Clear Sky Science · sv
IMFLKD: en incitamentsmekanism för decentraliserad federated learning baserad på knowledge distillation
Varför delning kan vara säker och rättvis
Modern artificiell intelligens lever på data, men det mesta av vår data ligger på personliga telefoner, sjukhusservrar eller företagsmoln som inte enkelt kan kopieras och delas. Federated learning erbjuder ett sätt för många enheter att träna en gemensam modell utan att exponera sina rådata, men dagens system kämpar fortfarande med sekretessläckor, centrala felpunkter och orättvisa belöningar för dem som bidrar mest. Denna artikel presenterar ett nytt ramverk, IMFLKD, som kombinerar tre kraftfulla idéer — blockkedja, knowledge distillation och renommepoäng — för att göra denna typ av kollektivt lärande mer privat, mer robust och mer rättvis på lång sikt.
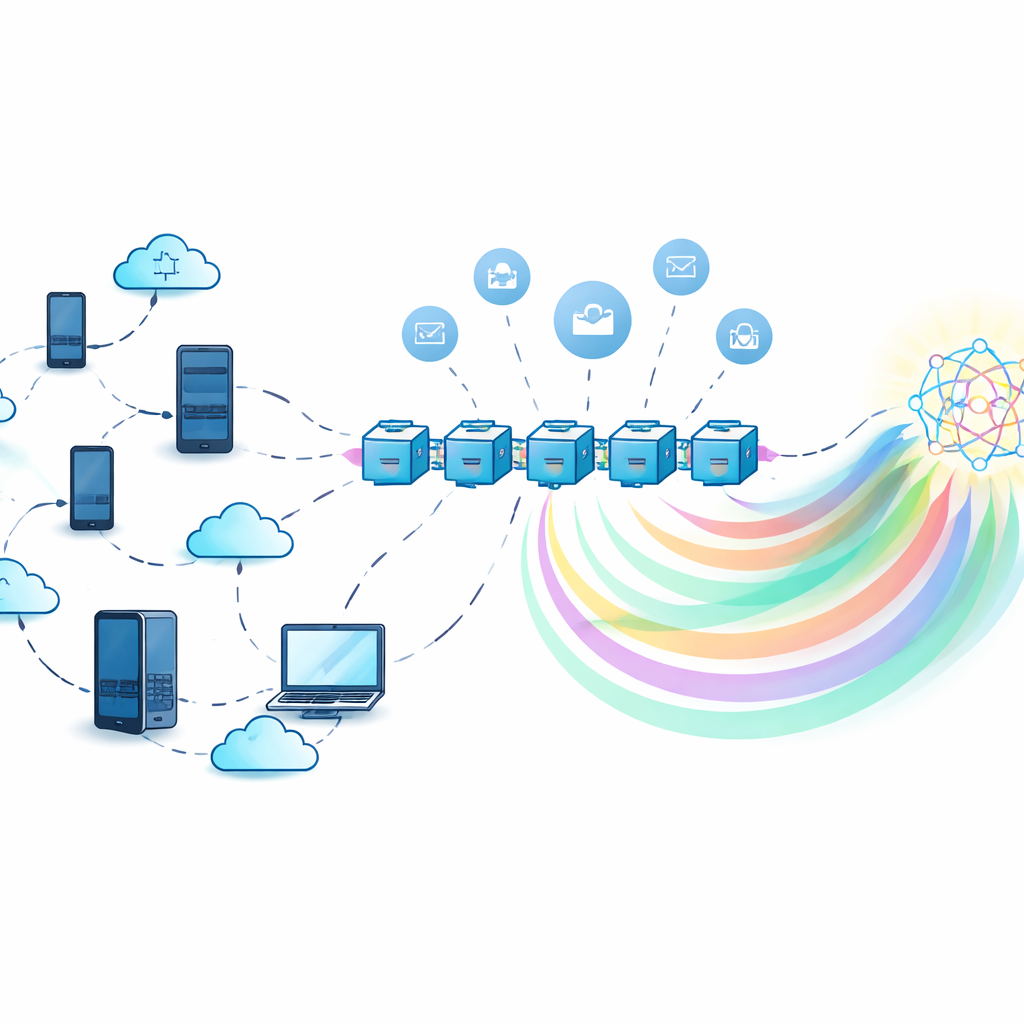
Träna tillsammans utan att dela hemligheter
I klassisk federated learning samlar en central server in modelluppdateringar från många deltagare och kombinerar dem. Detta förhindrar att rådata flyttas, men servern blir samtidigt ett attraktivt mål: om den fallerar stannar hela systemet, och om den är opålitlig kan den missbruka eller läcka information som döljs i modelluppdateringarna. Författarna använder istället en decentraliserad blockkedjelogg för att samordna träningen. Varje deltagare tränar en lokal modell på sina egna data och interagerar sedan med smarta kontrakt på blockkedjan som registrerar bidrag, aggregerar information och fördelar belöningar — allt utan att förlita sig på en enda central myndighet.
