Clear Sky Science · sv
Förvillkorad inexakt stokastisk ADMM för djupa modeller
Smartare träning för smartare AI
Moderna artificiella intelligenssystem, från chattbotar till bildgeneratorer, drivs av massiva neurala nätverk som är ökända för att vara svåra och kostsamma att träna. När företag och forskare sprider data över många enheter och servrar blir dagens standardmetoder för träning ofta långsammare, instabila eller helt enkelt oförmögna att hantera röran i verkliga data. Denna artikel presenterar en ny familj av träningsalgoritmer, centrerad kring en metod kallad PISA, som lovar snabbare och mer tillförlitlig inlärning för en rad djupa modeller samtidigt som den gör färre matematiska antaganden om data.
Varför dagens träningsmetoder har problem
De flesta djupa inlärningsmodeller tränas med varianter av stokastisk gradientnedstigning, en metod som upprepade gånger skjuter modellparametrarna i den riktning som minskar felet. Under årens lopp har många förbättringar—såsom Adam, RMSProp och andra—försökt göra dessa justeringar smartare genom att anpassa steglängder eller lägga till momentum. Dessa metoder antar dock vanligtvis att träningsdata är snyggt blandade och statistiskt likartade över maskiner, samt att vissa matematiska storheter förblir begränsade. I praktiken, särskilt i sammanhang som federerad inlärning där telefoner eller edge-enheter har mycket olika data, bryts ofta dessa antaganden, vilket leder till långsam konvergens eller dålig prestanda.
Ett nytt sätt att samordna många inlärare
Författarna bygger vidare på en annan optimeringsram känd som alternating direction method of multipliers (ADMM), som är bra på att dela upp ett stort problem i många mindre som kan lösas parallellt. Deras huvudsakliga bidrag, PISA (preconditioned inexact stochastic ADMM), bevarar ADMM:s styrkor samtidigt som den undviker dess vanliga nackdelar—som behovet av att beräkna fullständiga gradienter över alla data eller utföra dyra matrisinversioner. Istället låter PISA varje klient eller arbetarnod uppdatera sin egen kopia av modellen med endast ett minibatch av data, och samordnar sedan dessa uppdateringar via en central variabel. Omsorgsfullt designade "preconditionering"-matriser formar uppdateringsriktningarna så att inlärningen fortskrider jämnare och mer effektivt. 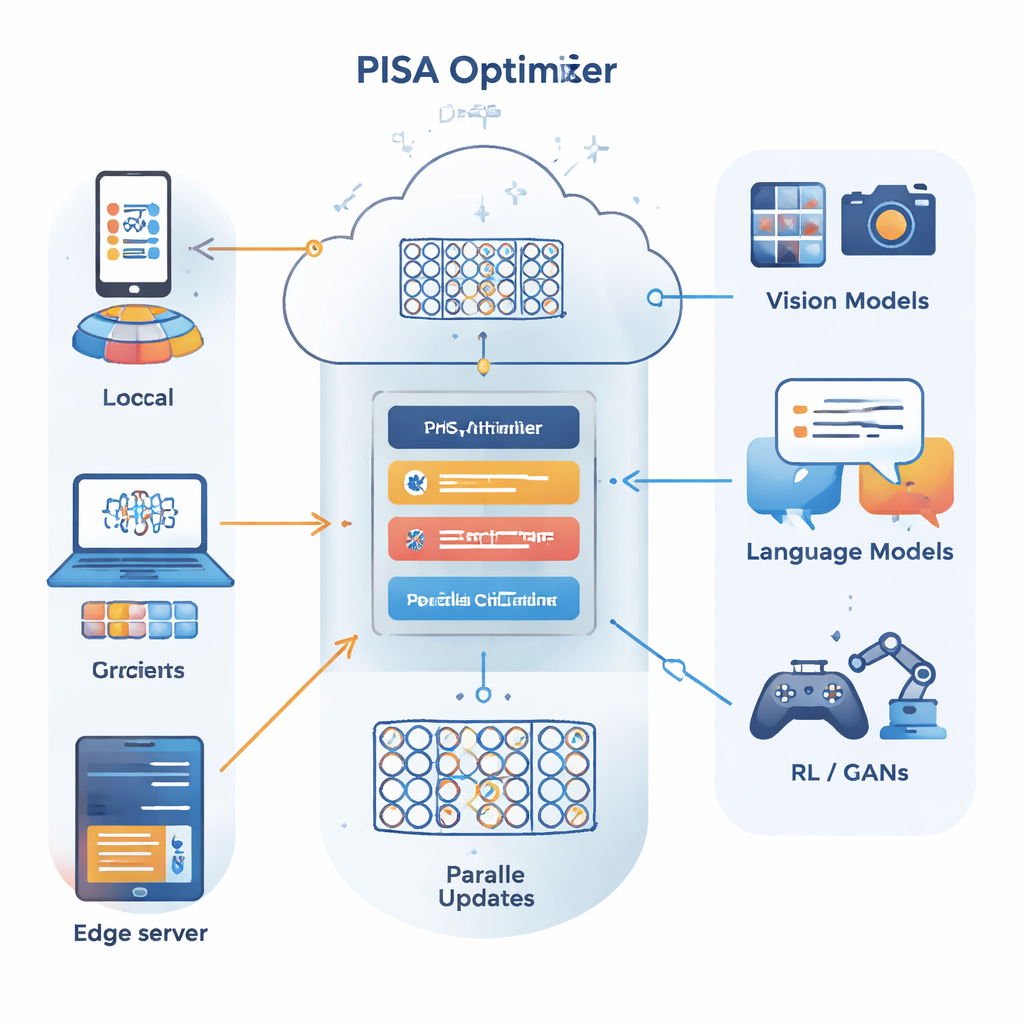
