Clear Sky Science · sv
Upptäcka stigmatiserande språk i kliniska anteckningar med stora språkmodeller för missbruksvård
Varför orden i din journal spelar roll
När fler patienter får åtkomst till sina journaler på nätet är inte längre det språk kliniker använder dolt i sjukhusdatorer — det är synligt för de personer det handlar om. För patienter som lever med ett missbruk kan en enda fras som "drug abuser" tyst förstärka skam, skada förtroendet och till och med påverka den vård de får. Denna studie ställer en aktuell fråga: kan modern artificiell intelligens hjälpa sjukhus att upptäcka och minska stigmatiserande språk i kliniska anteckningar innan det skadar patienter?

Skadliga etiketter dolda i vardagliga anteckningar
Stigma i vården visar sig inte bara i ögonkontakt eller tonfall; det är också inbäddat i den skriftliga dokumentationen. Elektroniska journaler innehåller miljontals anteckningar som följer patienter över kliniker och sjukhus. Termer som "alcohol abuse" eller "drug-seeking behavior" kan forma hur framtida kliniker ser på en person långt efter ett besök på akuten eller en sjukhusvistelse. Forskarna fokuserade på intensivvårdsanteckningar om patienter med missbruksproblem, där insatserna är höga och dokumentationen omfattande. De utgick från nationella riktlinjer som uppmuntrar respektfullt, personförst-språk, som "person med substansanvändningsstörning" istället för "addict", och använde dessa idéer för att skapa en stor datamängd med anteckningar märkta som antingen stigmatiserande eller inte.
Att lära en AI läsa mellan raderna
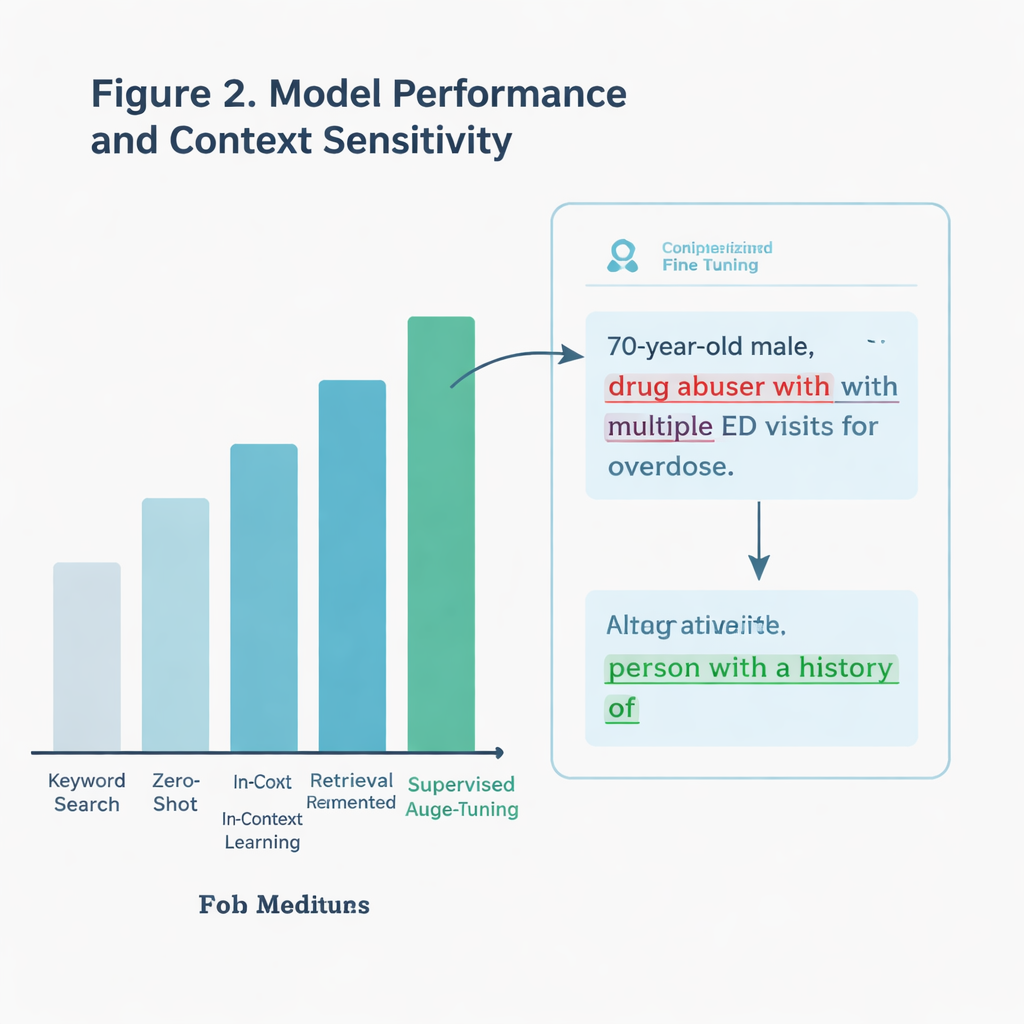
I stället för att bara söka efter fula ord ville teamet ha ett AI-system som kunde förstå kontext. Till exempel kan en anteckning citera en patient som beskriver sig själv som "drunk", vilket inte är samma sak som att en kliniker sätter den etiketten. Författarna jämförde flera tillvägagångssätt, alla byggda på en stor språkmodell (en typ av AI som bearbetar och genererar text). En grundläggande metod letade endast efter specifika nyckelord hämtade från riktlinjerna. Mer avancerade metoder bad AI:n bedöma varje anteckning direkt, antingen utan extra exempel, med tillagd vägledning från kommunikationsriktlinjer eller efter att ha tränats särskilt — eller "finjusterats" — på tusentals märkta IVA-anteckningar.
