Clear Sky Science · sv
3D magisk spegel: klädrekonstruktion från en enda bild ur ett kausalt perspektiv
Prova kläder utan provhytten
Föreställ dig att du tar ett enda helkroppsfotografi med mobilen och direkt ser dig själv i 3D, kan snurra bilden, byta vyer eller till och med byta kläder med en vän. Denna artikel tar sig an den centrala tekniska utmaningen bakom den ”3D magiska spegeln”: att förvandla en vanlig 2D-bild av en påklädd person till en detaljerad 3D-modell av plaggen, utan att förlita sig på kostsamma 3D-skanningar eller kontrollerade studiofoton.
Varför det är så svårt att gå från 2D till 3D
Att omvandla en platt bild till ett 3D-objekt är ett klassiskt pussel. Befintliga system utgår ofta från en fast digital kroppsmall och formar om den för att passa bilden. Det fungerar hyfsat för styva kroppsdelar som armar och ben, men fallerar för flytande klänningar, draperade rockar, hår eller handväskor som inte följer en enkel standardform. Ett annat hinder är data: det finns miljontals modebilder på nätet, men nästan inga stora samlingar av noggrant uppmätta 3D-plagg att träna på. Slutligen döljer en enda bild viktig information. En kort kappa nära kameran kan se identisk ut med en längre kappa längre bort, och ljusförhållanden och tygmönster kan också förvilla en inlärningsalgoritm. Dessa tvetydigheter gör det svårt för ett neuralt nätverk att ”gissa” den korrekta 3D-strukturen.
Lära AI att skilja orsak från verkan
