Clear Sky Science · sv
Jämförelse av decentraliserad maskininlärning och AI‑kliniska modeller med lokala och centraliserade alternativ: en systematisk översikt
Varför det spelar roll att dela medicinska insikter utan att dela data
Modern medicin förlitar sig i allt högre grad på artificiell intelligens för att upptäcka sjukdom tidigare, välja rätt behandling och förutsäga vilka som har högst risk. De bästa AI‑verktygen kräver dock mycket stora mängder patientdata, och sjukhus kan inte enkelt slå ihop sina register på grund av strikta integritetslagar och etiska hänsyn. Den här artikeln granskar mer än ett decennium av forskning om ”decentraliserad” inlärning—sätt för sjukhus att träna AI tillsammans utan att någonsin dela rå patientdata—och ställer en praktisk fråga: hur väl presterar dessa integritetsbevarande metoder i jämförelse med traditionella angreppssätt?
Nya sätt att lära av patienter samtidigt som integriteten skyddas
I traditionell centraliserad inlärning kopierar sjukhus all sin data till en enda stor databas och tränar en modell där. Vid lokal inlärning bygger varje institution sin egen modell på sina egna data, utan samarbete. Decentraliserad inlärning erbjuder en mellantjänst. I federated learning, till exempel, tränar varje sjukhus en modell lokalt och endast modellens parametrar (som ”vridreglagen” i ett neuralt nätverk) skickas för att kombineras till en gemensam modell; patientjournaler lämnar aldrig platsen. Swarm learning tar bort den centrala koordinatorn och låter institutioner utbyta modelluppdateringar direkt. Andra decentraliserade tillvägagångssätt kombinerar prediktioner från flera lokala modeller eller delar upp modellen över flera platser. Dessa metoder har testats på problem som sträcker sig från cancer‑detektion och COVID‑19‑diagnos till hjärtsjukdom, diabetes, hjärnstörningar och psykiatriska tillstånd.
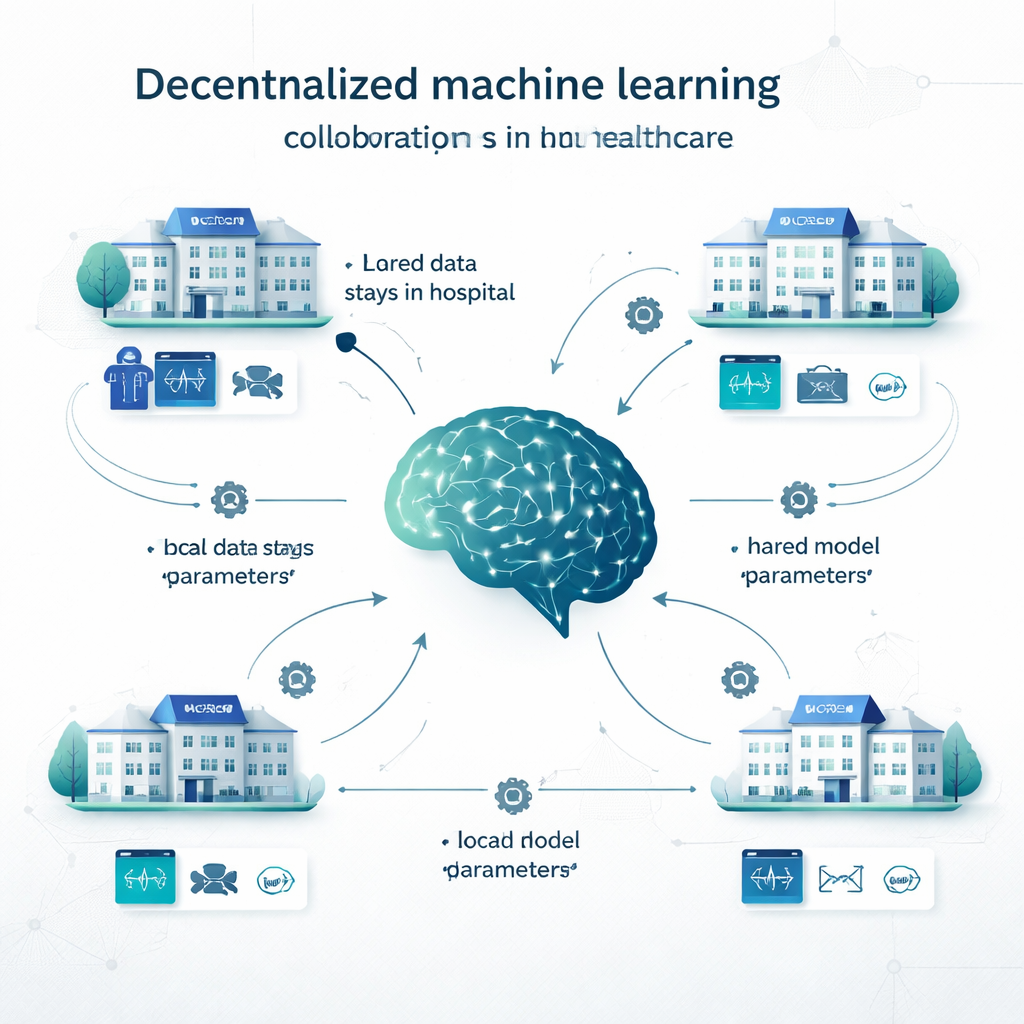
Vad forskarna undersökte
