Clear Sky Science · sv
PlantCLR: kontrastiv självövervakad förträningsmetod för generaliserbar upptäckt av växtsjukdomar
Varför smartare upptäckt av växtsjukdomar spelar roll
Växtsjukdomar stjäl tyst mat från världens bord genom att minska skördar och minska bönders inkomster. I många områden finns bara ett fåtal utbildade experter som kan identifiera problem ute på fälten, och att få deras hjälp kan vara långsamt eller omöjligt. Denna studie presenterar PlantCLR, ett datorbaserat system som lär sig känna igen sjukdomar från bilder på blad med avsevärt färre mänskligt märkta exempel än vanligt. Genom att göra automatisk diagnostik mer exakt, mer pålitlig och lättare att köra på enkel hårdvara pekar arbetet mot mobiltelefoner eller lågkostnadskameror som kan hjälpa bönder upptäcka problem tidigt och skydda sina skördar.
Från bladbilder till tidiga varningar
Idag diagnostiseras många växtsjukdomar på det gamla viset: en person tittar på ett blad och avgör om fläckar, gulfärgning eller veckning är tecken på infektion. Den bedömningen kan variera mellan experter och påverkas lätt av skuggor, röriga bakgrunder eller olika tillväxtstadier. Datorsynssystem baserade på djupinlärning har börjat hjälpa till, men de kräver vanligtvis många tusentals noggrant märkta bilder. Inom jordbruket är sådana märkta bilder sällsynta och kostsamma att samla in, medan stora mängder omärkta bilder från mobiltelefoner och fältkameror ofta förblir oanvända. PlantCLR är utformat för att utnyttja dessa omärkta data och lär sig hur sjuka respektive friska blad vanligtvis ser ut innan det någonsin ser en etikett.
Att lära en modell genom jämförelse
PlantCLR bygger på en nyare metod som kallas kontrastiv självövervakad inlärning, där en modell lär sig genom att jämföra bilder snarare än att läsa etiketter. Först tar systemet en omärkt bild på ett blad och skapar två något olika versioner genom slumpmässiga beskärningar, speglingar, färgförskjutningar eller suddning. Dessa två versioner ska tydligt representera samma blad, så modellen tränas att betrakta dem som ett matchande par och ge dem liknande interna representationer, samtidigt som representationerna för olika blad i samma träningsbatch dras isär. Denna förträningsfas använder en kompakt men modern bildbehandlingsbackbone kallad ConvNeXt-Tiny, ihop med en liten extramodul som endast används under inlärnings-genom-jämförelse-steget. 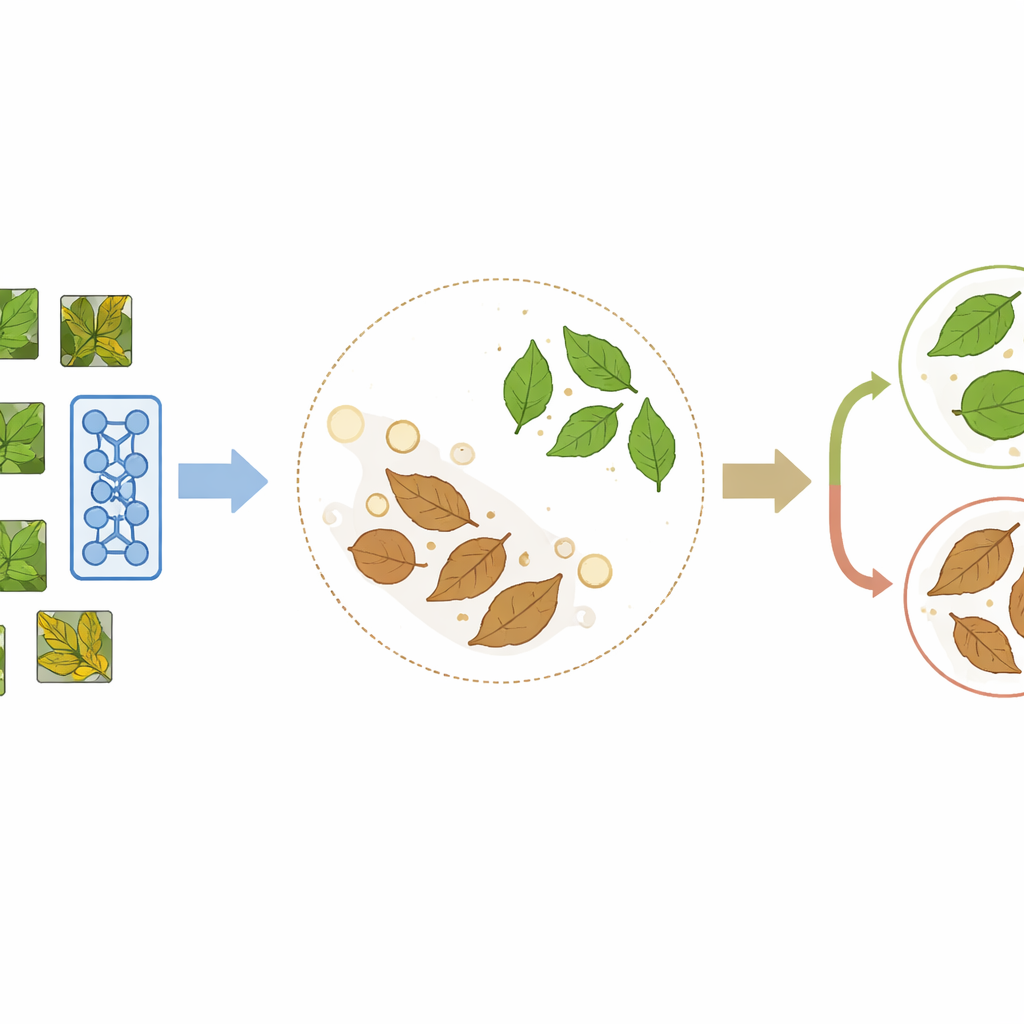
Att testa systemet