Starkare garantier med mildare antaganden
Ett särskiljande drag hos PISA är dess teoretiska grund. Författarna bevisar att deras algoritm konvergerar under ett enda, relativt milt antagande: att gradienten av förlustfunktionen är Lipschitz-kontinuerlig inom en begränsad region, ett villkor som uppfylls av många standardförluster för neurala nätverk. Till skillnad från de flesta stokastiska metoder kräver PISA inte att gradienter är obiaserade, att de har begränsad varians eller att de kommer från perfekt blandade data. Trots denna avslappnade uppsättning uppnår metoden en linjär konvergenshastighet i termer av hur snabbt funktionsvärden och parameteruppdateringar stabiliseras, vilket placerar den bland de bäst presterande algoritmerna i jämförelsetabellen som ges. Detta gör PISA särskilt attraktiv för heterogena, icke-uniforma datadistributioner som är vanliga i verkliga implementationer.
Praktiska varianter för verkliga djupa nätverk
För att göra ramen praktisk för stora neurala nätverk introducerar författarna två effektiva varianter, SISA och NSISA. SISA använder information om andramomentet—i huvudsak att spåra hur stora tidigare uppdateringar har varit i varje parameterriktning—för att bilda enkla diagonala preconditioners, liknande idéer bakom Adam och RMSProp men inbäddade i ADMM-strukturen. NSISA går ett steg längre genom att införliva en teknik känd som Newton–Schulz-orthogonalisering, inspirerad av Muon-optimizeraren, för att bättre anpassa momentum till användbara riktningar i parameterspace. Båda varianterna behåller PISA:s konvergensgarantier samtidigt som de håller beräkningen lätt nog för moderna GPU:er och stora modeller.
Prestanda över vision-, språk- och generativa modeller