Författarna sökte systematiskt i 11 stora databaser och granskade 165 010 studier publicerade mellan 2012 och mars 2024. Efter att dubbletter och studier som inte involverade verkliga kliniska beslut tagits bort återstod 160 artiklar. Tillsammans rapporterade dessa artiklar 710 decentraliserade modeller och 8 149 direkta prestandajämförelser mot centraliserade eller lokala modeller. De flesta studier fokuserade på diagnostik, men det fanns också många om bildsegmentering (till exempel att avgränsa tumörer), förutsägelse av framtida utfall som överlevnad eller komplikationer, och kombinerade uppgifter. Datatyperna täckte nästan alla större källor som används i medicin: elektroniska journaler, CT‑ och MR‑bilder, röntgenbilder, digitala patologiska bilder, hjärt‑ och hjärnsignaler och till och med genetiska data.
Hur integritetsbevarande modeller står sig mot centraliserad AI
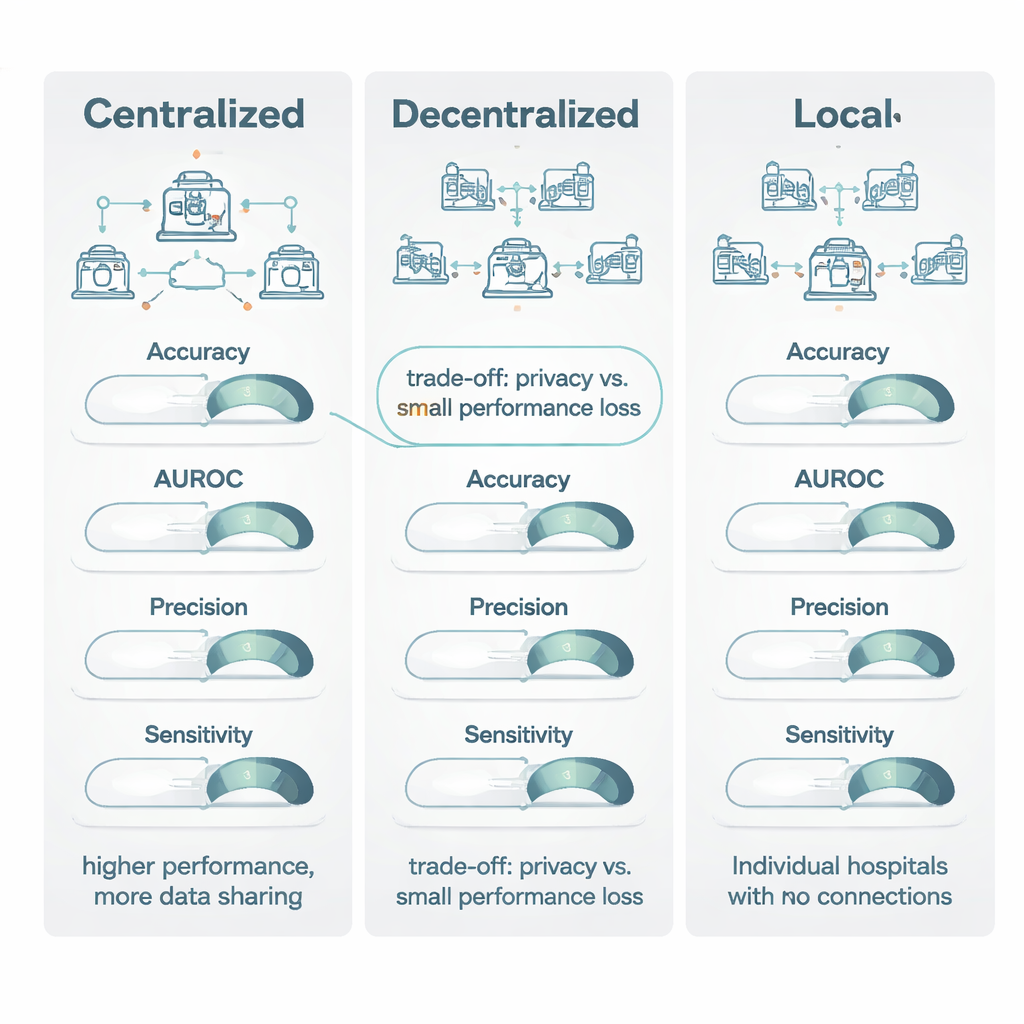
När decentraliserade modeller jämfördes med centraliserade modeller som tränats på samlad data låg centraliserad inlärning vanligtvis något före. Den presterade särskilt bra på ”tröskelbaserade” mått som noggrannhet och en vanlig bildpoäng kallad Dice‑koefficienten, och vann ungefär tre fjärdedelar av gångerna med en fördel som bedömdes som måttlig till stor. För ranking‑liknande mått—såsom area under ROC‑kurvan (AUROC), som fångar hur väl en modell rangordnar patienter från lägre till högre risk—var decentraliserade och centraliserade modeller däremot mycket närmare varandra, med endast en liten fördel för central träning. Viktigt är att när båda modellerna nådde det författarna kallar ”kliniskt gångbar” prestanda (en poäng på minst 0,80) var centralmodellens typiska vinst blygsam: ofta mindre än 1–1,5 procentenheter. I många situationer innebar detta ”utmärkt kontra acceptabelt”, inte ”användbart kontra värdelöst”.
Varför decentraliserad inlärning slår att stå ensam
