Clear Sky Science · sv
Beräkning av epitopheterogenitet i immunofärgningar från serier av antikroppsutspädningar
Varför antikroppsfärgningens kvalitet spelar roll
Från att följa cancerceller till att diagnostisera infektioner förlitar sig modern biologi starkt på antikroppar som ”lyser upp” specifika molekyler inuti celler. Ändå brottas många labb i det tysta med ett envist problem: färgningar som är för svaga, för brusiga eller helt enkelt missvisande. Denna artikel presenterar ett praktiskt, datorbaserat sätt att läsa ut mer information ur en rutinmässig serie av antikroppsutspädningar, vilket hjälper forskare att finjustera sina färgningar för renare bilder, mer tillförlitliga mätningar och till och med nya sätt att färga flera mål i en enda färgkanal. 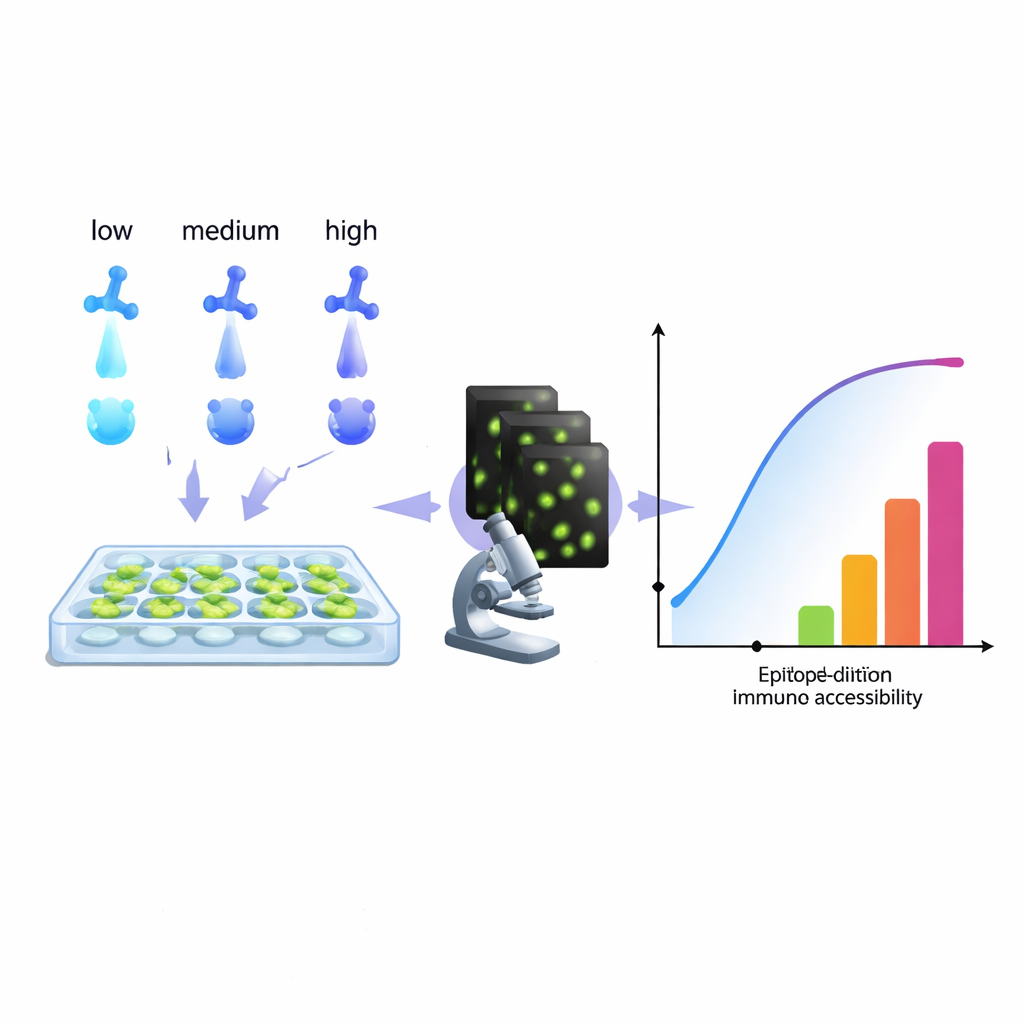
Hur forskare vanligtvis justerar antikroppsfärgningar
När forskare sätter upp ett immunfärgningsförsök gissar de vanligtvis en antikroppskoncentration utifrån databladet, provar några utspädningar och väljer den som ”ser bra ut”. Men bakom kulisserna avgör otaliga små faktorer—proteiners form, trängsel inuti celler, pH och hur väl antikroppen kan vrida sig på plats—om antikroppen fäster eller sköljs bort. Traditionella verktyg som mäter antikroppsbindning, såsom surface plasmon resonance, fungerar bäst på renade proteiner på konstgjorda ytor, inte på tätt packade celler eller vävnader. Det betyder att de värden de ger kanske inte överensstämmer med det verkliga biologiska system där antikroppen faktiskt används. Som följd kan labb omedvetet välja koncentrationer som förstärker suddigt bakgrundsbrus eller döljer viktiga men mindre åtkomliga mål.
