Clear Sky Science · sv
Stora språkmodellers roll i akutsjukvården: en omfattande benchmarkstudie
Varför detta är viktigt för alla som kan komma att besöka akutmottagningen
Akutmottagningar är mer belastade än någonsin, med längre väntetider och färre anställda för att ta hand om ett växande antal svårt sjuka patienter. Denna studie ställer en fråga som berör i princip alla: kan moderna AI-system, kända som stora språkmodeller, på ett säkert sätt hjälpa läkare och sjuksköterskor att arbeta snabbare och smartare i akuten? Genom att utsätta flera ledande AI:er för en serie medicinska tester och simulerade akutfall undersöker forskarna hur nära dessa verktyg är att bli pålitliga ”co-piloter” i akut vård.
Akutmottagningar under kraftig press
Artikeln inleder med att beskriva en växande kris inom akutsjukvården, särskilt i USA. En åldrande befolkning och en ökning av kroniska sjukdomar driver rekordhöga besöksantal på akuten, ungefär 155 miljoner bara under 2022. Samtidigt står sjukhusen inför allvarliga brister på sjuksköterskor och läkare, och antalet vårdplatser per person har minskat över de senaste decennierna. Ett fragmenterat hälsosystem försvårar samordning av vård, vilket ökar risken för förseningar och fel. Mot denna bakgrund menar författarna att nya verktyg behövs skyndsamt för att hjälpa kliniker att triagera patienter, fatta snabba beslut och dokumentera vård utan att öka deras arbetsbelastning.
Hur forskarna testade medicinsk AI
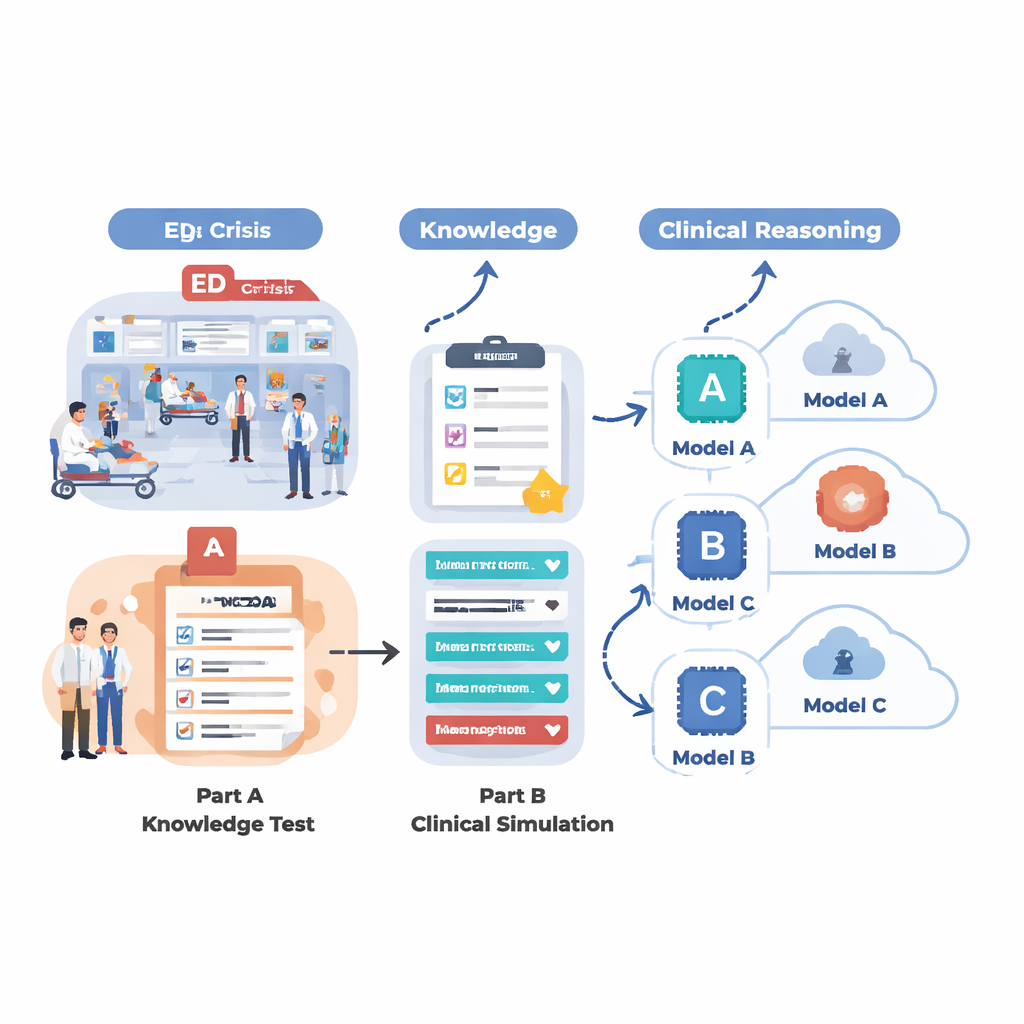
För att se vad dagens AI-system verkligen kan åstadkomma i en akutinspirerad miljö utformade teamet en tvådelad utvärdering. Först testade de 18 olika språkmodeller på ett stort antal flervalsfrågor hämtade från MedMCQA, en dataset i stil med medicinska prov som omfattar 12 vanliga akutsymtom såsom bröstsmärta, andnöd, huvudvärk och buksmärta. Denna fas mätte grundläggande medicinsk kunskap: kunde AI:n välja rätt svar bland fyra alternativ över tusentals frågor? Sedan valde de de fem starkaste modellerna från den rundan och bad dem arbeta igenom 12 realistiska akutfall, steg för steg, precis som en läkare skulle göra. För varje fall måste AI:n sammanfatta patienten, tilldela ett triage-urgenspoäng, föreslå viktiga följdfrågor, föreslå åtgärder och lista sannolika diagnoser allt eftersom ny information (vitala tecken, anamnes, statusfynd, laboratorie- och bilddiagnostik) gradvis avslöjades.
