Clear Sky Science · sv
Att överbrygga gapet mellan beräkning och experiment: utnyttja stora språkmodeller för att prioritera Alzheimers‑terapier baserat på jämförelse av inlärningsmodeller
Varför detta är viktigt för familjer och patienter
Alzheimers sjukdom berövar människor minnet, självständigheten och livskvaliteten, men verkligt effektiva behandlingar är fortfarande sällsynta. Den här studien undersöker ett snabbare sätt att hitta nya behandlingar genom att använda redan befintliga läkemedel, genom att kombinera kraftfulla datorbaserade modeller med en stor språkmodell — samma typ av AI som nu används i vardagliga chattrobotar — för att sålla i enorma mängder medicinska data och forskningsartiklar. Målet är att minska en lång lista av möjliga läkemedel till ett litet, realistiskt urval som forskare och läkare faktiskt kan testa på patienter.
Återanvända gamla läkemedel för ett nytt ändamål
Att utveckla ett helt nytt läkemedel från grunden kan ta mer än ett decennium och kosta miljarder dollar, utan någon garanti för framgång. Ett alternativ är ”läkemedelsomvandling” (drug repurposing), som söker nya användningsområden för läkemedel som redan är godkända för andra tillstånd, såsom Parkinson eller depression. Eftersom dessa läkemedel har kända säkerhetsprofiler kan de ofta gå snabbare in i kliniska prövningar för Alzheimer. Men moderna datorbaserade metoder som genomsöker biologiska databaser och medicinsk litteratur genererar nu enorma listor med kandidater — långt fler än forskare rimligen kan utvärdera manuellt — vilket skapar en ny flaskhals i processen.
Att föra samman flera smarta modeller
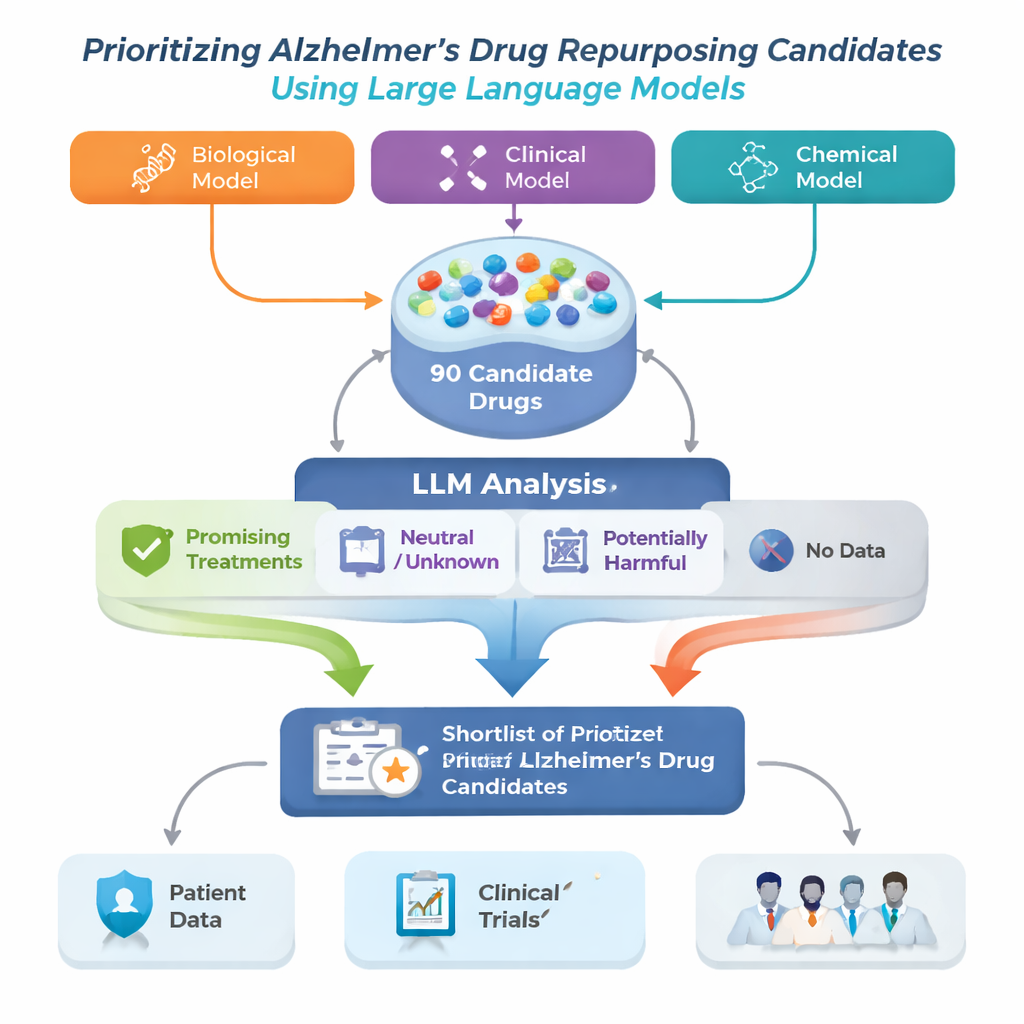