Den starkaste signalen i översikten framkom vid jämförelser mellan decentraliserade modeller och rent lokala sådana. Över alla större mått—noggrannhet, AUROC, F1‑poäng, sensitivitet, specificitet och särskilt precision—presterade decentraliserade metoder nästan alltid bättre, ofta med stor marginal. I head‑to‑head‑tester överträffade decentraliserad inlärning lokala modeller i mer än 80 % av jämförelserna för nyckelmått som noggrannhet, precision och AUROC. I många fall nådde lokala modeller inte tröskeln 0,80 för klinisk användbarhet, medan motsvarande decentraliserade modell klarade den med god marginal och förbättrade känsligheten med upp till 27 procentenheter. Författarna tillskriver detta den bredare erfarenheten flersajtsmodeller får: genom att ”se” mönster från många sjukhus blir de mindre vilseledda av sjukhusspecifika särdrag i scannrar eller journalföring och mer inriktade på sjukdomsdrag som verkligen generaliserar.
Att balansera prestanda, integritet och praktisk användning
Översikten slutar i att centraliserad inlärning förblir guldstandarden när sekretessregler och logistik tillåter att data kombineras och när varje tiondels procentpoäng i prestanda är avgörande, som vid mycket sällsynta sjukdomar. Decentraliserad inlärning erbjuder dock ett kraftfullt och kliniskt acceptabelt alternativ i situationer där datadelning begränsas av lagar som GDPR och EU:s AI‑lag eller av institutionella riktlinjer. Jämfört med att hålla modeller helt lokala ger decentraliserade angreppssätt stora vinster i både noggrannhet och tillförlitlighet samtidigt som data stannar inom sjukhusets väggar. Författarna argumenterar för att framtida studier bör rapportera sekretessmetoder och beräkningskostnader tydligare, så att vårdsystem kan göra välgrundade val om när små prestandatrade‑offs är värda de betydande fördelarna i integritet och samarbete.
Citering: Diniz, J.M., Vasconcelos, H., Rb-Silva, R. et al. Comparing decentralized machine learning and AI clinical models to local and centralized alternatives: a systematic review. npj Digit. Med. 9, 174 (2026). https://doi.org/10.1038/s41746-025-02329-z
Nyckelord: federated learning, hälso‑AI, sekretess för medicinska data, decentraliserad maskininlärning, kliniska prediktionsmodeller