För att testa hur väl denna strategi fungerar i praktiken vände sig författarna till två populära blad-dataset som efterliknar mycket olika verkliga miljöer. PlantVillage-datasettet innehåller mer än 54 000 bilder på blad fotograferade under ordnade, kontrollerade förhållanden, vanligtvis med rena bakgrunder och tydliga symptom över 38 sjukdoms- och grödekategorier. I kontrast innehåller Cassava Leaf Disease-datasettet ungefär 21 000 bilder av kassavablad tagna direkt i fält, med röriga bakgrunder, ojämnt ljus och blad som överlappar eller vrider sig i många riktningar över fem klasser, inklusive flera allvarliga virus- och bakterieinfektioner. Studien använder PlantVillage främst som en rik källa av omärkta bilder för förträning och utvärderar sedan prestanda både på det datasetet och, ännu viktigare, på de svårare fältliknande kassavabilderna.
Robust prestanda över skiftande förhållanden
PlantCLR nådde 99,10 % noggrannhet på PlantVillage-testuppsättningen och 96,83 % noggrannhet på Cassava-testuppsättningen, med liknande höga F1-poäng som visar att modellen presterar väl även på mindre vanliga sjukdomar. Dessa siffror slår flera välkända djupa nätverk, inklusive DenseNet, ResNet, VGG och en vision transformer-modell, alla tränade i ett rent övervakat upplägg under noggrant matchade förhållanden. 
Varför detta tillvägagångssätt är ett steg framåt
För icke-specialister är huvudbudskapet att PlantCLR visar hur en maskin kan bli en kapabel växtläkare genom att först lära sig från stora samlingar av omärkta bilder och sedan finslipa sina färdigheter med en mindre, märkt uppsättning. Denna strategi når inte bara mycket hög noggrannhet utan håller sig också väl när kameran flyttas från labbet till fältet, där förhållandena är långt ifrån ordnade. Eftersom den underliggande modellen är relativt lättviktig kan den så småningom distribueras på prisvärd hårdvara, vilket gör avancerad sjukdomsdetektion mer tillgänglig för bönder och rådgivare världen över. Sammanfattningsvis visar studien en praktisk väg mot skalbara, robusta och etiketteffektiva verktyg för övervakning av växthälsa som kan hjälpa till att skydda livsmedelsförsörjningen.
Citering: Shah, S.S.A., Saeed, F., Raza, M.U. et al. PlantCLR: contrastive self-supervised pretraining for generalizable plant disease detection. Sci Rep 16, 10550 (2026). https://doi.org/10.1038/s41598-026-45684-x
Nyckelord: upptäckt av växtsjukdomar, självövervakad inlärning, kontrastiv inlärning, jordbruks-AI, övervakning av grödors hälsa