Författarna testar SISA och NSISA över ett brett urval av uppgifter inom djupinlärning. I federerade inlärningsexperiment med avsiktligt snedvridna etikettfördelningar—en svår miljö där varje klient bara ser en delmängd av klasserna—överträffar SISA dramatiskt populära metoder som FedAvg, FedProx, FedNova och Scaffold och uppnår mycket högre testnoggrannhet på benchmarks som MNIST och CIFAR-10. För standardbildklassificering med modeller som ResNet och DenseNet på CIFAR-10 och ImageNet matchar eller överträffar SISA starka optimerare inklusive SGD med momentum, AdaBelief och AdamW. Vid finjustering av GPT2-språkmodeller i ökande storlekar ger NSISA lägre valideringsförlust på kortare väggklocktid än specialiserade optimerare såsom Shampoo, SOAP, Adam-mini och Muon, med fördelen som blir mer uttalad för den största modellen. Den stabiliserar också träningen av generativa adversariella nätverk och uppnår lägre Fréchet inception distance-poäng, vilket mäter den visuella kvaliteten och mångfalden hos genererade bilder. 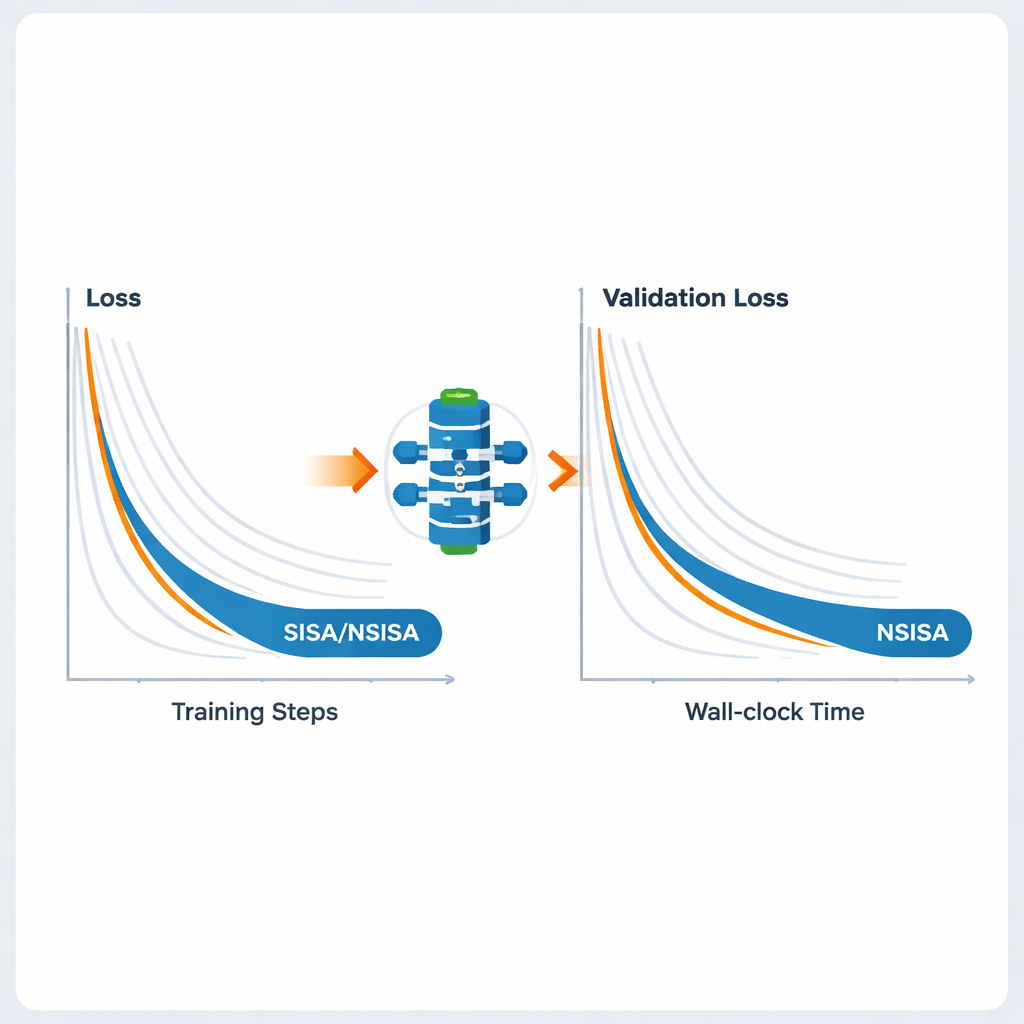
Vad detta betyder för vardags-AI
Enkelt uttryckt visar detta arbete att det är möjligt att träna kraftfulla AI-modeller snabbare och mer pålitligt, även när data är röriga, obalanserade eller spridda över många enheter. Genom att omdesigna den underliggande optimeringsprocessen snarare än att bara justera inlärningshastigheter ger PISA och dess varianter ett enhetligt verktyg som fungerar väl för vision, språk, förstärkningsinlärning och generativa uppgifter. För slutanvändare kan resultatet bli smartare personalisering på telefoner, mer kapabla språk- och bildmodeller och effektivare användning av beräkningsresurser i stora datacenter—allt möjliggjort av en träningsalgoritm som bättre överensstämmer med verkligheten i moderna AI-system.
Citering: Zhou, S., Wang, O., Luo, Z. et al. Preconditioned inexact stochastic ADMM for deep models. Nat Mach Intell 8, 234–245 (2026). https://doi.org/10.1038/s42256-026-01182-3
Nyckelord: optimering för djupinlärning, federerad inlärning, stokastisk ADMM, stora språkmodeller, heterogen data