Clear Sky Science · sv
En utvärdering av skattningsosäkerhet i stora språkmodeller
Varför vaga ord om risk verkligen spelar roll
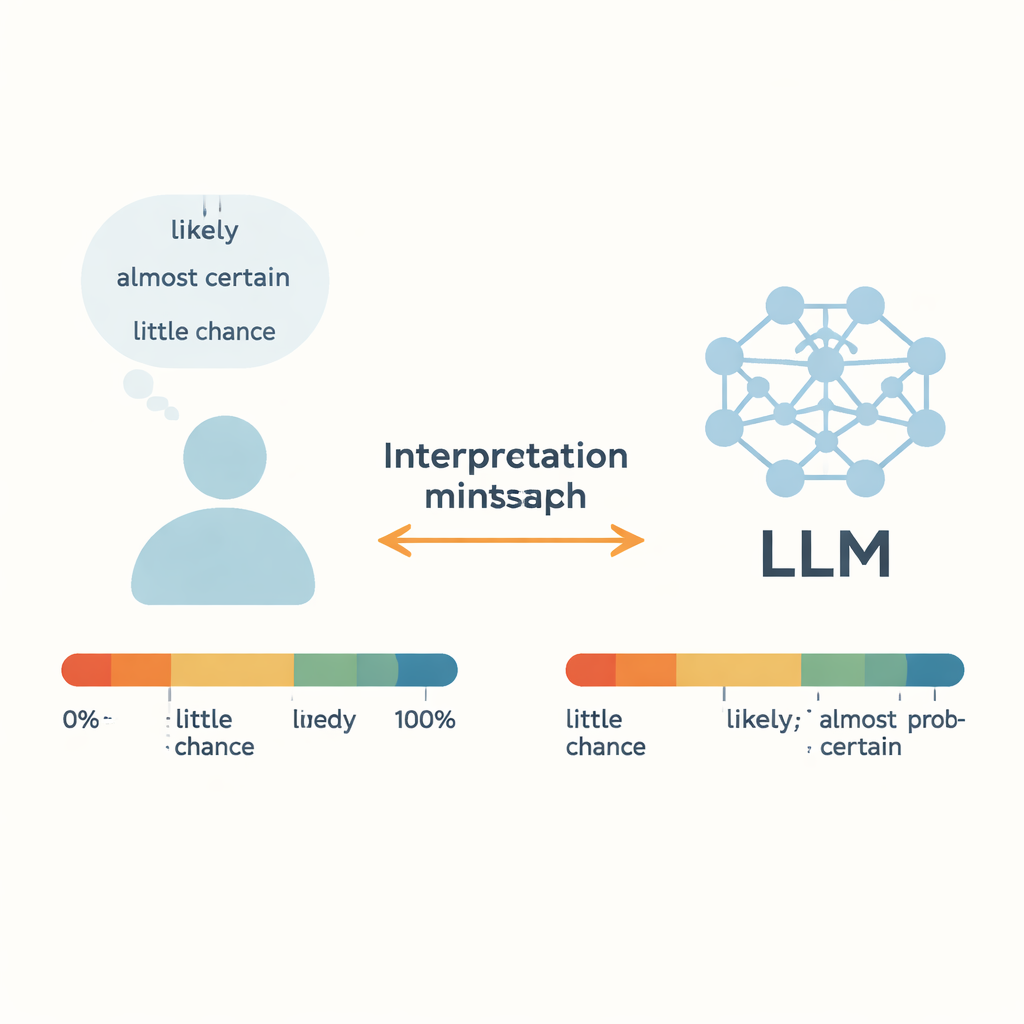
När en läkare säger att en behandling är ”trolig” att fungera, eller när en väderprognos varnar för att det finns ”liten chans” för en orkan, litar vi på dessa vagt formulerade ord för att fatta verkliga beslut. Idag börjar stora språkmodeller (LLM:er) som nätbaserade chattrobotar använda samma vokabulär. Denna studie ställer en enkel men avgörande fråga: när en AI säger ”sannolikt”, menar den samma sak som vi — och kan den pålitligt omvandla råa siffror till vardagliga osäkerhetsord?