Dela kunskap, inte tunga modeller
För att minska kommunikationskostnader och ytterligare skydda integriteten förlitar sig ramverket på knowledge distillation. Istället för att skicka hela modellparametrar skickar varje deltagare endast "soft labels" — modellens predicerade sannolikheter för en uppsättning delade indata — vilka är mycket lättare och avslöjar mindre om enskilda personers data. Eftersom en verklig delad dataset kanske inte finns, använder systemet en generativ modell kallad konditionell variational autoencoder för att skapa en syntetisk "pseudo-offentlig" dataset som ungefär matchar den övergripande etikettfördelningen utan att exponera några ursprungliga poster. Deltagarna tränar på sina egna data, gör förutsägelser på denna syntetiska dataset och förfinar sedan sina modeller med hjälp av en aggregerad signal härledd från allas samlade kunskap.
Mäta vem som verkligen hjälper
En central utmaning i alla samarbetsbaserade system är att avgöra vem som förtjänar kredit. IMFLKD hanterar detta med en tvåstegsmetod för utvärdering av bidrag baserad på etikettaggregation. Först granskar en lättviktsbayesiansk algoritm prediktionerna från alla deltagare och härleder både den mest sannolika sanna etiketten för varje prov och en kvalitetspoäng för varje modell, och uppdaterar dessa poäng när fler uppgifter kommer in. Detta tillvägagångssätt fungerar online, utan att lagra tidigare data, och hanterar brusiga eller illvilliga bidragsgivare genom att nedviktsera modeller som ofta avviker från den framväxande konsensusen. Experiment visar att denna etikettaggregation förbättrar noggrannheten med ungefär 10 procent jämfört med enkel majoritetsomröstning, samtidigt som den förblir tillräckligt snabb för storskaliga, resursbegränsade miljöer.
Göra kvalitet till belöningar och renommé
När bidragskvaliteten är känd använder IMFLKD ett incitamentsschema kallat weighted peer truth serum för att omvandla den till belöningar. Deltagare jämförs mot en kvalitetsviktad peer-konsensus: de vars prediktioner stämmer överens med högkvalitativa peers tjänar mer, medan de som avviker eller ofta är oense blir bestraffade. Detta gör ärlig rapportering till den mest lönsamma långsiktiga strategin, även i närvaro av kollusion. Ovanpå detta bygger systemet en flerdimensionell renommépoäng för varje deltagare, som kombinerar datakvalitet, aktivitetsnivå och beteendestabilitet, och justerar äldre beteenden med en tidsnedbrytningsfaktor. Renomméen påverkar sedan senare rundor genom att bestämma hur mycket vikt en deltagares prediktioner får och huruvida de väljs för framtida uppgifter.
