Clear Sky Science · sv
Förbättra few-shot namngiven entitetsigenkänning för stora språkmodeller med strukturerad dynamisk prompting och retrieval-augmented generation
Varför smartare läsning av medicinsk text spelar roll
Modern medicin genererar oceaner av text — från intensivvårdsanteckningar till onlinesamtal om läkemedelsanvändning. Dolda i dessa ord finns viktiga ledtrådar om sjukdomar, behandlingar och biverkningar. Att automatiskt hitta och märka sådana informationsbitar, en uppgift kallad ”namngiven entitetsigenkänning”, kan hjälpa forskare att följa utbrott, upptäcka läkemedelsproblem tidigare och stödja läkare i realtid. Men traditionella system kräver stora handmärkta datamängder, som är dyra att ta fram och ofta saknas för sällsynta eller nya hälsoproblem. Denna studie undersöker hur stora språkmodeller, likt dem bakom dagens chattbotar, kan styras med noggrant utformade prompts och smart återvinning av exempel så att de klarar denna märkning även när bara ett fåtal annoterade prov finns tillgängliga.
Att lära maskiner att känna igen viktiga ord
Författarna fokuserar på biomedicinsk namngiven entitetsigenkänning — att hitta omnämnanden av sjukdomar, läkemedel, symptom och sociala konsekvenser i text. Detta är svårt eftersom medicinskt språk är mycket specialiserat, varierar mellan sjukhus eller delområden och ofta innehåller sällsynta tillstånd som bara dyker upp ett fåtal gånger i en given datamängd. Befintliga maskininlärningsmodeller kan nå mänsklig prestanda men kräver vanligen stora, välannoterade korpusar som är kostsamma att skapa och dela, särskilt under strikta sekretessregler. Few-shot-inlärning, där modeller lär sig från bara ett fåtal märkta exempel, erbjuder en väg runt denna flaskhals. Stora språkmodeller är särskilt lovande här eftersom de kan lära mönster direkt från instruktioner och exempel i prompten utan att man behöver reträna deras interna vikter.
Bygga bättre instruktioner för språkmodeller
Första delen av arbetet utformar en mycket strukturerad ”statisk” prompt — en återanvändbar block med instruktioner och exempel som presenteras för modellen för varje mening den ska märka. Istället för att bara be modellen att tagga entiteter, delas prompten upp i sex element: en tydlig uppgiftsbeskrivning och definitioner av entitetstyper; en kort beskrivning av datasetets källa och tema; frekventa exempelord typiska för varje entitet; valbar bakgrundskunskap inom medicin; sammanfattad återkoppling från tidigare modellfel; och ett par fullt annoterade exempelmeningar. Teamet testade denna ram med tre stora språkmodeller — GPT-3.5, GPT-4 och LLaMA 3-70B — på fem biomedicinska dataset som spände över journalanteckningar, vetenskapliga abstrakt och Reddit-inlägg om opioidbruk. Genom att noggrant lägga dessa komponenter steg F1-poängen (en balans mellan precision och recall) med ungefär 11–12 procentenheter jämfört med en grundläggande prompt, där GPT-4 uppnådde den bästa samlade prestandan.
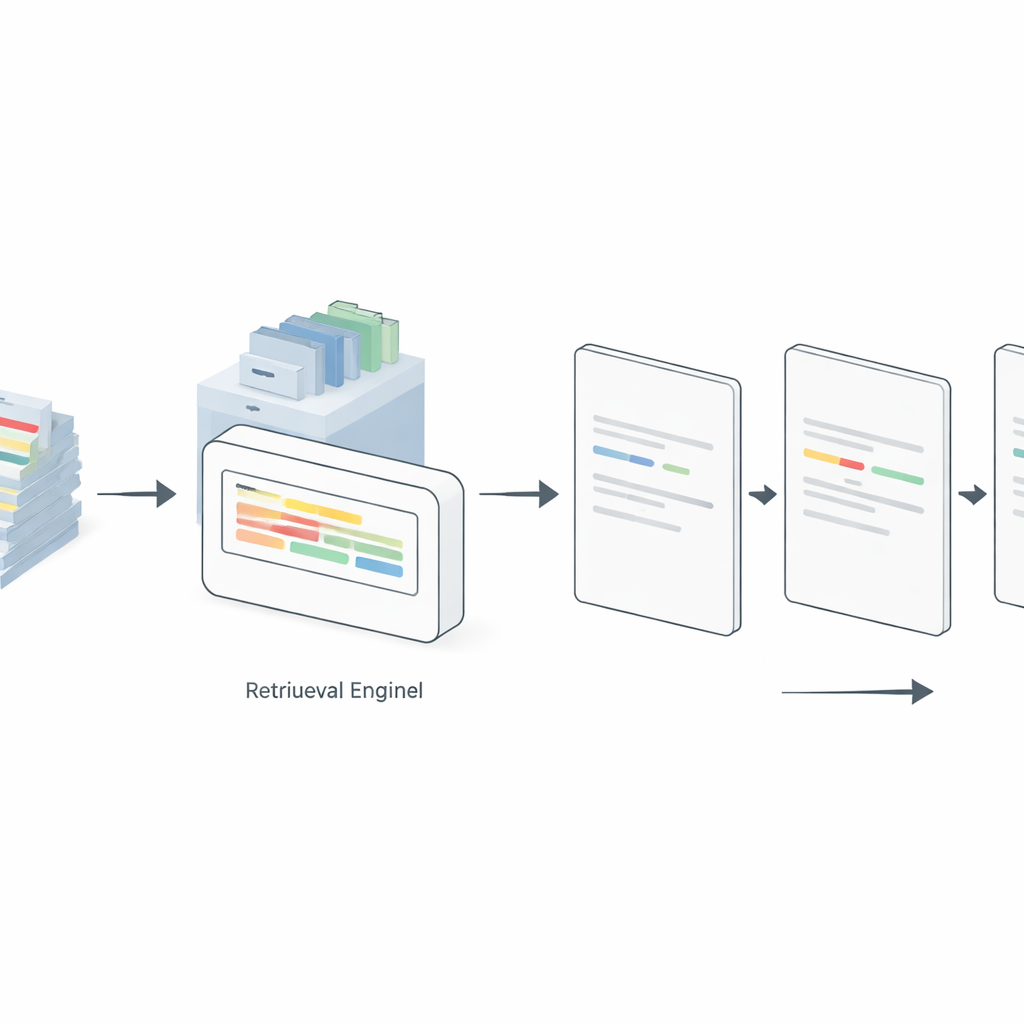
Låta modellen söka upp bättre exempel i farten