Forskargruppen angrep problemet genom att bygga ett ramverk för läkemedelsomvandling vid Alzheimer som börjar med tre olika avancerade datorbaserade modeller. Varje modell granskar en stor biomedicinsk ”karta” kallad en kunskapsgraf, som länkar sjukdomar, läkemedel, gener och andra medicinska begrepp, och föreslår läkemedel som eventuellt kan hjälpa vid Alzheimer. Eftersom varje modell upptäcker mönster på olika sätt överlappar deras listor inte helt. Författarna kombinerade de 30 främsta förslagen från varje modell till en gemensam pool om 90 kandidatläkemedel, och använde sedan en stor språkmodell (LLM) som en automatiserad men försiktig granskare som läser publicerade studier för varje läkemedel och bedömer om bevisen verkar hjälpsamma, neutrala eller skadliga för Alzheimer.
Hur AI:n läser medicinsk litteratur
För varje kandidatläkemedel hämtade systemet upp till 200 vetenskapliga abstrakt från PubMed samt detaljerade läkemedelsbeskrivningar från en läkemedelsdatabas. LLM:en instruerades att basera sin bedömning endast på den text som visades för den, och att märka varje abstrakt som positivt, neutralt eller negativt för Alzheimers‑behandling. Dessa etiketter omvandlades sedan till enkla poäng: andelen abstrakt som var positiva, neutrala eller negativa. Med två uppsättningar regler — en striktare som krävde klart positiva bevis, och en mer förlåtande som flaggade även antydningar om nytta — sorterade ramverket läkemedel i fyra grupper: lovande behandlingar, potentiellt skadliga, oklara eller neutrala, och läkemedel utan några Alzheimers‑relaterade artiklar alls. Den sistnämnda gruppen, även om den är lite studerad, kan rymma särskilt nya möjligheter.
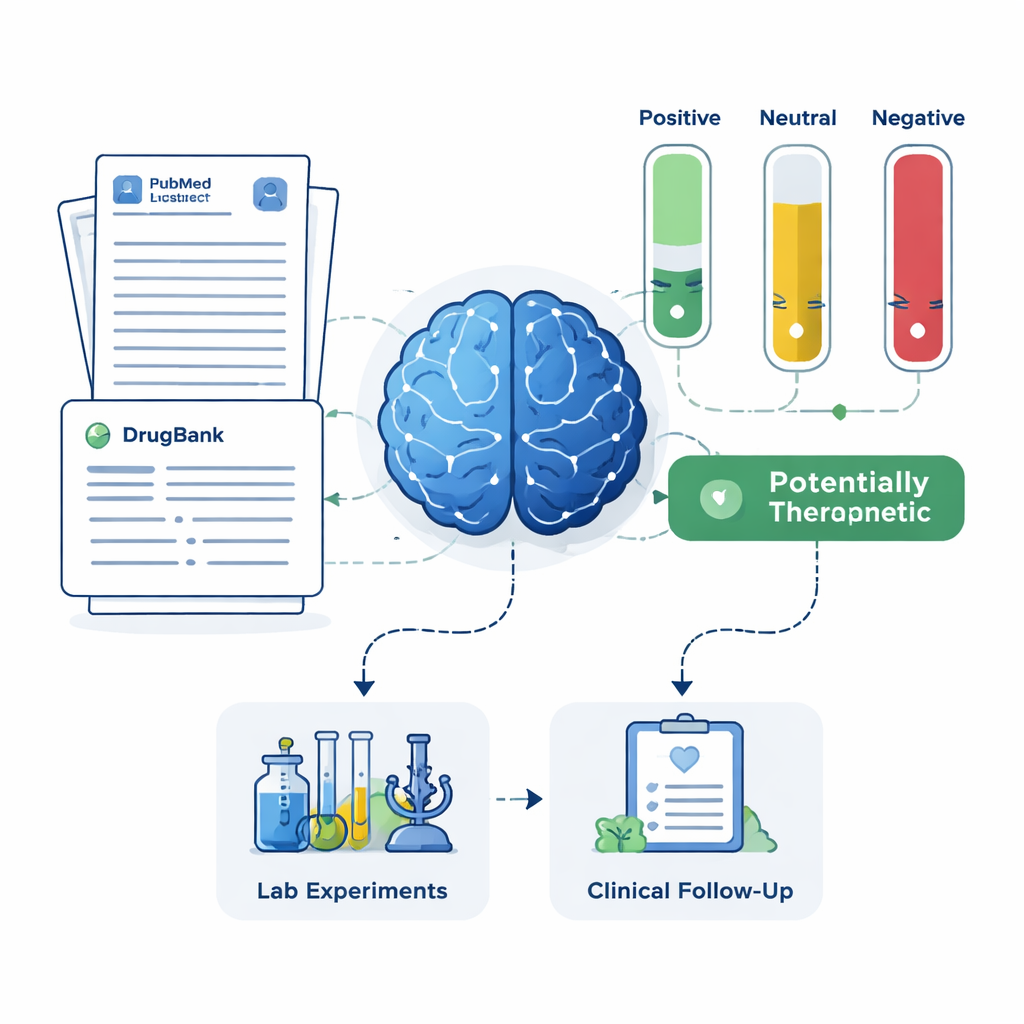
Kontroll mot verkliga patienter och kliniska prövningar
