Clear Sky Science · sv
Förbättrad kcat‑prediktion genom rester‑medveten uppmärksamhetsmekanism och förtränade representationer
Varför snabbare enzymprediktioner spelar roll
Enzymer är de små arbetshästarna som håller celler – och hela industrier – i gång. De accelererar kemiska reaktioner som driver vår metabolism, framställer läkemedel och möjliggör grönare tillverkning. Ett nyckeltal som beskriver hur snabbt ett enzym arbetar är omsättningstalet, eller kcat. Att mäta kcat i labbet är tidskrävande och kostsamt, så forskare vänder sig till artificiell intelligens för att förutsäga det utifrån sekvens‑ och reaktionsinformation. Denna artikel presenterar PMAK, en ny AI‑modell som inte bara predicerar kcat mer precist än tidigare verktyg utan också hjälper till att peka ut vilka delar av ett enzym som är viktigast för dess aktivitet.
Från tungt laboratoriearbete till smarta prediktioner
Traditionellt innebär bestämning av kcat noggranna mätningar av hur snabbt ett enzym omvandlar sitt substrat till produkt under strikt kontrollerade förhållanden, såsom fast temperatur och pH. Att göra detta för tusentals enzymer är opraktiskt, vilket begränsar hur väl vi kan modellera hela metaboliska nätverk eller designa nya biokatalysatorer. Tidigare datorbaserade metoder försökte fylla detta gap, men många byggde på handkonstruerade egenskaper eller en förenklad bild av ett enzym och en enskild substrat. De fungerade ofta bra endast när nya enzymer var mycket lika de som redan fanns i träningsdata och hade svårt med verkligen nya enzymer, nya reaktioner eller konstruerade mutanter.
Att lära datorer enzymers och reaktioners ”språk”
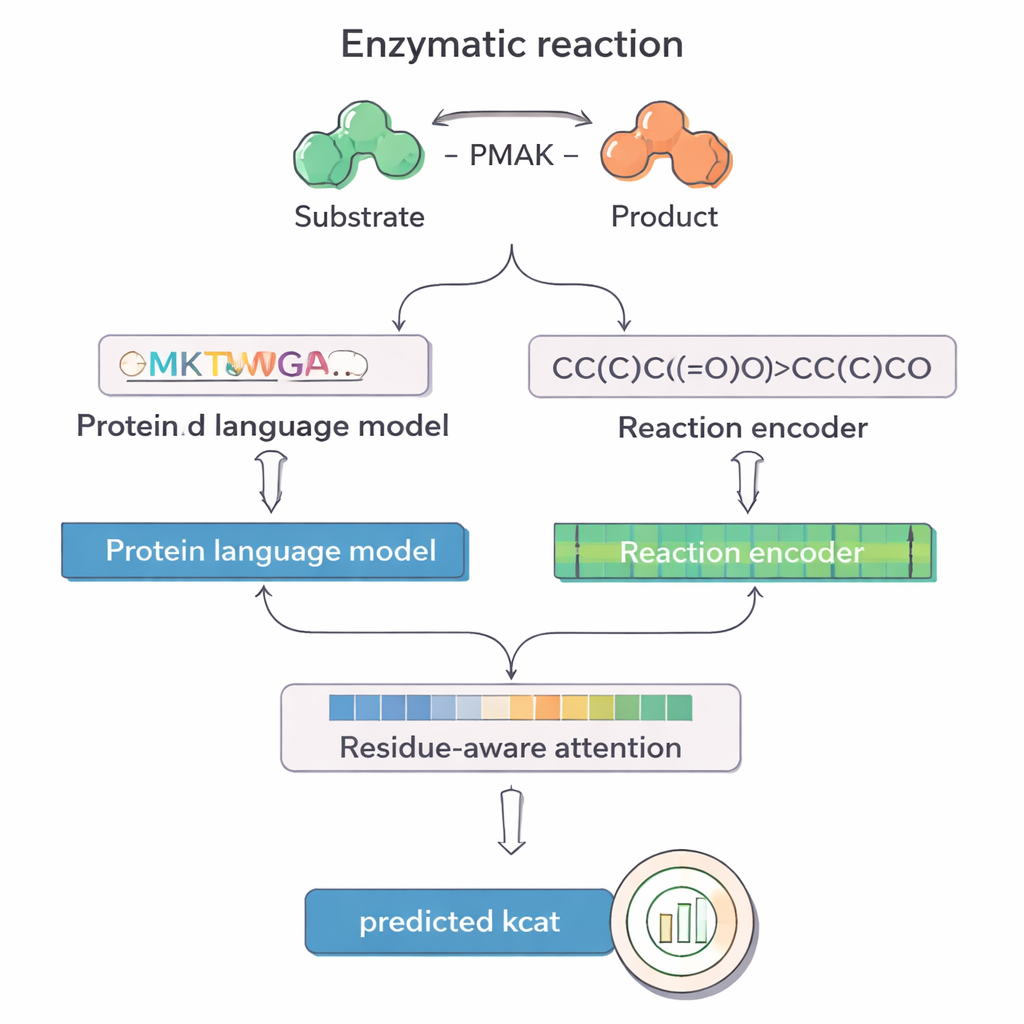