Vilka AI-modeller kunde fakta — och vilka kunde resonera
Vid ren faktabearbetning presterade flera modeller imponerande. Ett specialiserat system kallat LLaMA 4 Maverick uppnådde cirka 91 procent träffsäkerhet totalt på de medicinska frågorna, tätt följt av LLaMA 3.1, GPT-4.5, GPT-5 och Claude 4. Dessa toppmodeller var konsekvent starka över olika huvudklagomål, vilket tyder på att den främsta AI-fronten kan närma sig ett tak i läroboksstilad medicinsk kunskap. Mellannivåsystem halkade efter betydligt, med vissa runt 60 procent och som hade svårt i viktiga områden som sårvård och andningsproblem. När uppgiften dock skiftade från att svara på isolerade frågor till att resonera kring rika, skiftande patientberättelser blev skillnaderna tydligare. I dessa kliniska simuleringar stack GPT-5 ut: den producerade de mest korrekta och fullständiga sammanfattningarna, ställde de mest hjälpsamma följdfrågorna, rekommenderade förnuftiga och säkra nästa steg, och erbjöd de mest grundliga och välordnade listorna över möjliga diagnoser.
Styrkor, svagheter och säkerhetsfrågor
Kliniker bedömde noggrant varje AIs utsagor utifrån noggrannhet, relevans och säkerhet. GPT-5 fick inte bara de högsta poängen totalt; det var också den enda modellen vars prestanda höll sig stabil eller förbättrades när fallen blev mer komplexa, samtidigt som hallucinationer och allvarliga fel hölls under cirka 2 procent. Andra modeller visade tydliga mönster av svaghet. Vissa tenderade att missa sekundära diagnoser eller sätta mindre problem framför farliga sådana. Andra blev överdrivet försiktiga eller vaga, eller låste sig för snabbt vid en enda diagnos. Generellt underskattade de flesta systemen hur sjuka patienterna var vid tilldelning av triagenivåer, en konservativ snedvridning som kan försena brådskande vård om den inte rättas till. Resultaten betonar en viktig poäng: att kunna medicinska fakta är inte samma sak som att pålitligt väva in dessa fakta i säkra, stegvisa beslut när informationen är ofullständig, rörig och föränderlig.

Vad detta kan innebära för framtida akubesök
Författarna drar slutsatsen att medan flera moderna AI:er nu är jämförbara vad gäller medicinsk kunskap, visar GPT-5 särskilt en ny nivå av resonemangsförmåga som skulle kunna göra den användbar som ett beslutsstödsverktyg i akutmottagningar. De understryker att dessa system inte är redo att ersätta kliniker eller agera på egen hand. Istället är den mest lovande kortsiktiga rollen som en övervakad assistent — att hjälpa triagesjuksköterskor bedöma brådska, utarbeta patientsammanfattningar, föreslå frågor eller tester och kontrollera att allvarliga diagnoser beaktats. Studien betonar också att mer forskning behövs i verkliga kliniska miljöer, med starka säkerhetskontroller och tydliga användningsregler. För patienter är budskapet försiktig optimism: AI blir bättre på att tänka igenom medicinska problem, men dess säkra användning i akuten kommer att bero på omsorgsfull utformning, tillsyn och ett fortsatt fokus på att stödja — inte ersätta — människans omdöme hos läkare och sjuksköterskor.
Citering: Naderi, B., Liu, L., Ghandehari, A. et al. The role of large language models in emergency care: a comprehensive benchmarking study. npj Artif. Intell. 2, 24 (2026). https://doi.org/10.1038/s44387-026-00078-2
Nyckelord: akutsjukvård, stora språkmodeller, kliniskt beslutsstöd, triage, benchmarking av medicinsk AI