Clear Sky Science · sv
Stora språkmodeller förbättrar överförbarheten hos prediktioner baserade på elektroniska journaler mellan länder och kodsystem
Varför smartare delning av medicinsk data spelar roll
Sjukhus och vårdcentraler världen över sitter på ett rikt informationsförråd: elektroniska journaler som fångar människors diagnoser, behandlingar och utfall över många år. I teorin skulle dessa data kunna hjälpa läkare att tidigt upptäcka vilka patienter som löper hög risk för allvarliga sjukdomar, långt innan symtomen blir tydliga. I praktiken har dagens datorbaserade modeller dock svårt att ”resa” från ett land eller journalsystem till ett annat, eftersom varje plats registrerar hälsodata på olika sätt. Denna studie presenterar en ny metod, kallad GRASP, som använder framsteg inom artificiell intelligens för att överbrygga dessa klyftor så att en modell som tränats i ett vårdsystem kan fungera tillförlitligt i andra.
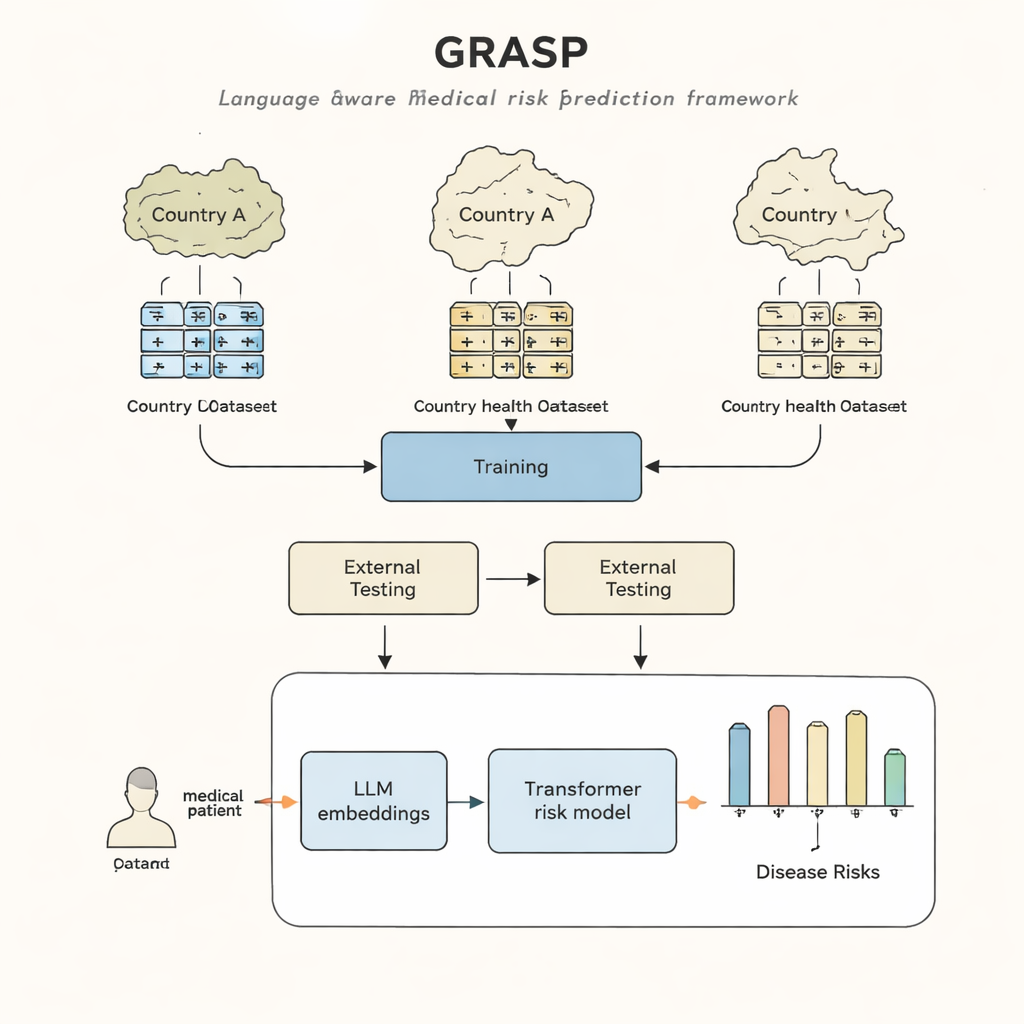
Olika sjukhus, olika språk
Även när läkare behandlar samma sjukdom använder de ofta olika koder och lokala vanor för att registrera den i journalen. Ett sjukhus kan lagra ”högt blodsocker” under en kod, medan ett annat använder en annan kod för ”hyperglykemi”, och ett tredje använder ett helt annat system. Insatser för att tvinga alla till en gemensam standard — som stora internationella kodningsscheman — är användbara men långsamma, kostsamma och lämnar ändå viktiga skillnader kvar. Som ett resultat kan en datorbaserad modell som predicerar sjukdom från journaler i ett land förlora i noggrannhet när den används någon annanstans, vilket begränsar vem som kan dra nytta av dessa verktyg.