PMAK utnyttjar senaste framstegen inom så kallade språkmodeller som ursprungligen utvecklats för text men som retränats på stora samlingar av proteinsekvenser och kemiska reaktioner. En modell, kallad ProT5, omvandlar ett enzyms aminosyrasekvens till en rik numerisk representation som fångar mönster lärda från miljontals proteiner. En annan modell, RXNFP, gör motsvarande för hela reaktioner skrivna som SMILES‑strängar, vilka kodar alla reaktanter och produkter. PMAK matar in dessa två inlärda representationer i ett neuralt nätverk som anpassar deras dimensioner och gör det möjligt för modellen att beakta både enzymet och hela reaktionskontexten tillsammans, snarare än att behandla dem separat.
Att lyfta fram de viktigaste byggstenarna
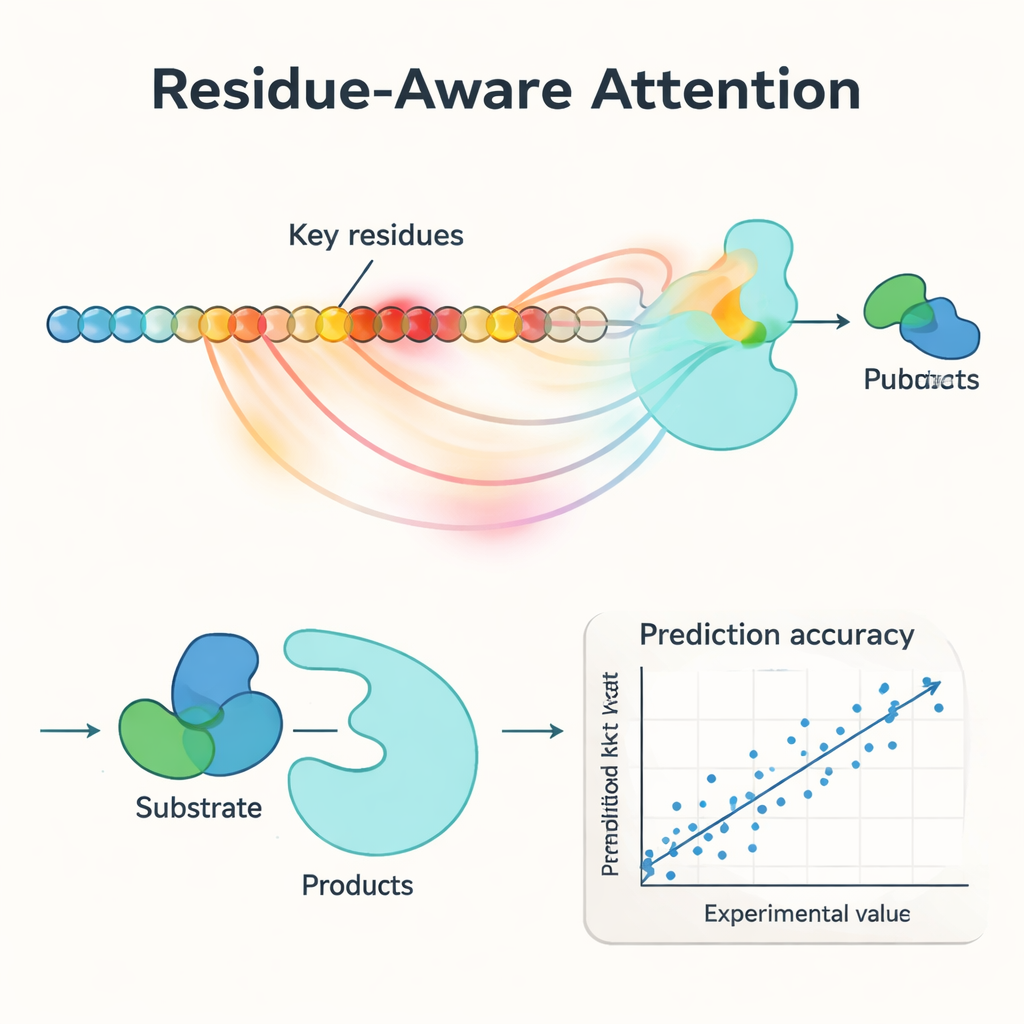
En central innovation i PMAK är en ”rester‑medveten uppmärksamhets”mekanism. Istället för att behandla varje aminosyra i ett enzym som lika viktig lär sig modellen att tilldela högre vikt till specifika rester som spelar störst roll för den aktuella reaktionen. Dessa uppmärksamhetspoäng fungerar som en strålkastare på sekvensen: när forskarna jämförde dem med kända aktiva och bindande ytor från proteinstrukturer fann de att PMAK konsekvent framhöll funktionella rester långt oftare än slumpen. Modellen presterade också väl när aktiva ytor definierades mer brett för att inkludera närliggande rester i 3D‑rymden, vilket tyder på att den fångar subtila strukturella och kemiska signaler relevanta för katalys.
Bra prestanda på nya enzymer, nya reaktioner och mutanter
Författarna testade PMAK noggrant på en kurerad datamängd med mer än 4 000 kcat‑värden som täcker nästan 3 000 enzymer och 2 800 reaktioner. Under så kallade ”varmstart”‑förhållanden – där liknande enzymer och reaktioner förekommer i både tränings‑ och testset – matchade