Clear Sky Science · sv
När stora språkmodeller är pålitliga för att bedöma empatisk kommunikation
Varför maskinempati spelar roll för dig
Allt oftare vänder sig människor till chattbotar och digitala assistenter när de är stressade, ensamma eller står inför svåra beslut. Dessa system kan låta omtänksamma och förstående — men kan de också bedöma om ett meddelande verkligen är stödjande och vänligt? Den här artikeln undersöker när stora språkmodeller (LLM:er), tekniken bakom många chattbotar, kan pålitligt utvärdera hur empatiskt ett skriftligt svar känns, och vad det betyder för vardagliga verktyg som välmåendappar, virtuella terapeuter och kundtjänstrobotar. 
Att studera stödjande samtal
Forskarna analyserade 200 verkliga textbaserade samtal där en person beskrev ett personligt problem — till exempel arbetsstress, familjekonflikt, ekonomiska bekymmer eller svårigheter med psykisk hälsa — och en annan person försökte svara stödjande. Dessa samtal hämtades från fyra befintliga dataset, vardera kopplade till en uppsättning frågor för att bedöma empati. Några fokuserade på huruvida den som svarade visade förståelse eller erbjöd emotionellt tröst; andra frågade om de gav praktiska råd, uppmuntrade talaren att säga mer eller istället centrerade samtalet kring sig själva. Tillsammans bryter dessa ramverk ner ”att vara empatisk” i 21 specifika beteenden som kan betygsättas på skalor, ungefär som en kundnöjdhetsundersökning.
Experter, crowdworkers och maskiner
För att se hur väl LLM:er kan bedöma empati jämförde teamet tre typer av bedömare: kommunikationsexperter, internetbaserade crowdworkers och moderna språkmodeller. Tre erfarna forskare inom empatisk kommunikation betygsatte oberoende varje samtal på samtliga 21 beteenden. Crowdworkers — vardagliga internetanvändare — hade redan lämnat betyg för samma meddelanden i tidigare studier. Slutligen uppmanades tre ledande språkmodeller, med tydliga instruktioner på vanlig svenska och exempel på experternas betyg, att skatta varje samtal på samma skalor. Denna uppsättning gjorde det möjligt för författarna att mäta hur nära grupperna kom varandra, inte bara i förhållande till ett ”korrekt” svar, utan även sinsemellan. 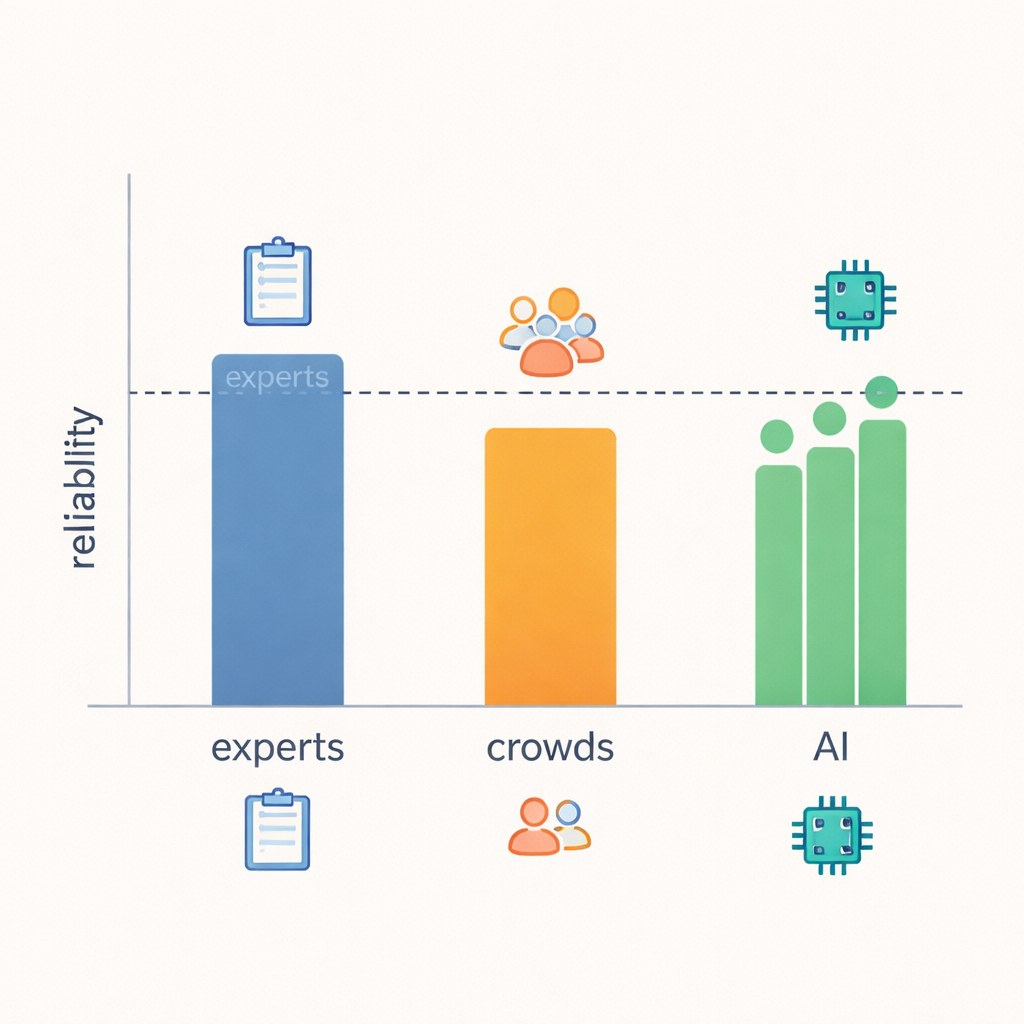
Hur väl överensstämmer de?
