Clear Sky Science · sv
Generaliserbar automatiserad tumörsegmentering i histopatologiska helbildsbilder över flera cancertyper
Varför detta spelar roll för cancervården
Cancerdiagnos bygger fortfarande på att experter noggrant granskar glaspreparat med färgat vävnad i mikroskop — en tidskrävande uppgift som försvåras av ökande patientantal och brist på patologer. Denna studie ställer en enkel men kraftfull fråga: kan ett enda artificiellt intelligenssystem pålitligt hitta cancerområden i digitala mikroskopbilder för många olika tumörtyper, istället för att bygga ett separat verktyg för varje cancerform? Om svaret är ja kan det lätta arbetsbördan, snabba upp diagnostiken och göra avancerad analys tillgänglig även för ovanligare cancerformer där data är knappa.
Från glaspreparat till digitala hjälpmedel
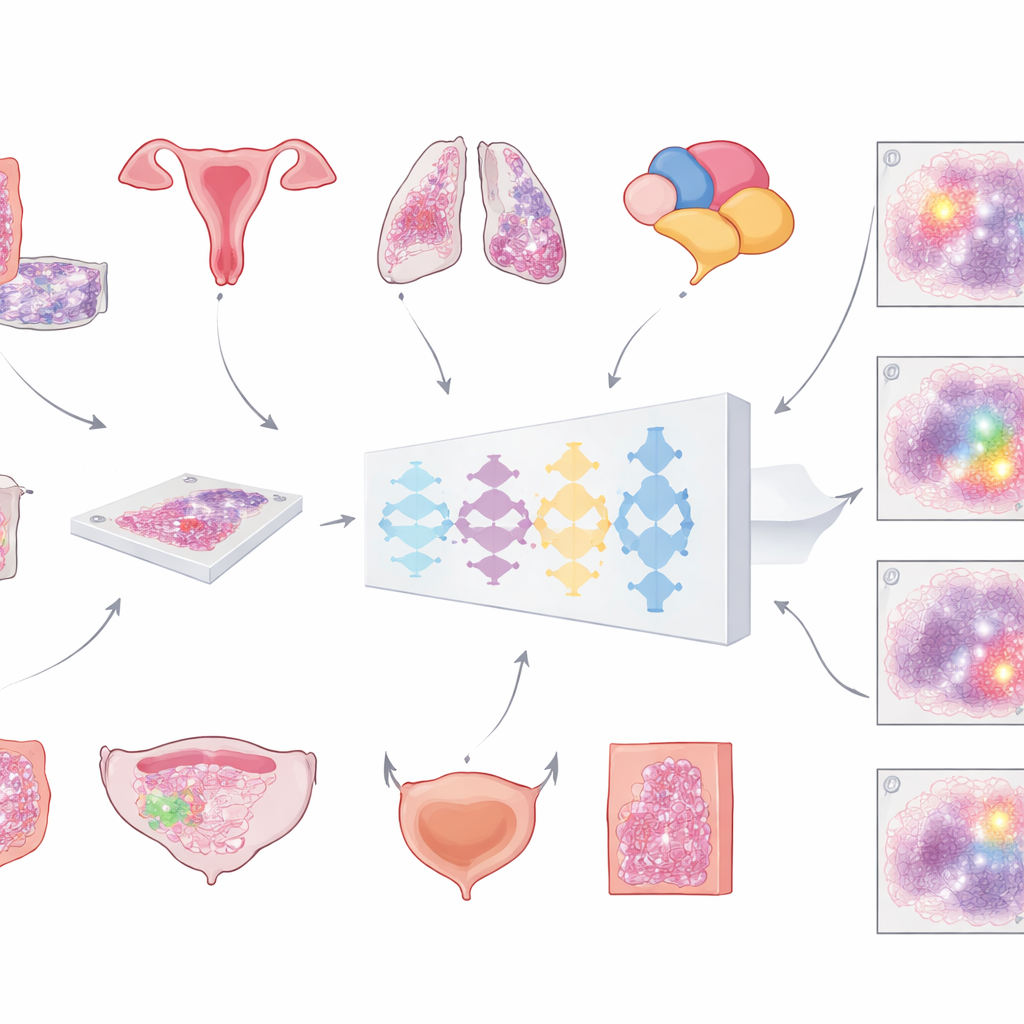
Moderna sjukhus scannar i allt större utsträckning mikroskoppreparat för att skapa enormt detaljerade ”helbildsbilder” av tumörer. Det första avgörande steget för all datorbaserad analys är att skilja cancerös vävnad från allt annat — normala celler, fett, tomt glas och artefakter. Hittills har de flesta automatiserade verktyg tränats på bara en cancertyp, vilket begränsar var de kan användas. Forskarteamet bakom detta arbete ville bygga en enda, universell modell som kunde upptäcka tumörområden över flera vanliga cancerformer i preparat färgade med rutinmässiga hematoxylin‑ och eosinfärgningar. Deras vision var ett generellt verktyg som kunde kopplas in i många diagnostiska arbetsflöden utan att behöva designas om för varje fall.