Förvandla enkla utspädningsserier till ’tillgänglighetskartor’
Författarna föreslår ett annat angreppssätt: behandla en standardiserad serie av antikroppsutspädningar som en rik datamängd och anpassa den med en modell som speglar vad bildgivningen faktiskt ser—antikroppar som förblir bundna även efter upprepade tvättar. Genom att analysera hur signalen växer över koncentrationer rekonstruerar deras algoritm ett ”tillgänglighetshistogram”. Istället för att försöka isolera rena kemiska bindningskonstanter grupperar detta histogram målställen i tekniska ”epitopklasser” baserat på hur lätta de är att färga under verkliga förhållanden. Ett biologiskt epitop kan förekomma i flera klasser om det till exempel är lätt att nå på en del av en cell men svårare i ett trångt område. Avgörande är att denna metod arbetar direkt med mikroskopets avläsning, utan att behöva renade proteiner eller extra hårdvara, så vilket labb som helst som kan köra en utspädningsserie och kvantifiera fluorescens i princip kan bygga sådana histogram. 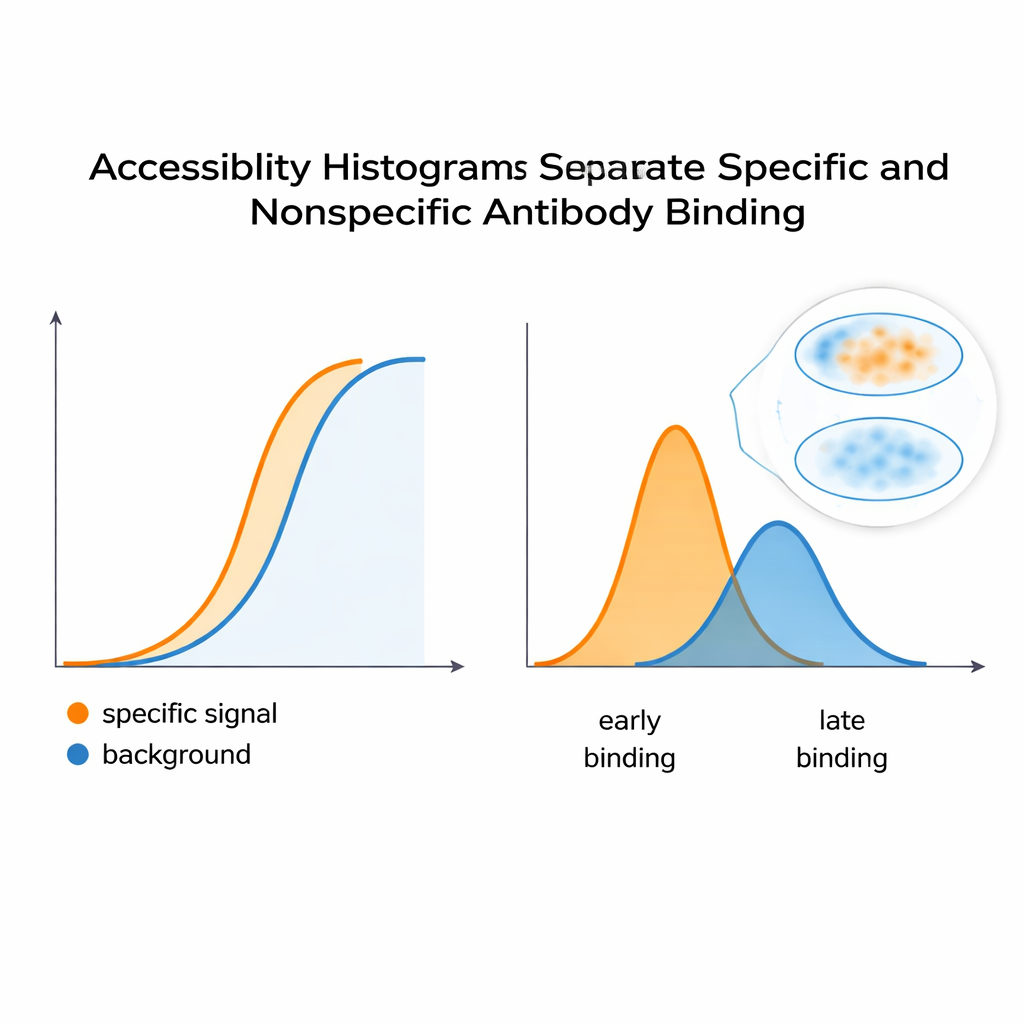
Separera verklig signal från bakgrund
För att testa om dessa histogram verkligen fångar färgningsbeteendet byggde teamet ett kontrollerat system med HeLa-celler och två monoklonala antikroppar: en som efterliknar en önskad, specifik signal och en annan som fungerar som oönskad bakgrund. När de blandades såg den kombinerade fluorescenskurvan ut som ett enda, slätt svar—inget tydligt avslöjade två distinkta bidragsgivare. Men den beräkningsmässiga analysen delade upp denna kurva i separata toppar i tillgänglighetshistogrammet och avslöjade minst två underliggande epitopklasser. En liknande strategi applicerad på en antikropp som känner igen en formkänslig plats på en regulatorisk enhet av PKA visade att förändringar i proteinets konformation—utlösta av molekylen cAMP—försköt fördelningen av tillgängliga epitoper. Detta tyder på att metoden kan flagga när proteinstrukturer öppnar eller stänger sig, vilket förändrar hur lätt antikroppar kan binda inuti celler.
Välja bättre utspädningar och färga mer med en färg