Låt AI läsa betydelsen, inte bara koden
GRASP-ansatsen utgår från en enkel idé: i stället för att behandla varje medicinsk kod som ett meningslöst id-nummer, låt en stor språkmodell läsa den mänskliga beskrivningen bakom den, till exempel ”akut övre luftvägsinfektion”, och omvandla den betydelsen till en numerisk ”embedding”. Dessa embeddings placerar besläktade begrepp nära varandra i ett gemensamt rum, även om de kommer från olika kodsystem eller länder. GRASP förberäknar sådana embeddings för miljontals standardiserade medicinska termer och lagrar dem i en uppslags-tabell. En patients medicinska historia representeras därefter som en serie av dessa rika vektorer, som skickas in i ett transformer-nätverk — en typ av neuralt nätverk som lämpar sig väl för att hantera samlingar av olika indata — för att uppskatta personens risk för 21 stora sjukdomar plus den övergripande risken för död.
Testning över länder och journalsystem
Forskarlaget tränade GRASP med data från nästan 400 000 deltagare i UK Biobank och testade det sedan utan omträning i två mycket olika miljöer: FinnGen-projektet i Finland och ett stort sjukhusnätverk i New York City. GRASP matchade eller överträffade starka alternativ, inklusive en populär metod kallad XGBoost och en liknande transformer som inte använde språkbaserade embeddings. I Finland presterade GRASP särskilt väl och visade tydliga förbättringar för tillstånd som astma, kronisk njursjukdom och hjärtsvikt. Anmärkningsvärt nog levererade GRASP bättre prediktioner än enbart demografiska data även när de amerikanska journalsdata lämnades i ett annat kodningsschema i stället för att konverteras till en gemensam standard, eftersom metoden kunde aligna koder enbart genom att förstå ordalydelsen i deras beskrivningar.