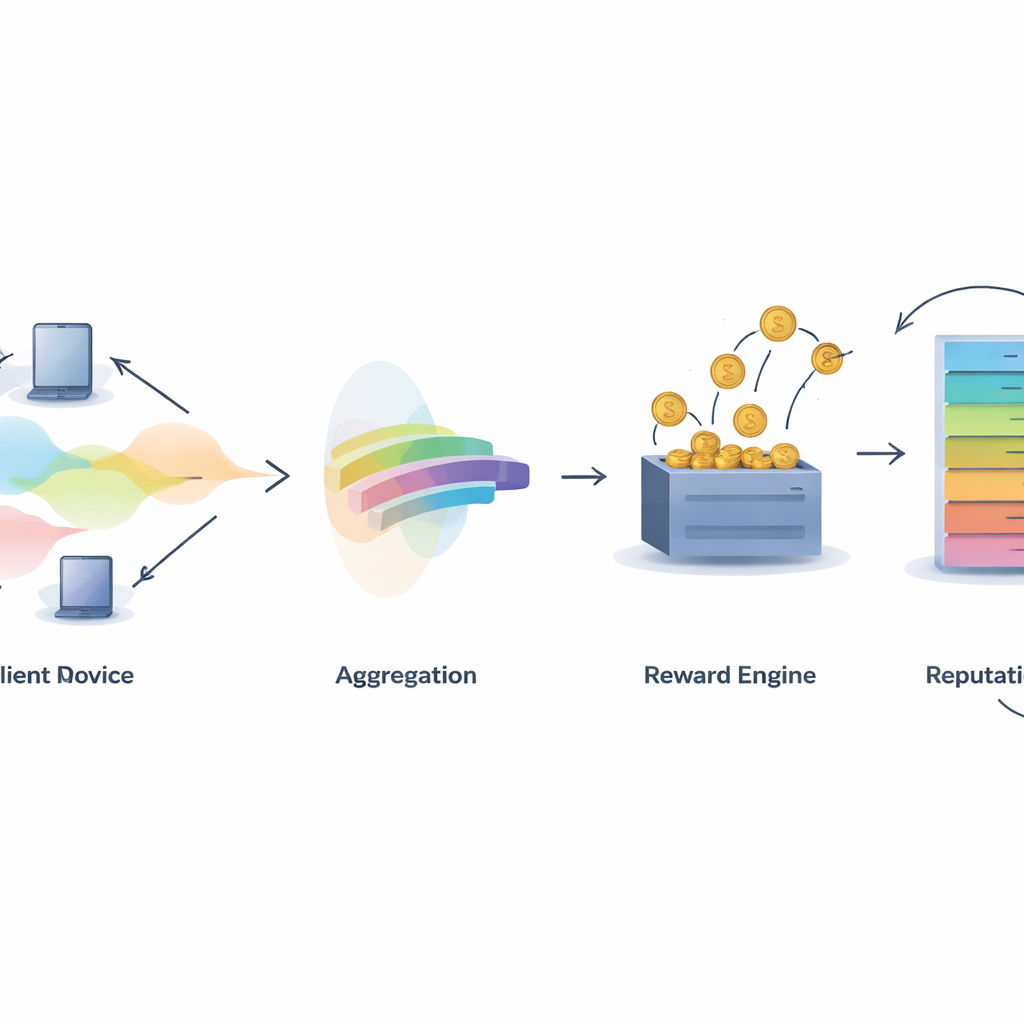
Bygga förtroende i kollektiv intelligens
Sammanfattningsvis visar IMFLKD-ramverket att det är möjligt att samordna lärande över många oberoende enheter på ett sätt som är effektivt, integritetsmedvetet och motståndskraftigt mot fripassare och angripare. Genom att blanda syntetisk datagenerering, rigorös bidragsskattning, spelteoretiska belöningsmekanismer och dynamisk renomméspårning på en blockkedja uppmuntrar systemet deltagare att agera ärligt och konsekvent över många träningsomgångar. För en lekman är budskapet att vi kan utnyttja den kollektiva kraften i distribuerade data — såsom medicinska journaler, sensordata eller personliga enheter — utan att överlämna allt till ett enda företag eller en server, samtidigt som de som bidrar med mest användbar information också är de som får mest nytta.
Citering: Ying, X., Yan, K., Gao, X. et al. IMFLKD: an incentive mechanism for decentralized federated learning based on knowledge distillation. Sci Rep 16, 10567 (2026). https://doi.org/10.1038/s41598-026-46234-1
Nyckelord: federated learning, blockkedja, knowledge distillation, incitamentsmekanismer, renomésystem