Träna en modell att känna igen många cancerformer
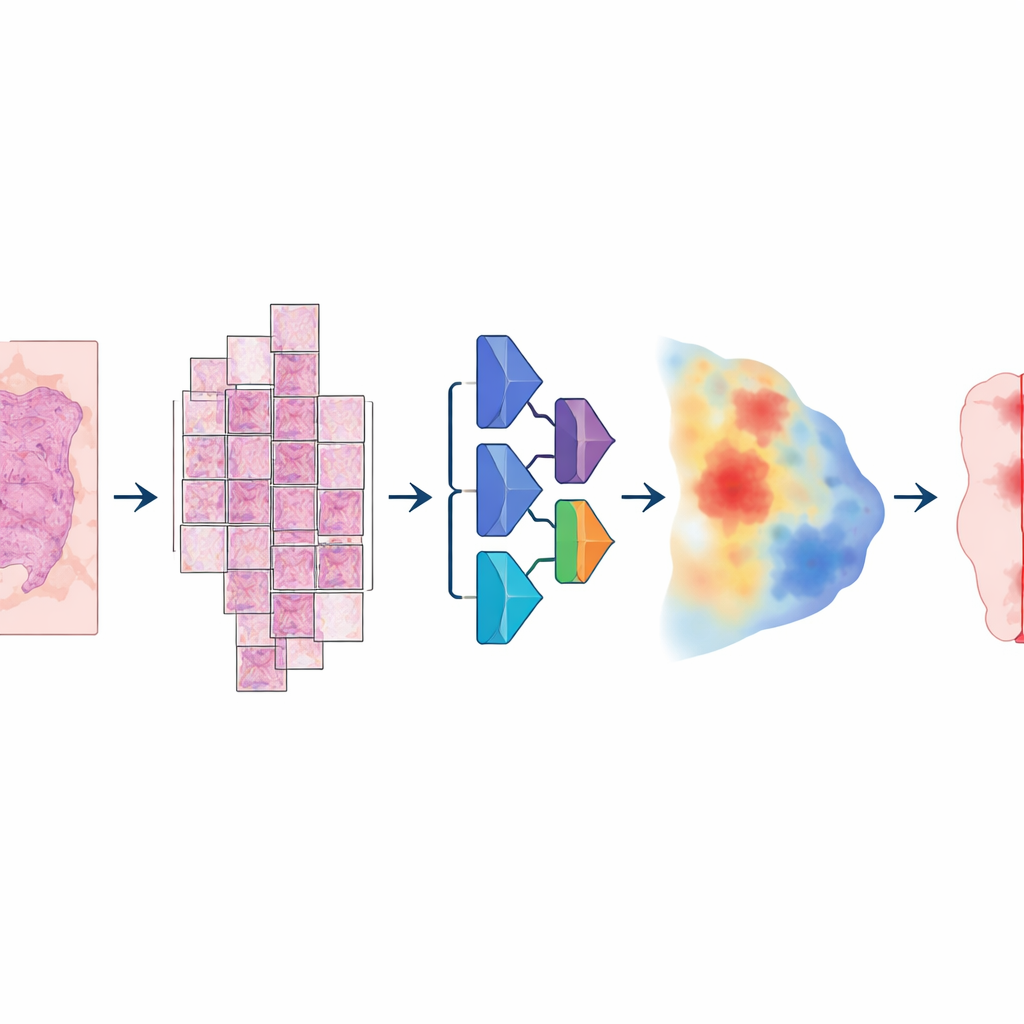
För att bygga modellen samlade forskarna en ovanligt stor och varierad samling digitala bilder: mer än 20 000 helbildsbilder från över 4 000 patienter med kolorektal, endometrie-, lung‑ och prostatacancer. Alla prov var från standardiserad formalinfixerad, paraffininkapslad vävnad och hade skannats på två olika högupplösta skannrar. En patolog ritade noggrant ut tumörområden på varje bild och gav därmed den ”sanningsreferens” som datorn skulle lära sig från. Modellen följde en flerstegs‑pipeline: varje enorm bild delades i stora överlappande kakel, passerades genom ett djupt neuralt nätverk som för varje pixel uppskattade sannolikheten för tumör, och sattes därefter ihop till en jämn karta som slutligen omvandlades till en ren tumör‑mot‑icke‑tumör‑mask.