Eftersom varje topp i tillgänglighetshistogrammet bidrar mest över ett visst koncentrationsintervall använder författarna dessa toppar som vägledning för att välja ”söta punkt”-utspädningar. Toppar med låg tillgänglighet som bara syns vid mycket höga antikroppsnivåer är troligen kopplade till ospecifik bindning, medan tidiga toppar ofta speglar det avsedda målet. Genom att modellera hur individuella toppar bygger upp den övergripande dos–responskurvan kan teamet föreslå utspädningar som maximerar specifik signal innan problematiska toppar slår in—ibland mycket mer utspädda än leverantörens rekommendationer. De utvidgar dessutom idén till en listig form av ”beräkningsmässig multiplexering”. Genom att färga samma fixerade prov upprepade gånger med noggrant valda koncentrationer, ta bilder efter varje omgång och subtrahera tidigare bilder från senare, isolerar de signaler kopplade till olika tillgänglighetsklasser och skiljer effektivt åt flera mål inom en enda fluorescenskanal.
Vad detta betyder för vardagligt labbarbete
Enkelt uttryckt förvandlar detta arbete ett rutinmässigt felsökningssteg—att köra en serie av antikroppsutspädningar—till ett kvantitativt verktyg. Tillgänglighetshistogrammen hjälper forskare att upptäcka dold komplexitet i sina färgningar, välja utspädningar som minskar missvisande bakgrund och i vissa fall separera överlappande signaler utan att behöva extra fluorescerande markörer. Även om den underliggande modellen är avsiktligt enkel och inte fångar varje molekylär detalj är den utformad för att vara lätt att använda och tillräckligt robust för verkliga data. Om metoden antas brett kan detta göra antikroppsbaserade tekniker—från grundläggande bildhantering till diagnostiska tester—mera pålitliga, mer informativa och mindre beroende av försök och misstag.
Citering: Tschimmel, D., Saeed, M., Milani, M. et al. Computational epitope heterogeneity analysis in immunostainings from antibody-dilution series. Commun Biol 9, 238 (2026). https://doi.org/10.1038/s42003-026-09517-x
Nyckelord: antikroppsfärgning, immunofluorescens, epitoptillgänglighet, doserespons, beräkningsmässig multiplexering