor, såsom fackmedlemmar, chefer eller studenter. Efter att ha kört GATOS på dessa dataset jämförde mänskliga granskare de AI-genererade temana med de ursprungliga, dolda under-temana för att se hur väl de överensstämde.
Hur väl fungerade det, och vilka är kompromisserna?
I samtliga tre testfall återvann arbetsflödet de flesta av de ursprungliga under-temana ganska nära: majoriteten hade åtminstone en stark motsvarighet, och endast ett litet fåtal saknade en bra motpart. Viktigt är att systemet, när det granskade mer data, föreslog färre nya koder, vilket tyder på att det lärde sig att återanvända befintliga idéer snarare än att uppfinna ändlösa variationer. Författarna hävdar att denna typ av öppen källkodsbaserade, lokalt körbara upplägg kan lindra integritetsbekymmer och göra det lättare för olika forskningsteam att replikera varandras arbete. Samtidigt betonar de att syntetiska data är enklare än många verkliga situationer, att arbetsflödet fortfarande kan skapa överlappande koder, och att mänskliga forskare fortfarande behövs för att förfina, tolka och bedöma den slutliga kodboken.
Vad detta betyder för icke-experter
För läsare utanför akademin är slutsatsen att öppen källkods-AI kan hjälpa samhällsvetare och andra forskare att lyssna på betydligt fler människor utan att reducera deras ord till grova siffror. Istället för att ersätta mänskliga analytiker fungerar GATOS-arbetsflödet som en mycket snabb, mycket organiserad assistent som föreslår mönster och utkast till etiketter, medan människorna avgör vad dessa mönster verkligen betyder. Om vidare studier bekräftar dessa resultat på verkliga data kan verktyg som GATOS göra det enklare att basera arbetsplatspolicyer, utbildningsprogram och offentliga beslut på hela rikheten i vad människor faktiskt säger, inte bara på flervalsfrågor i enkäter.
Citering: Katz, A., Fleming, G.C. & Main, J.B. Thematic analysis with open-source generative AI and machine learning: a new method for inductive qualitative codebook development. Humanit Soc Sci Commun 13, 209 (2026). https://doi.org/10.1057/s41599-026-06508-5
Nyckelord: kvalitativ dataanalys, tematisk analys, generativ AI, öppen källkod språkmodeller, metoder för samhällsvetenskaplig forskning