Sätta systemet på prov
Viktigt är att teamet inte nöjde sig med träningens resultat. De testade samma modell på mer än 3 000 ytterligare patienter över sex cancertyper — inklusive bröst‑ och blåscancer som aldrig användes i träningen — och på preparat från flera sjukhus och skannrar. Noggrannheten mättes huvudsakligen med en standardiserad överlappsstatistik (Dice‑koefficienten), som når 100 % när datorns tumörkontur exakt matchar patologens. För stora, intakta tumörprover vid kolorektal-, endometrie-, lung-, prostata‑ och bröstcancer översteg den genomsnittliga överlappningen 80 % och var ofta över 90 %. I stora externa samlingar från The Cancer Genome Atlas, som kommer från många laboratorier och skannrar världen över, höll sig prestationen återigen över 80 %, vilket tyder på att modellen generaliserar väl bortom sin ursprungsinstitution.
Var den har svårigheter och hur den står sig i jämförelse
Huvudsvagheten framkom vid tidiga blåscancerfall som provtagits med en procedur som ger mycket små, fragmenterade vävnadsbitar. I dessa fall misslyckades modellen ofta med att markera någon tumör alls, särskilt när cancerområdet var mycket litet. När den väl upptäckte tumör var överlappningen med patologens konturer dock hög, och enkla justeringar av slutgiltiga tröskelvärden förbättrade resultaten — vilket antyder att det underliggande nätverket kände igen mönstret men att efterbearbetningen var för strikt. Forskarna byggde också fyra ”specialist”modeller, var och en tränad på en enskild cancertyp, och fann att ingen av dem gav en meningsfull förbättring i sin egen domän jämfört med den generella modellen. Däremot misslyckades dessa specialistsystem i stor utsträckning när de tillämpades på andra cancertyper, medan den generella modellen förblev robust. Jämfört med ett populärt, mer generiskt medicinskt segmenteringsverktyg som kräver användarinmatning presterade den nya modellen vanligen lika bra eller bättre samtidigt som den förblev helt automatisk.
Vad detta betyder för patienter och läkare
För icke‑experter är huvudbudskapet att ett välutformat AI‑system pålitligt kan markera cancerös vävnad på digitala preparat över flera stora tumörtyper, utan att behöva skräddarsydda versioner för varje sjukdom eller skanner. Det ersätter inte patologen, men det kan förprogrammera sannolika tumörområden, stödja konsekventa mätningar och frigöra specialister så att de kan fokusera på de svåraste fallen. Den nuvarande versionen missar fortfarande en del mycket små eller tidigt upptäckta tumörer — särskilt fragmenterade blåscancerprover och sannolikt andra biopsiliknande vävnader — så den är ännu inte lämpad för att hitta de svagaste spåren av cancer. Ändå visar studien att bred, ”pan‑cancer” tumörsegmentering är möjlig under verkliga förhållanden och kan utgöra ett robust första steg för framtida automatiserade verktyg som bedömer tumörgrad, förutser behandlingssvar eller vägleder precisionsbehandlingar.
Citering: Skrede, OJ., Pradhan, M., Isaksen, M.X. et al. Generalisation of automatic tumour segmentation in histopathological whole-slide images across multiple cancer types. npj Precis. Onc. 10, 107 (2026). https://doi.org/10.1038/s41698-026-01311-6
Nyckelord: digital patologi, djupinlärning, tumörsegmentering, helbildsavbildning, pan-cancer-modell