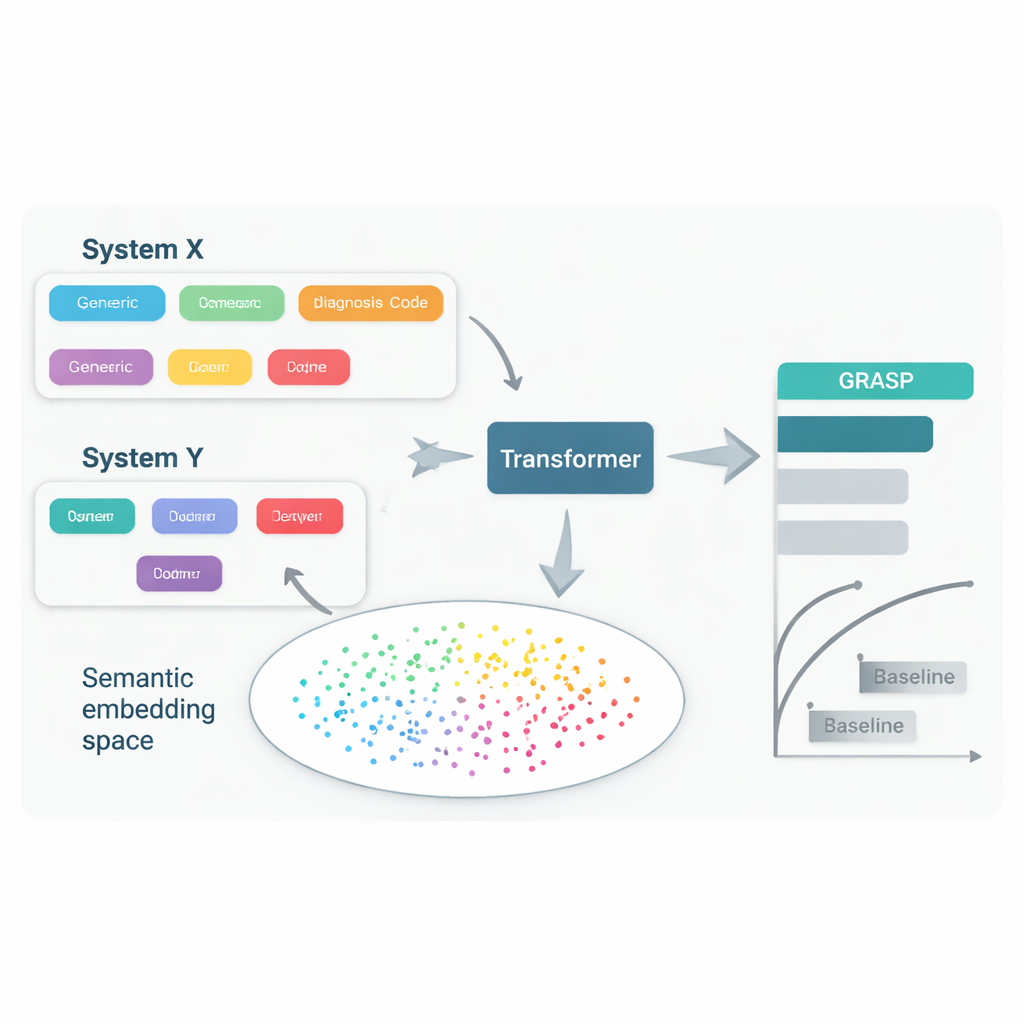
Få mer med mindre data
En annan fördel med GRASP är effektivitet. Eftersom språkmodellen redan lärt sig att många medicinska begrepp är besläktade behöver prediktionsnätverket inte återupptäcka dessa samband från början. När författarna tränade GRASP på mycket mindre delmängder av de brittiska data — ned till bara 10 000 personer — överträffade det fortfarande konkurrerande modeller tränade på samma begränsade prover, både i Storbritannien och vid överföring utomlands. GRASP:s riskpoäng var också mer i linje med människors ärftliga genetiska risk för flera sjukdomar, vilket tyder på att metoden fångar djupare aspekter av sjukdomssusceptibilitet snarare än att bara memorera mönster i en enda dataset.
Vad detta betyder för framtidens vård
För icke-specialister är huvudbudskapet att GRASP visar hur modern språkbaserad AI kan hjälpa olika vårdsystem att ”tala samma språk” utan att tvinga dem in i ett enda stelt kodningsschema. Genom att läsa betydelsen av medicinska termer kan GRASP skapa sjukdomsriskprediktioner som generaliserar bättre över länder och journalformat, och göra det med färre patientexempel. Metoden kräver fortfarande noggrann testning, omkalibrering och kontroller för rättvisa innan den kan användas i vardaglig vård, men den pekar mot en framtid där kraftfulla riskverktyg utvecklade på ett ställe säkert och effektivt kan delas med sjukhus och kliniker världen över.
Citering: Kirchler, M., Ferro, M., Lorenzini, V. et al. Large language models improve transferability of electronic health record-based predictions across countries and coding systems. npj Digit. Med. 9, 177 (2026). https://doi.org/10.1038/s41746-026-02363-5
Nyckelord: elektroniska journaler, prediktion av sjukdomsrisk, stora språkmodeller, delning av medicinska data, sjukvårds-AI