Clear Sky Science · sv
Definiera operationell säkerhet i kliniska artificiella intelligenssystem
Varför säker AI inom medicin är viktig
Sjukhus inför snabbt artificiell intelligens för att tolka skanningar och flagga sjukdom, men det finns en fråga vanliga noggrannhetssiffror inte kan besvara: när är det faktiskt säkert att låta maskinen fatta beslutet? Denna artikel introducerar ett praktiskt sätt att avgöra när läkare med trygghet kan förlita sig på ett AI-system, när de bör ignorera det och när de själva måste granska ärendet noggrant. Målet är inte bara att bygga smartare algoritmer, utan att integrera dem i den dagliga vården på ett sätt som skyddar patienter, minskar onödiga undersökningar och lättar bördan för kliniker istället för att öka den.
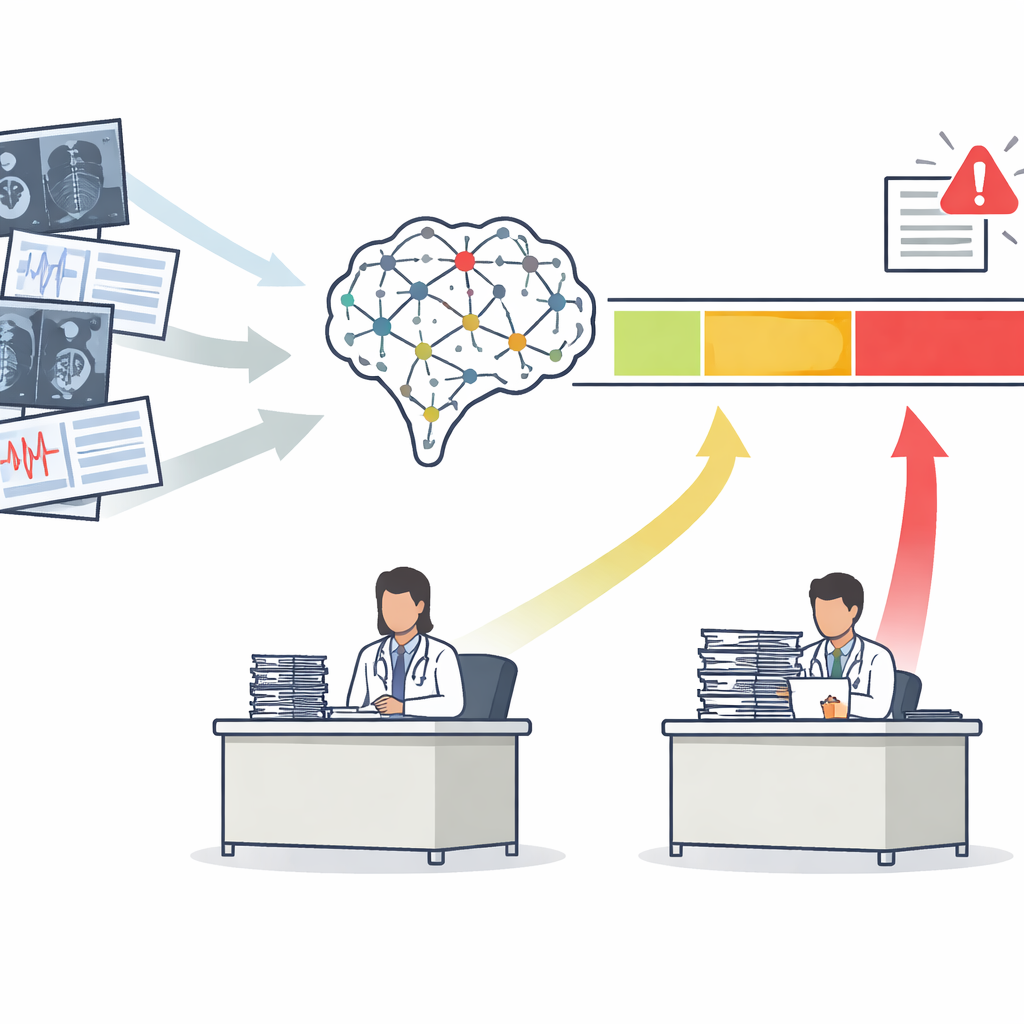
Från en poäng till tre tydliga handlingszoner
De flesta medicinska AI-verktyg ger ett enda riskscore, till exempel sannolikheten att en mammografi visar cancer. Traditionellt bedömer utvecklare dessa verktyg med en kurva som sammanfattar hur väl de skiljer sjuka från friska patienter överlag. Författarna argumenterar för att detta inte är tillräckligt. De föreslår Safety-Aware ROC (SA-ROC)-ramverket, som utgår från samma riskscorer men omformar dem till tre praktiska regioner. En hög-poängs "rule-in"-zon innehåller patienter vars resultat är tillräckligt pålitliga för att utlösa åtgärd, såsom brådskande uppföljning. En låg-poängs "rule-out"-zon innehåller patienter vars resultat är tillräckligt pålitliga för att säkert nedprioritera. Däremellan ligger en "gråzon" av osäkerhet, där AI:n inte är tillräckligt pålitlig och en mänsklig expert måste granska fallet.