eller överträffade PMAK de bästa befintliga modellerna. Ännu mer imponerande var att i ”kallstart”‑tester där antingen enzymet eller reaktionen i testsetet aldrig setts tidigare, presterade PMAK bättre än en rad ledande metoder. Den förblev användbar även för enzymer med mycket låg sekvenslikhet till träningsdata och för reaktioner som såg betydligt annorlunda ut än de den lärt sig från. PMAK förbättrade också prediktioner i realistiska tillämpningar, såsom att uppskatta hur celler fördelar sina begränsade proteinresurser och att förutsäga effekter av mutationer i dataset från enzymteknik.
Vad detta innebär för biologi och bioteknik
För icke‑specialister kan PMAK ses som en smart assistent som lär sig från massiva protein‑ och reaktionsbibliotek för att gissa hur snabbt ett visst enzym kommer att arbeta i en given reaktion – och förklara vilka aminosyror som driver det beteendet. Genom att kombinera förbättrad noggrannhet med insikt på rester‑nivå kan detta tillvägagångssätt hjälpa forskare att designa bättre enzymer, bygga mer tillförlitliga metaboliska modeller och utforska hur mutationer påverkar funktion utan att utföra varje experiment i labbet. När liknande modeller utvidgas till andra kinetiska egenskaper kan de bli centrala verktyg för att designa renare industriprocesser, optimera mikrober för hållbar produktion och fördjupa vår förståelse för hur livets molekylära maskiner uppnår sin anmärkningsvärda hastighet.
Citering: Cai, Y., Ge, F., Zhang, C. et al. Enhancing kcat prediction through residue-aware attention mechanism and pre-trained representations. Commun Biol 9, 273 (2026). https://doi.org/10.1038/s42003-026-09551-9
Nyckelord: enzymkinetik, djupinlärning, kcat‑prediktion, proteindesign, metabolisk modellering