Att granska vardaglig osäkerhet under mikroskopet
Författarna fokuserar på ”Words of Estimative Probability” (WEPs) — termer som ”nästan säker”, ”trolig” och ”liten chans” som människor använder i stället för exakta procentsatser. Tidigare arbete, som går tillbaka till underrättelseanalytiker på 1960‑talet, försökte koppla dessa ord till numeriska sannolikheter genom att fråga människor. Denna studie jämför dessa mänskliga omdömen med utskrifter från fem moderna LLM:er, inklusive GPT‑3.5, GPT‑4, Metas Llama‑modeller och ett kinesiskt system kallat ERNIE‑4.0. För 17 vanliga osäkerhetsord fick varje modell korta, berättelseliknande uppmaningar på engelska eller kinesiska och ombads svara med en numerisk sannolikhet mellan 0 och 100 procent. Genom att upprepa detta över många kontexter byggde författarna fullständiga sannolikhetsfördelningar för varje ord och varje modell, och jämförde sedan dessa med data från mänskliga enkäter.
När människor och AI talar samma språk
För de mest extrema uttrycken — som ”nästan säker” i det övre spannet och ”nästan ingen chans” i det nedre — stämmer LLM:er och människor förvånansvärt väl överens. Både människor och modeller tenderar att klustra dessa fraser inom snäva, höga respektive låga sannolikhetsintervall, vilket tyder på att dessa starka uttryck har relativt stabila betydelser över kontexter. Detsamma gäller för ”ungefär jämnt”, som de flesta människor och modeller behandlar som ungefär en 50–50‑chans. Statistiska tester visar liten meningsfull skillnad mellan mänskliga och modellfördelningar för just dessa ord, vilket antyder att LLM:er kan fånga tydliga fall av nära‑säkerhet eller nära‑omöjlighet med människolik precision.
Var betydelser tyst glider isär
Tveksamma, mitten‑ordnade uttryck berättar en annan historia. För uttryck som ”trolig”, ”sannolik”, ”vi tvivrar” och ”liten chans” skiljer sig modellernas numeriska tolkningar markant från mänskliga omdömen. GPT‑4, trots att den generellt är mer kapabel än GPT‑3.5, visar ofta större klyftor. Författarna föreslår att detta kan bero på att sådana ord blandar två saker: en känsla av sannolikhet och talarens attityd eller hållning. I verkliga samtal kan ”trolig” låta försiktig eller självsäker beroende på ton och kontext, och ”vi tvivrar” kan uttrycka skepsis snarare än en exakt sannolikhet. Tränade på stora, genremixade texter från internet kan LLM:er genomsnittliggöra över många motsägelsefulla användningar och utjämna dessa nyanser. Resultatet är en dold mismatch: människor och AI kan se samma mening och tyst knyta olika siffror till samma ord.
Kön, språk och kulturella ekon
Forskarna testade också hur könsbetonad formulering och olika språk formar dessa sannolikhetsord. När uppmaningar syftade på ”han” eller ”hon” i stället för könsneutrala subjekt producerade GPT‑3.5 och GPT‑4 ofta mindre variabla, mer ”låsta” sannolikhetsskattningar, ibland hopfallande till en enda punkt. Det tyder på att modellerna kan ha inhämtat stelbenta mönster från stereotyper i träningsdata, även om de övergripande medelvärdena för manliga och kvinnliga uppmaningar var likartade. Vid jämförelser mellan engelska och kinesiska uppvisade GPT‑modeller märkbara förskjutningar i hur de tolkade samma osäkerhetsord. ERNIE‑4.0, tränad främst på kinesisk text, låg närmare kinesisktalande människors tolkningar för många termer men överskattade eller underskattade fortfarande vissa uttryck. Dessa fynd framhäver att hur en AI talar om osäkerhet inte bara beror på ordvalet utan också på språket och de kulturella mönster som finns inbäddade i dess träning.