Låta kliniker sätta säkerhetsnivån
Avgörande är att SA-ROC tillåter kliniker och institutioner att själva definiera sina säkerhetsmål i förväg. De väljer hur säkra de vill vara innan de agerar på ett positivt resultat (minimalt acceptabel sannolikhet att ett flaggat fynd faktiskt är onormalt) och hur säkra de vill vara innan de slappnar av på ett negativt resultat (minimalt acceptabel sannolikhet att ett rensat fall faktiskt är normalt). Med dessa mål söker ramverket igenom modellens scorer för att hitta de exakta gränser som uppfyller dem. Scorer över den övre gränsen bildar rule-in-säkert zon, scorer under den nedre gränsen bildar rule-out-säker zon, och allt däremellan blir gråzonen. Ramverket kvantifierar sedan hur många patienter som hamnar i varje region och hur mycket osäker arbetsbelastning—fall som skickas tillbaka till människor—AI:n lämnar olöst.
Avslöja dolda skillnader mellan liknande AI:er
Författarna visar att två AI-system med nästan identisk traditionell noggrannhet kan bete sig mycket olika när de betraktas genom detta säkerhetsperspektiv. I simuleringar producerade modeller med samma övergripande prestanda mycket olika storlekar på rule-in-, rule-out- och gråzonerna beroende på hur deras scorer var fördelade. Den ena kan vara utmärkt på att med hög säkerhet bekräfta sjukdom, medan den andra kan vara bra på att säkert rensa stora mängder låg-riskpatienter. I en verklig fallstudie av två verktyg för bröstcancerscreening som godkänts av U.S. Food and Drug Administration var systemet med det högre standardiserade noggrannhetsscoret faktiskt sämre för högkonfidensscreening. Vid den striktaste säkerhetsinställningen—ingen förlorad cancer tillåten i låg-riskgruppen—avlägsnade det till synes svagare systemet säkert nästan dubbelt så många kvinnor från radiologens kö. SA-ROC blottlägger därmed en sorts "prestandaomkastning" som konventionella mått döljer.
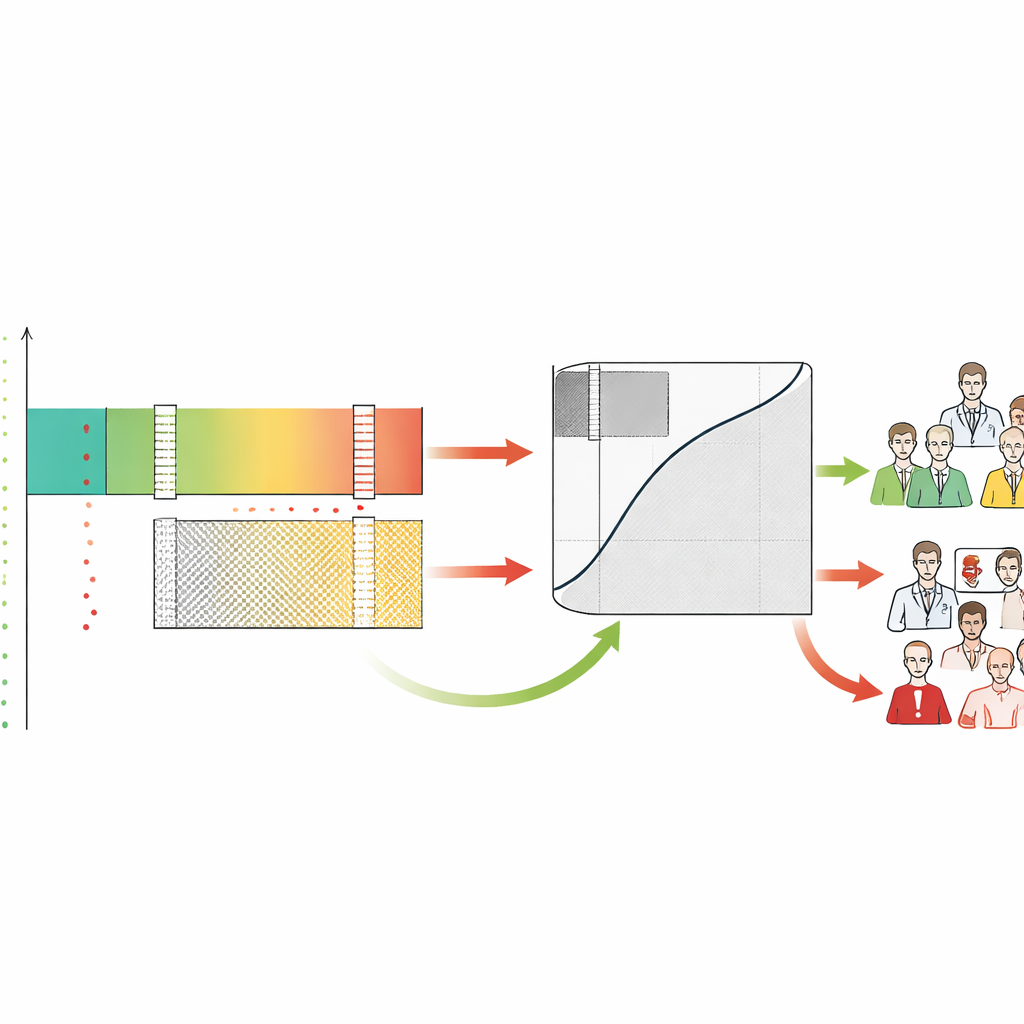
Förstå mänsklig–AI-spänning och arbetsbelastning
Genom att märka varje fall som rule-in, rule-out eller grå avslöjar ramverket också hur mänskliga läkare beter sig i dessa zoner. Författarna fann att radiologer ofta överdiagnostiserade fall som AI bedömde som säkert låg risk, vilket genererade många falska alarmer i just den region där maskinen var mest pålitlig. Däremot kämpade både människor och AI i gråzonen, vilket validerar den som det