För att se om AI:ns kortlista stämde i verkliga världen jämförde teamet sina resultat med två oberoende källor: ett stort register över Alzheimers‑patienter och uppgifter från registrerade kliniska prövningar. Ramverket återfann med framgång memantin, ett befintligt Alzheimersläkemedel med starka skyddssignaler i patientdata och omfattande prövningshistorik, som en högprioriterad kandidat. Det lyfte också fram läkemedel såsom magnesium, minocyklin, pimavanserin, testosteron och doxycyklin, som har varierande grad av stödjande forskning men som bedömdes lovande av kliniska experter. Samtidigt identifierade systemet läkemedel vars litteratur antydde möjlig skada eller utebliven nytta, och rekommenderade att dessa skulle nedprioriteras eller utredas för biverkningar snarare än behandlingseffekt.
Från datorprediktioner till praktiska nästa steg
I vardagliga termer fungerar detta ramverk som en ultrarapid, noggrann forskningsassistent som läser tusentals artiklar, korskontrollerar mönster i stora medicinska databaser och överlämnar en mycket kortare, bättre organiserad lista över Alzheimers‑kandidatläkemedel till mänskliga experter att fokusera på. Studien visar att genom att kombinera olika typer av AI — grafbaserade modeller för att generera idéer och en språkmodell för att bedöma bevisen — kan forskare snabbare hitta både välunderbyggda läkemedel och intressanta nya alternativ för testning. Även om detta tillvägagångssätt i sig inte botar Alzheimer, erbjuder det ett kraftfullt nytt sätt att koppla datorgenererade idéer till det hårda arbetet i labbexperiment och kliniska prövningar, vilket potentiellt kan snabba på vägen till effektivare behandlingar.
Citering: Li, M., Niu, S., Xu, Y. et al. Bridging the computational-experimental gap: leveraging large language model to prioritize Alzheimer’s therapeutics based on comparison of learning models. npj Health Syst. 3, 20 (2026). https://doi.org/10.1038/s44401-026-00074-3
Nyckelord: Alzheimers sjukdom, läkemedelsomvandling, artificiell intelligens, stora språkmodeller, kunskapsgrafer