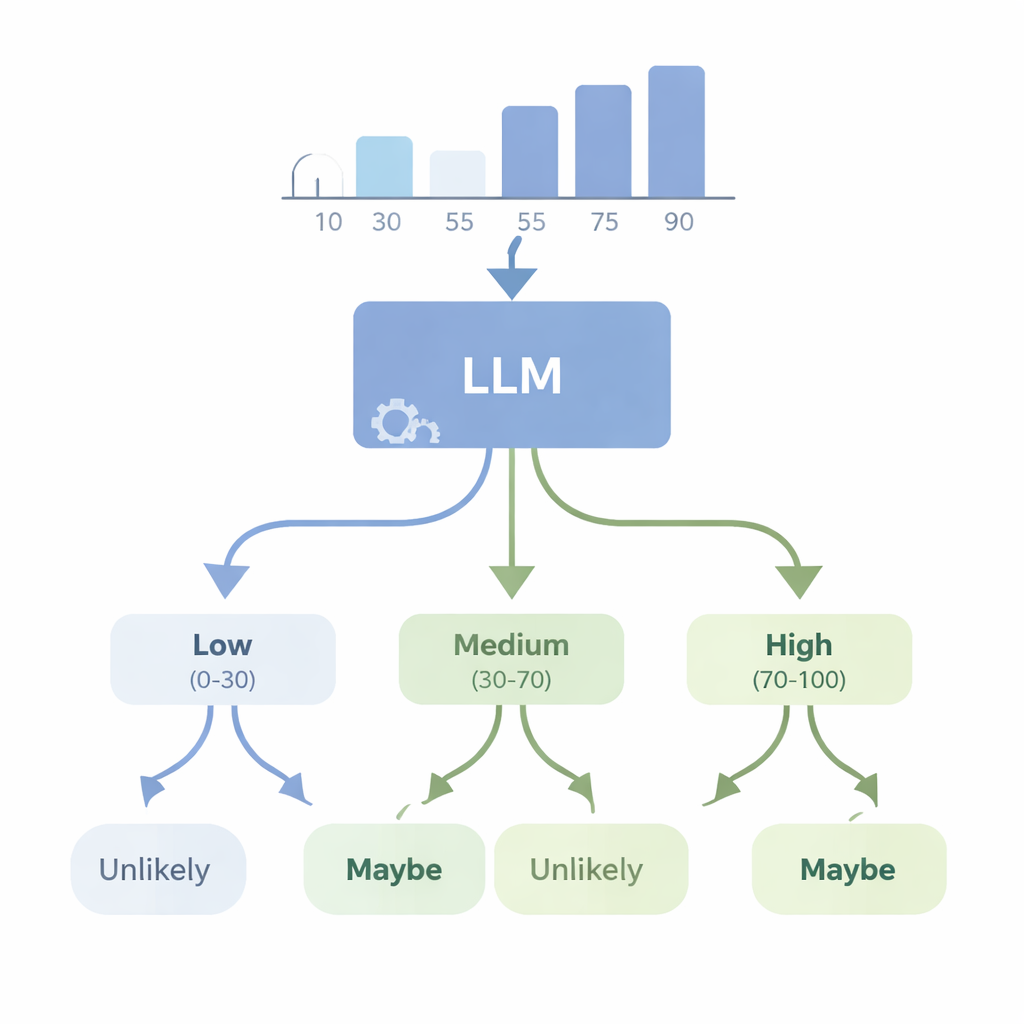
Kan AI omvandla siffror till begripligt tvivel?
I en andra serie experiment undersökte författarna det omvända problemet: kan en avancerad modell som GPT‑4 börja från numeriska data och välja ett lämpligt osäkerhetsord? De gav modellen enkla dataset — till exempel listor med längder eller provresultat — och bad den välja den mest passande WEP (till exempel ”nästan säkert”, ”troligt”, ”kanske”, ”osannolikt” eller ”nästan absolut inte”) för utsagor om framtida utfall. De utvärderade sedan GPT‑4 med fyra nya ”konsekvens”poäng som kontrollerar om dess ordval är logiskt rimliga när sannolikheter går upp eller ner, när komplementära händelser beskrivs och när underliggande siffror ändras på kontrollerade sätt. GPT‑4 presterade betydligt bättre än slumpen och kunde ofta följa grova förändringar i sannolikhet, men den kom långt ifrån perfekt konsekvens. I vissa tester svarade den nästan likadant över olika konfidensnivåer, vilket tyder på att den ibland behandlar dessa ord som breda etiketter snarare än en finskalig skala kopplad till de faktiska siffrorna.
Vad detta betyder för verkliga beslut
För läsaren är budskapet försiktigt men inte alarmistiskt. LLM:er kan redan efterlikna våra starkaste uttryck för säkerhet och omöjlighet, och de kan ofta sammanfatta data till rimliga ”troligt” eller ”osannolikt”‑påståenden. Men denna studie visar att för många vardagliga osäkerhetsord stämmer deras interna kalibrering inte fullt ut med mänsklig intuition, och deras koppling från siffror till språk kan vara inkonsekvent. Inom områden som medicin, policy eller vetenskapskommunikation — där små skiftningar i hur vi formulerar risk eller förtroende kan spela roll — kanske en modells ”sannolikt” inte är densamma som din. Författarna argumenterar för att för att använda dessa system säkert måste vi behandla osäkerhetsord som en delad kodbok som fortfarande kräver noggrann anpassning, testning och kanske uttryckligt numeriskt stöd, i stället för att anta att människa och maskin per automatik menar samma sak.
Citering: Tang, Z., Shen, K. & Kejriwal, M. An evaluation of estimative uncertainty in large language models. npj Complex 3, 8 (2026). https://doi.org/10.1038/s44260-026-00070-6
Nyckelord: osäkerhet språk, stora språkmodeller, sannolikhetsord, människa-AI-kommunikation, risktolkning