område som verkligen kräver expertgranskning. SA-ROC fångar storleken på denna gråzon i ett enda tal, vilket representerar kostnaden för obeslutsamhet. En liten gråzon innebär mer säker automatisering och mindre mänsklig arbetsbelastning; en stor gråzon betyder att många fall fortfarande kräver noggrann manuell granskning och att systemet kan öka utmattning i stället för att lindra den.
Göra säkerhetsregler till vardaglig praxis
Utöver mätning är ramverket utformat som ett styrningsverktyg som förvandlar policyer till konkret AI-beteende. Sjukhus kan använda det på två sätt. För det första kan de direkt specificera säkerhetskrav eller gränser för hur många fall de är villiga att skicka till gråzonen och låta ramverket beräkna motsvarande trösklar. För det andra kan de tilldela värden och straff för olika utfall—att upptäcka en cancer, missa en, beställa ett onödigt test eller hänskjuta till mänsklig granskning—och låta ramverket söka efter den policy som maximerar det totala värdet. Dessa strategier kan anpassas för mycket olika mål, såsom masscreeningsprogram, specialistremisser eller forskningskohorter, alla med samma underliggande modell.
Vad detta betyder för patienter och kliniker
Enkelt uttryckt erbjuder detta arbete ett sätt att säga inte bara "denna AI är noggrann", utan "här är exakt när och hur den kan litas på i kliniken". Genom att skära upp AI-utdata i säkra, osäkra och osäkra/obestämda regioner knutna till uttryckliga säkerhetslöften hjälper SA-ROC vårdsystem att avgöra när maskiner kan agera själva och när människor måste behålla bestämmanderätten. Det understryker att traditionella noggrannhetssiffror kan vara vilseledande och att verklig säkerhet beror på hur en modell beter sig vid de extrema områden där fel är som kostsammast. Om det antas i större utsträckning och valideras i större, verkliga miljöer kan detta ramverk stödja mer pålitlig automatisering, minska onödiga larm och tester och förvandla de svåraste AI-ärendena—gråzonen—till en fokuserad källa för lärande och förbättring för både algoritmer och medicin i stort.
Citering: Kim, YT., Kim, H., Bahl, M. et al. Defining operational safety in clinical artificial intelligence systems. npj Digit. Med. 9, 281 (2026). https://doi.org/10.1038/s41746-026-02450-7
Nyckelord: klinisk artificiell intelligens, operationell säkerhet, medicinsk avbildning, beslutsstöd, riskstratifiering