Clear Sky Science · sv
Storskalig självövervakad videobaserad grundmodell för intelligent kirurgi
Smarare stöd i operationssalen
Moderna kirurger förlitar sig i allt större utsträckning på kameror och datorer för att vägleda sitt arbete, men dagens artificiella intelligens har fortfarande svårt att fullt ut förstå vad som händer under en operation. Denna artikel presenterar ett nytt sätt att träna AI på tusentals operationsvideor så att den bättre kan följa ett ingrepps steg, känna igen instrument och vävnader samt bedöma hur säkert och skickligt operationen fortskrider. På längre sikt kan sådan teknik stödja kirurger i realtid, förbättra utbildning och bidra till säkrare kirurgi för patienter.
Varför det är svårt att lära maskiner om kirurgi
Att lära datorer att förstå kirurgi är inte så enkelt som att mata dem med några märkta bilder. Varje ingrepp innebär rörliga kameror, förändrade perspektiv, rök, blod samt händer och verktyg som hela tiden skymmer varandra. Dessutom finns tusentals olika typer av operationer, varav många är sällsynta. Att noggrant märka videodata bildruta för bildruta kräver expertresurser som är knapphändiga och blir snabbt för kostsamt. Tidigare AI-system försökte lindra denna börda med metoder som lär från omärkta bilder, men de tittade mest på stillbilder och försökte först senare lägga in en känsla för tid. Som en följd missade de ofta operationens berättelse: vad som föregick, vad som händer nu och vad som sannolikt kommer att ske härnäst.
Lära direkt från kirurgiska filmer
Författarna hävdar att en AI som är avsedd att assistera i kirurgi bör tränas på videor snarare än på isolerade bilder. För detta ändamål samlade de ihop en av de största samlingarna av endoskopiska operationsvideor hittills: 3 650 inspelningar med 3,55 miljoner bildrutor, hämtade från öppna forskningsdatamängder och ett brett urval av kirurgiskt videomaterial online. Dessa videor täcker mer än 20 typer av ingrepp och över 10 anatomiska regioner, från gallblåseuttagning till leverkirurgi och gynekologiska operationer. Denna mångfald låter AI:n se många sätt ett ingrepp kan se ut i verkligheten, inklusive olika sjukhus, instrument och kamerastilar.
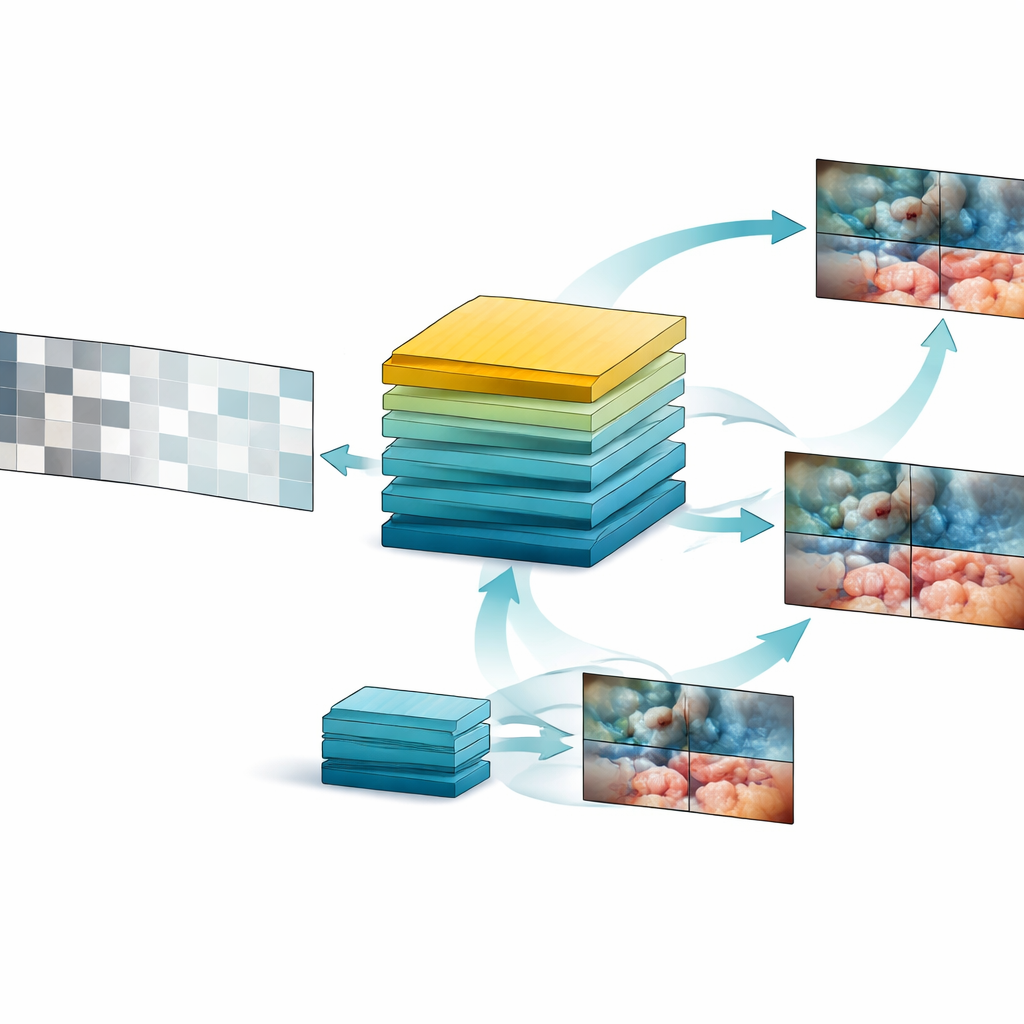
En ny videofokuserad inlärningsplan
Byggt på denna dataskatt designade teamet SurgVISTA, en ”grundmodell” speciellt anpassad för kirurgiska videor. Istället för att försöka märka varje bildruta lär sig SurgVISTA genom att fylla i det som saknas. Under träningen döljs delar av varje videoclip och modellen måste rekonstruera de saknade regionerna. Detta tvingar den att uppmärksamma hur vävnader, instrument och rörelser förändras över tid. Samtidigt lärs en andra gren av systemet att matcha de detaljerade visuella signalerna från en stark bildbaserad expertmodell som redan kan mycket om kirurgiska scener. Denna kombination hjälper SurgVISTA att greppa både de finare detaljerna inom varje bildruta och det bredare flödet i hela operationen, allt inom ett enda enhetligt nätverk.