Vad som fungerade bäst i verkligheten
Den finjusterade modellen var en klar vinnare. På ett hållprovstest med mer än 11 000 anteckningar identifierade den korrekt stigmatiserande språk i ungefär 97 procent av fallen, långt bättre än enkel nyckelordssökning. Den höll sig också bättre på en särskilt knepig delmängd anteckningar som innehöll potentiellt laddade termer men inte alltid användes på ett skadligt sätt. Modellen kunde skilja mellan verkligt dömande uttryck och neutrala eller citerade användningar, där en grövre sökning skulle misslyckas. När teamet testade systemet på anteckningar från ett annat vårdsystem — nästan 300 000 IVA-anteckningar skrivna i en annan delstat — presterade det fortfarande bättre än nyckelordsmetoden, även om stigmatiserande språk var sällsynt i det verkliga urvalet.
Att hitta nya problemfraser som kliniker missade
Forskarna gick ett steg längre och bad AI:n förklara varför den flaggat vissa anteckningar. En specialist på missbruk granskade sedan dessa förklaringar. I flera dussin fall lyfte modellerna fram verkligt stigmatiserande språk som mänskliga annotatörer ursprungligen förbises, inklusive fraser som inte fanns med i befintliga riktlinjer. Exempel inkluderade beskrivningar som "drug-seeking behavior" eller vardagliga omnämnanden av "alcoholic cirrhosis" som subtilt lade skuld på personen snarare än på sjukdomen. Detta tyder på att väl utformade AI-verktyg inte bara kan upprätthålla nuvarande bästa praxis utan också hjälpa till att vidga vår förståelse av vad skadligt språk är i takt med att kliniskt skrivande utvecklas.
Från forskningsverktyg till hjälp vid sängkanten
Studien vägde också praktiska frågor. Nyckelordssökning är blixtsnabb men ytlig. Den mest precisa AI-modellen krävde flera timmars träning på kraftfulla grafikkort, men när den väl var tränad kunde den granska anteckningar på några sekunder styck — långsamt för en sökmotor, men acceptabelt för en bakgrundsassistent i ett sjukhussystem. Ett annat, mindre anpassat tillvägagångssätt som enbart byggde på noggrant utformade prompts presterade hyggligt utan extra träning, vilket antyder lättare alternativ för kliniker med färre tekniska resurser. Tillsammans pekar dessa resultat mot system som kan flagga riskabelt ordval i realtid och föreslå mer respektfulla alternativ medan kliniker skriver.
Ett steg mot mer respektfull vård
För en lekmannaläsare är huvudpoängen enkel: orden i din journal är inte bara teknisk jargong; de hjälper forma hur du behandlas. Denna studie visar att stora språkmodeller pålitligt kan upptäcka många former av stigmatiserande språk relaterat till missbruk i intensivvårdsanteckningar, även när problemet är subtilt. Ingen system är perfekt, men sådana verktyg skulle kunna fungera som ständigt närvarande redaktörer som småskjuter kliniker mot ett språk som ser människor som mer än sina diagnoser. I det långa loppet kan denna förskjutning — från skuld till respekt — vara lika viktig för läkning som någon medicin eller apparat.
Citering: Sethi, R., Caskey, J., Gao, Y. et al. Detecting stigmatizing language in clinical notes with large language models for addiction care. npj Health Syst. 3, 15 (2026). https://doi.org/10.1038/s44401-026-00069-0
Nyckelord: stigma kring missbruk, kliniska anteckningar, stora språkmodeller, elektroniska journaler, personförst-språk