Clear Sky Science · sv
Utvärdering av stora språkmodeller för generering av diagnostiska slutsatser från fynd i hjärn‑MRI: en multicenter‑benchmark och läsarstudie
Varför smartare MR‑rapporter spelar roll för patienterna
När du får en hjärnscanning måste en radiolog omvandla tusentals nyanser av grått till ett tydligt uttalande om vad som är fel — eller att allt ser normalt ut. Denna slutliga “impression” styr avgörande beslut vid strokevård, hjärntumörer, infektioner och mer. Men att läsa hjärn‑MRI är komplext och tidskrävande, och överbelastade läkare kan göra misstag, särskilt på upptagna sjukhus. Denna studie undersöker om avancerade artificiella intelligens‑språkmodeller kan pålitligt hjälpa radiologer att omvandla skriftliga MRI‑fynd till korrekta, snabba och konsekventa diagnostiska slutsatser.
Att förvandla råa scanningsbeskrivningar till tydliga svar
Hjärn‑MRI genererar en serie bilder som radiologer beskriver i en skriftlig “fynd”‑sektion, där de noterar var en förändring sitter, hur ljus den ser ut och om det finns svullnad. Den verkliga utmaningen är sedan att kombinera alla dessa detaljer till en diagnostisk slutsats, som ”akut infarkt” eller ”hjärnabscess”. Forskarna samlade 4293 hjärn‑MRI‑rapporter från tre sjukhus i Kina, som täcker 16 diagnostiska kategorier som omfattar mer än 95 % av vardagliga hjärntillstånd. De testade sedan 10 olika stora språkmodeller — avancerade textbaserade AI‑system — för att se hur väl varje modell kunde omvandla de skriftliga fynden till rätt diagnoser.
Stora, välmatade AI‑modeller placerade sig i topp
Teamet jämförde modeller som sträckte sig från ungefär 8 miljarder till 671 miljarder interna parametrar, ungefär jämförbart med att gå från en läkarstudents kunskapsnivå till ett erfaret expertteams. Den största modellen, kallad DeepSeek‑R1, levererade konsekvent bäst prestanda när den fick både strukturerade versioner av fynden och nyckelklinisk information såsom patientens ålder, symtom eller trauma‑anamnes. Under dessa förutsättningar identifierade DeepSeek‑R1 med hög känslighet och specificitet närvaro eller frånvaro av specifika hjärntillstånd, och uppnådde patientnivånoggrannhet över 87 %. Mindre modeller, särskilt de under 10 miljarder parametrar, hade stora svårigheter och fick ofta endast omkring 30 % av fallen rätt — långt under vad som skulle vara acceptabelt i verklig klinisk verksamhet.
Varför struktur och kontext gör AI smartare
Forskarna matade inte modellerna enbart med fri text. De använde också ett annat AI‑system för att omstrukturera rapporterna till tydliga, standardiserade element: var varje förändring var lokaliserad, hur många det fanns och hur de såg ut i olika MRI‑sekvenser. Att lägga till denna struktur och kombinera den med korta kliniska anteckningar gjorde en påtaglig skillnad. För DeepSeek‑R1 ökade övergången från rå fritext till strukturerade fynd plus klinisk kontext känslighet, total noggrannhet och sammanfattande prestandamått. Enkelt uttryckt presterade AI:n mycket bättre när den fick renare, mer organiserad information och lite patientbakgrund — vilket speglar hur mänskliga radiologer också fungerar bäst när rapporterna är tydliga och den kliniska frågeställningen är given.