I stället för att behandla problemet som en svart låda från pixlar till 3D lånar författarna idéer från kausal resonemang—matematiken bakom orsak och verkan. De ser den slutgiltiga bilden som resultatet av fyra dolda orsaker: kamerans position, klädernas form, dess textur (färger och mönster) och hur det är belyst. En särskild ”strukturell kausal karta” visar hur dessa faktorer kombineras för att producera den observerade bilden. Guidad av denna karta använder systemet fyra separata neurala kodare, var och en ansvarig för en faktor. Tillsammans med en fysikinspirerad 3D-renderare bildar de en slinga: bild och förgrundsmask matas in, ett färgat 3D-nät kommer ut, och sedan projiceras det tillbaka till en bild som kan jämföras med originalet.
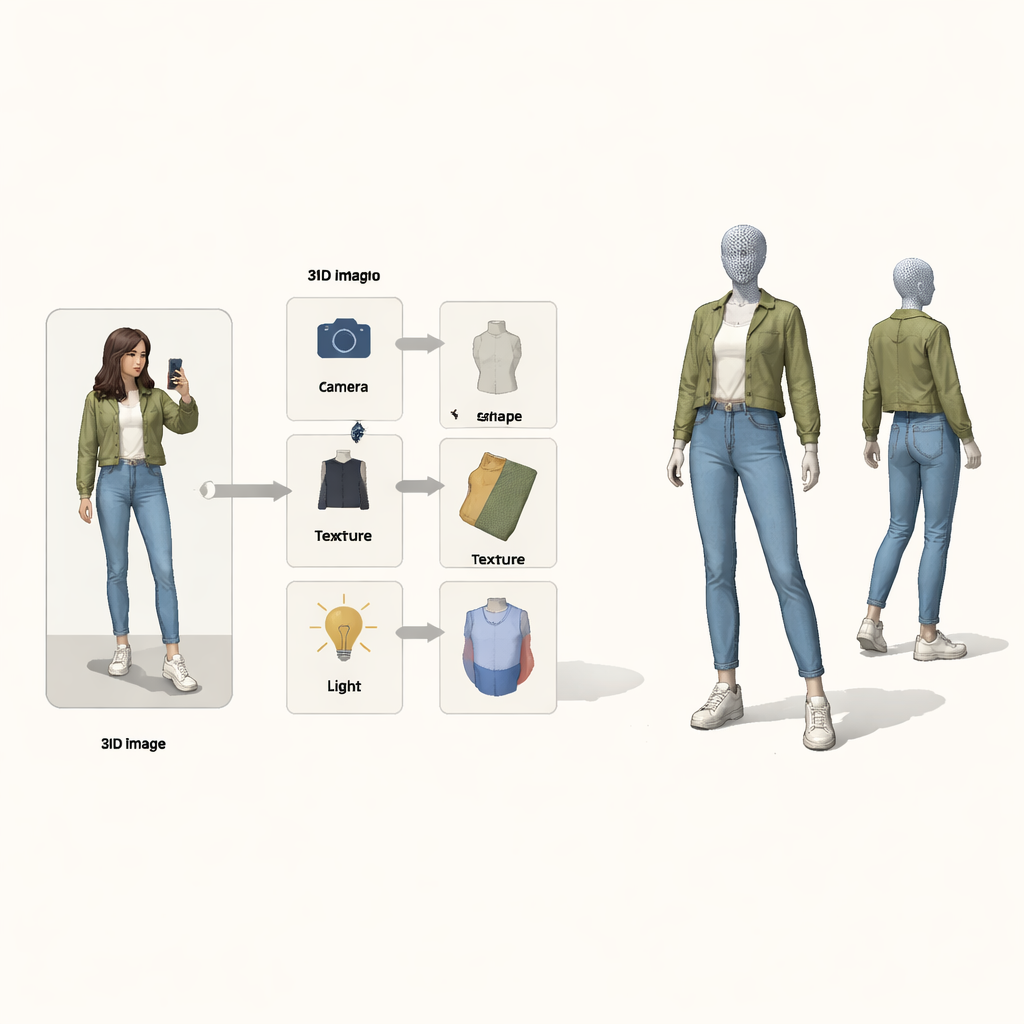
En inlärningsslinga som fixar en sak i taget
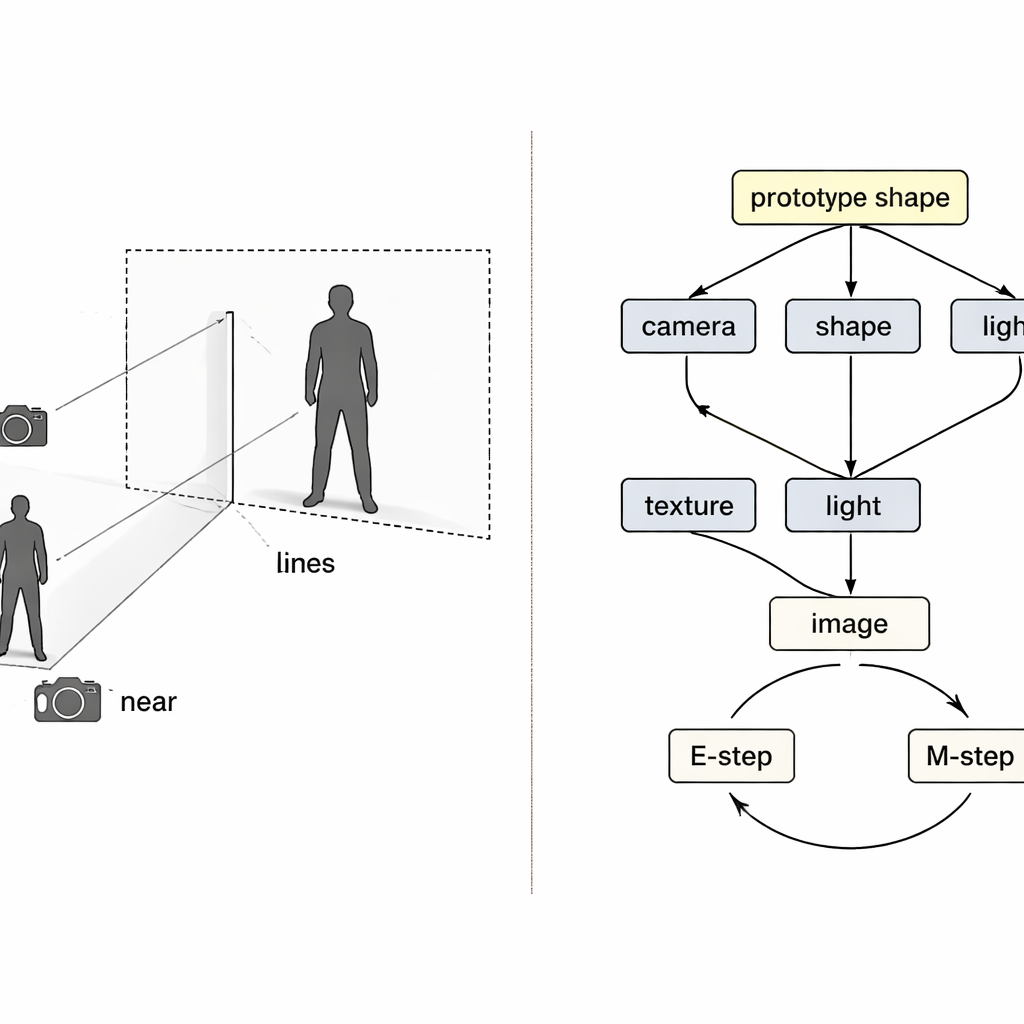
Även med separata kodare kan träningen gå fel. Om rekonstruktionen är ofullständig är det oklart vilken kodare som bär skulden, och vanlig inlärning tenderar att justera alla samtidigt. Författarna betraktar detta som ett klassiskt ”kollider”-problem inom kausalitet, där olika orsaker felaktigt kan kompensera för varandra. Deras lösning är att väva in två expectation–maximization-slingor i träningen. I den första slingan fryses tre kodare temporärt medan den fjärde uppdateras ensam, så att fel klart kan tillskrivas och den komponenten lär sig en renare roll. I den andra slingan uppdateras en delad ”prototyp” för 3D-form—som börjar som en enkel sfär—långsamt för att bli den genomsnittliga människoor fågelformen i data. Enskilda exempel lär sig bara små avvikelser från denna prototyp, medan kameramodulen tar fullt ansvar för hur stor eller nära objektet ser ut, vilket angriper förväxlingen mellan storlek och avstånd direkt.
Från modebilder till fåglar, och vidare