Sätta modellen på prov
För att se om detta tillvägagångssätt verkligen ger resultat testade författarna SurgVISTA på 13 olika dataset som omfattade sex typer av kirurgi och fyra praktiska uppgifter. Dessa uppgifter inkluderade att känna igen vilken fas av en operation som pågår, identifiera specifika kirurgiska handlingar, fånga trefaldsrelationen mellan instrument, handling och målvävnad samt bedöma hur säkert nyckelsteg har utförts. Överlag slog SurgVISTA ledande modeller som tränats på vardagsvideor, liksom de bästa befintliga kirurgifokuserade systemen som till största delen byggde på stillbilder. Den presterade starkt även på procedurer den aldrig sett under träning, vilket visar att de mönster den lärde sig inte var bundna till ett enda organ, verktygsset eller sjukhus.
Varför mer och rikare videodata spelar roll
Studien undersökte också hur prestandan förändrades när mer träningsdata lades till. När författarna successivt ökade storleken och variationen i videopoolen förbättrades SurgVISTA:s resultat nästan överallt, även på procedurer som inte förekom i träningsuppsättningen alls. Intressant nog gynnades modellen inte bara av fler exempel av samma operation, utan också av olika typer av kirurgi: exponering för varierade kirurgiska ”berättelser” hjälpte den att upptäcka generella visuella och rörelsemönster som överförs mellan specialiteter. Ytterligare experiment visade att den extra vägledningen från den bildbaserade experten ytterligare skärpte modellens förmåga att bevara fin anatomisk detalj, vilket är avgörande för att till exempel skilja en vital struktur från omgivande vävnad.
Vad detta betyder för framtidens kirurgi
Kort sagt visar detta arbete att en AI tränad på stora mängder verkliga operationsvideor, med både rumsliga och tidsmässiga aspekter i åtanke, kan bygga en mycket djupare förståelse för vad som händer i operationssalen. SurgVISTA är ännu inte ett verktyg som fattar egna beslut, men det utgör en kraftfull ryggrad som andra tillämpningar kan koppla in—oavsett om det gäller att följa kirurgiskt framsteg, flagga riskfyllda ögonblick, stödja utbildning eller jämföra tekniker mellan sjukhus. Författarna konstaterar att bredare data och klinisk testning fortfarande behövs, men deras resultat tyder på att videobaserade grundmodeller kan bli en nyckelingrediens i framtida intelligenta kirurgisystem som syftar till att göra ingrepp säkrare, mer konsekventa och bättre anpassade till varje patient.
Citering: Yang, S., Zhou, F., Mayer, L. et al. Large-scale self-supervised video foundation model for intelligent surgery. npj Digit. Med. 9, 220 (2026). https://doi.org/10.1038/s41746-026-02403-0
Nyckelord: kirurgisk video-AI, självövervakad inlärning, operativt arbetsflöde, datorstödd kirurgi, rumslig-tidsmässig modellering