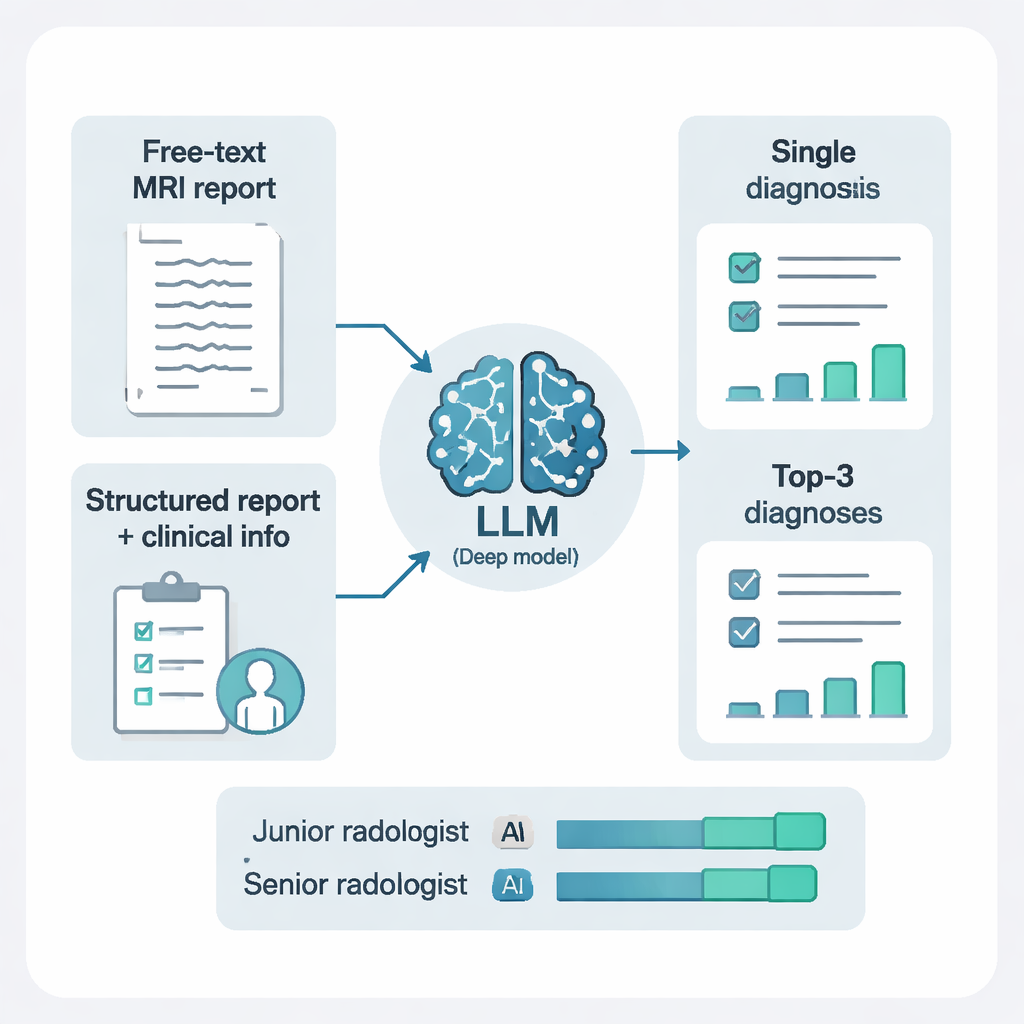
Från enstaka gissning till en rankad kortlista
I verkligheten anger radiologer ofta mer än en möjlig diagnos för svåra fall. Studien testade två uppmaningsstilar: att be AI:n om bara en diagnos, eller om dess tre främsta möjligheter, vardera med en kort förklaring. Att tillåta tre rankade diagnoser förbättrade prestandan dramatiskt. Med detta ”differentialdiagnos”‑sätt dök den korrekta svaret upp någonstans bland de tre bästa förslag i mer än 97 % av patienterna. Detta var särskilt hjälpsamt i komplexa fall som tumörer, blödningar eller inflammatoriska sjukdomar, där en enda tvingad gissning kan vara missvisande men en kort, välmotiverad lista effektivt kan vägleda vidare utredning och behandling.
Verklig påverkan på upptagna radiologer
För att se om dessa vinster spelar roll i praktiken genomförde författarna en läsarstudie med sex radiologer — tre juniora och tre seniora — som tolkade 500 hjärn‑MRI‑rapporter med och utan hjälp av DeepSeek‑R1. Med AI‑assistans steg den totala diagnostiska noggrannheten från ungefär tre fjärdedelar av fallen till mer än 90 %, och ett viktigt kvalitetsmått för precision och återkallning förbättrades också avsevärt. Läsningstiden minskade dessutom, från ungefär en minut per fall till under en minut, vilket kan motsvara tiotals sparade timmar per radiolog varje år. De största fördelarna sågs hos juniora radiologer, vars prestation närmade sig erfarna experters nivå, även om studien också betonade att läkare måste vara försiktiga och inte blint lita på AI, särskilt för mycket subtila tillstånd som vissa typer av hjärnblödning.
Vad detta betyder för framtida hjärnscanningsrapporter
För patienterna är huvudslutsatsen att kraftfulla språkbaserade AI‑system redan kan hjälpa radiologer att omvandla komplexa MRI‑beskrivningar till klarare, mer korrekta diagnostiska slutsatser, särskilt när de får välstrukturerad information och viktiga kliniska detaljer. Dessa verktyg är inte ersättare för mänsklig expertis utan kan fungera som ett andra par noggranna ögon, erbjuda välgrundade förslag och spara tid. Om de valideras bredare och integreras säkert i sjukhussystem skulle sådant AI‑stöd kunna göra hjärnscanningsrapporter snabbare, mer tillförlitliga och mer konsekventa — vilket i slutändan förbättrar vården för personer med stroke, tumörer, infektioner och många andra hjärntillstånd.
Citering: Wang, ML., Zhang, RP., Wu, WJ. et al. Evaluation of large language models for diagnostic impression generation from brain MRI report findings: a multicenter benchmark and reader study. npj Digit. Med. 9, 187 (2026). https://doi.org/10.1038/s41746-026-02380-4
Nyckelord: hjärn‑MRI‑diagnos, radiologi artificiell intelligens, stora språkmodeller, kliniskt beslutsstöd, DeepSeek‑R1