För att testa sitt tillvägagångssätt tränar forskarna på två stora modeset med vanliga gatfoton och på en standardkollektion med fågelbilder. Viktigt är att de använder endast 2D-förgrundsmasker, inte 3D-ground-truth-nät. För mänskliga kläder överträffar deras system populära kroppsmallsmetoder när det gäller att matcha det verkliga plaggets kontur och hanterar icke-styva element som hår och handväskor mer troget. På fåglar når det eller överträffar kvaliteten hos ledande metoder för 3D-rekonstruktion från en enda bild samtidigt som det producerar mer realistiska nya vyer. 3D-modellerna är tillräckligt flexibla för lekfulla tillämpningar, som att byta texturer mellan personer eller att generera syntetiska träningsdata för att förbättra personåteridentifieringssystem som används i övervakningsforskning.
Vad detta betyder för vardagliga digitala världar
För icke-specialister är kärnbudskapet att trovärdiga 3D-avatarer och verktyg för virtuell provning inte längre kräver dyra 3D-skanners eller stela mallar. Genom att uttryckligen modellera orsak och verkan—separera kamera, form, textur och ljus, och förankra dem till en delad prototyp—visar författarna hur ett system kan ”förklara” ett enda foto som en 3D-scen. Även om metoden fortfarande har problem med vyer den aldrig sett, såsom baksidan av en person som endast fotograferats framifrån, markerar den ett betydande steg mot praktiska 3D-magin speglar som fungerar på de röriga, vilda bilder vi faktiskt tar.
Citering: Zheng, Z., Zhu, J., Ji, W. et al. 3D Magic Mirror: clothing reconstruction from a single image via a causal perspective. npj Artif. Intell. 2, 29 (2026). https://doi.org/10.1038/s44387-026-00082-6
Nyckelord: virtuell provning, 3D-rekonstruktion, kausal inlärning, datorseende, mode-AI