Huvudresultatet är att LLM:er kom överraskande nära expertnivå vad gäller tillförlitlighet. När forskarna mätte hur ofta betyg överensstämde och hur stora oenigheterna var, matchade modellerna eller kom nära experterna för de flesta av de 21 beteendena, och de överträffade tydligt crowdworkers. Inom områden med tydliga, observerbara signaler — såsom om ett svar gav praktiska råd, ställde uppföljningsfrågor eller återförde uppmärksamheten till talaren — tenderade experter, LLM:er och även crowds att vara mer överens. Men när det handlade om mer luddiga begrepp, som huruvida ett svar verkligen ”visade förståelse” eller vad den som svarade hade för intentioner, var även experter oftare oense, och LLM:ernas tillförlitlighet sjönk i samma utsträckning. Det tyder på att vissa aspekter av empati helt enkelt är svårare att fastställa från text ensam, oavsett vem som gör bedömningen.
Varför enkla poäng kan vilseleda
Många AI-studier rapporterar framgång med hjälp av välbekanta klassifikationsmått — genom att betrakta varje expertbetyg som obestridlig sanning och mäta hur ofta en modell matchar det. Författarna visar att detta tillvägagångssätt kan ge en förvrängd bild när det gäller subtila mänskliga bedömningar. Till exempel kan ett system få bra resultat genom att mestadels gissa majoritetsbetyget på en obalanserad skala, även om det har svårt med sällsynta men viktiga fall. På samma sätt kan en metod som oftast ger ”nästan rätt” betyg — avvikande med bara en poäng — se dålig ut på en strikt matchningsmetrik, trots att den beter sig mycket likt en mänsklig expert. Genom att fokusera på interbedömar-reliabilitet — hur konsekvent olika bedömare betygsätter samma sak — erbjuder studien en ärligare bild av vad både människor och maskiner kan bedöma på ett tillförlitligt sätt.
Vad detta betyder för vardagens AI
För en lekmannaläsare är slutsatsen både hoppfull och försiktigt. Välkonfigurerade LLM:er kan nu hjälpa till att kontrollera om skriftliga svar — från mänskliga hjälpare eller andra botar — uppfyller expertstandarder för empatisk kommunikation, och de gör det ofta mer konsekvent än otränade mänskliga bedömare. Det kan göra det lättare att övervaka och förbättra chattbotar som används inom vård, utbildning och kundservice. Samtidigt varnar studien för att inte alla ”empatitetst” är likadana: vaga eller överlappande frågor leder till svag mänsklig överensstämmelse och därmed osäkra maskinbedömningar. Innan man litar på AI för att bedöma något så känsligt som känslomässigt stöd bör man först säkerställa att experterna själva kan enas om vad som är ”bra” — och använda den referensen för att avgöra var maskiner säkert kan assistera och var mänskligt omdöme fortfarande är avgörande.
Citering: Kumar, A., Poungpeth, N., Yang, D. et al. When large language models are reliable for judging empathic communication. Nat Mach Intell 8, 173–185 (2026). https://doi.org/10.1038/s42256-025-01169-6
Nyckelord: empatisk kommunikation, stora språkmodeller, AI-kompanjoner, stöd för psykisk hälsa, människa–AI-interaktion