Statisk prompting visar dock alltid samma exempel, även när de inte passar bra till den nya meningen som ska märkas. För att hantera detta introducerar författarna en ”dynamisk” promptingstrategi driven av retrieval-augmented generation. Här indexerar en separat sökmotor alla tillgängliga annoterade exempel. För varje ny inmatningsmening söker systemet i denna pool efter de mest liknande märkta meningarna och sätter endast in dessa i prompten. Studin jämför flera sökmetoder, från ett enkelt termfrekvensschema (TF–IDF) till neurala embeddingsmodeller som Sentence-BERT (SBERT), ColBERT och Dense Passage Retrieval. Över GPT-4, LLaMA 3 och en öppenviktsmodell kallad GPT-OSS-120B överträffade dynamiskt valda relevanta exempel konsekvent statisk prompting i 5-, 10- och 20-shot-inställningar. Överraskande nog matchade eller slog ofta den enkla TF–IDF-metoden mer komplexa tillvägagångssätt, särskilt på renare, mer standardiserade dataset, medan SBERT glänste på brusigare sociala medier-texter.
Få mer med färre märkta exempel
Eftersom annotering av medicinsk text är dyrt studerade författarna även hur stor den annoterade poolen måste vara för att retrieval-motorn ska vara användbar. Med LLaMA 3-70B varierade de sökpoolen från 50 exempel upp till hela träningssetet. Prestandan förbättrades generellt när poolen växte, men vinsterna planar snabbt ut: pooler på cirka 100–200 exempel nådde nästan samma noggrannhet som att indexera alla tillgängliga data, ofta inom den statistiska felmarginalen. I vissa fall försämrade extremt stora pooler prestandan något, sannolikt eftersom de introducerade fler irrelevanta eller förvirrande exempel och förlängde prompten. Dessa fynd tyder på att, när de paras med en stark språkmodell och väl utformade prompts, kan även måttliga annoteringsinsatser ge robust biomedicinsk entitetsigenkänning, vilket gör tillvägagångssättet genomförbart för sällsynta sjukdomar, nya kliniska begrepp eller institutioner med begränsade resurser.
Vad detta betyder för verklig medicin
Sammantaget visar studien att stora språkmodeller kan pålitligt plocka ut viktiga medicinska begrepp ur text med bara ett fåtal annoterade exempel, förutsatt att de styrs av strukturerade prompts och ett retrievalsystem som lyfter fram de mest relevanta tidigare fallen. GPT-4 erbjuder den starkaste allmänna prestandan, medan öppna och mindre modeller fortfarande gynnas av samma prompting- och retrievalrecept i betydande utsträckning. För praktiker innebär detta att de inte behöver bygga massiva datamängder varje gång en ny entitetstyp eller hälsofråga dyker upp; en kompakt, omsorgsfullt kurerad uppsättning exempel plus smart prompting kan vara tillräckligt. När vårdsystem fortsätter att digitalisera anteckningar och patienter diskuterar sina upplevelser online kan sådana effektiva, anpassningsbara verktyg göra det mycket enklare att låsa upp kliniskt användbar kunskap ur den omfattande, röriga världen av medicinsk text.
Citering: Ge, Y., Guo, Y., Das, S. et al. Improving few-shot named entity recognition for large language models using structured dynamic prompting with retrieval augmented generation. npj Artif. Intell. 2, 39 (2026). https://doi.org/10.1038/s44387-025-00062-2
Nyckelord: biomedicinsk namngiven entitetsigenkänning, few-shot-inlärning, stora språkmodeller, retrieval-augmented generation, klinisk textutvinning