Clear Sky Science · sv
Hybrid evolutionär‑gradiant‑träning förbättrar långsiktig tidsserieförutsägelse
Varför bättre långsiktiga prognoser spelar roll
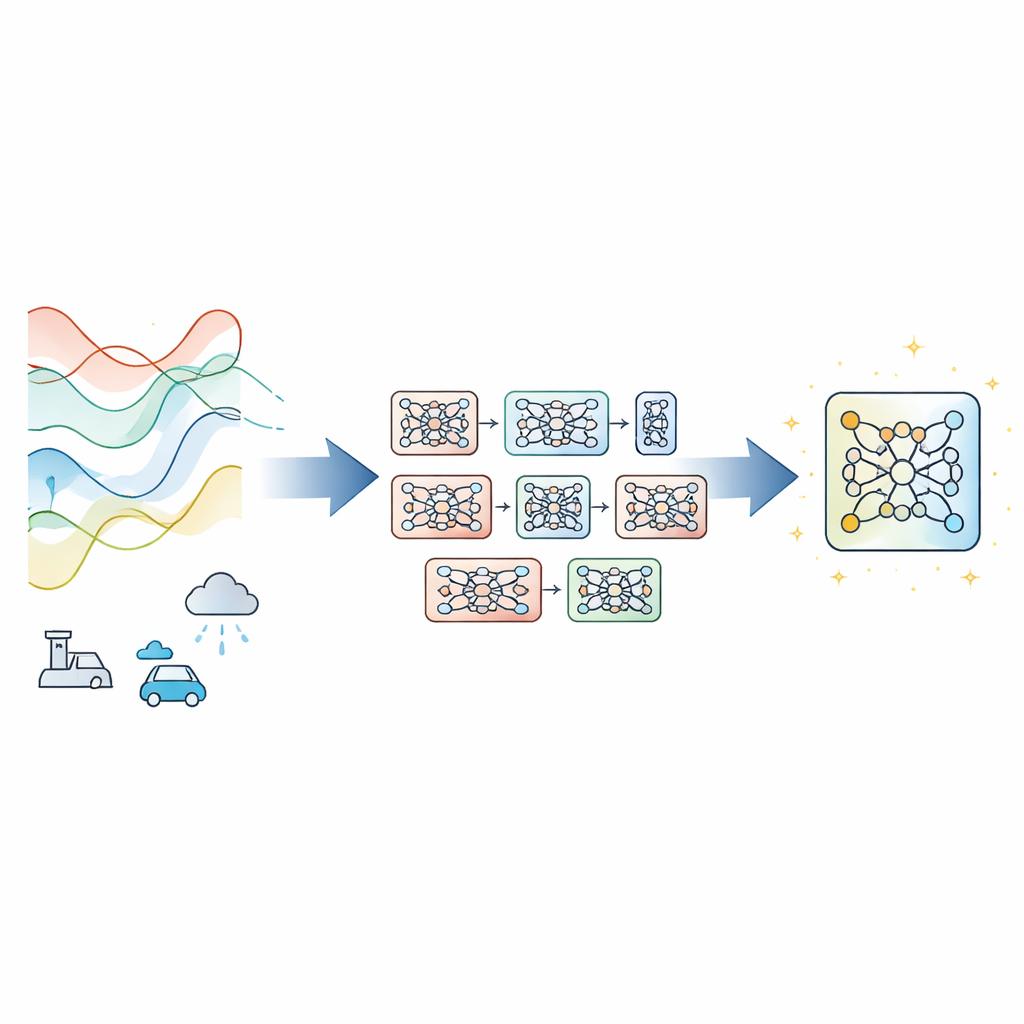
Från elförbrukning och motorvägstrafik till växelkurser och lokalt väder formas våra liv av system som utvecklas över tid. Att kunna förutse dessa mönster dagar eller veckor i förväg kan spara energi, minska trängsel och öka företags motståndskraft. Men ju längre fram vi tittar, desto svårare blir det för dagens artificiella intelligensverktyg att hantera skiftande förhållanden, brusiga mätningar och begränsade beräkningsresurser. Denna artikel presenterar ett nytt sätt att träna prognosmodeller så att de förblir noggranna och stabila även när omvärlden inte står still.
Lära från många modeller istället för bara en
De flesta moderna tidsserieförutsägare bygger på ett enda djupt neuralt nätverk tränat med gradientnedstigning, den vanliga metoden som stegvis justerar modellens parametrar för att minska fel. Det fungerar bra när data beter sig konsekvent, men kan misslyckas när förutsättningarna glider, mätningar är brusiga eller träningstiden är knapp. Istället för att uppfinna en ny nätverksarkitektur föreslår författarna Evolutionary‑Guided Module Fusion with Gradient Refinement (EGMF‑GR), ett träningsramverk som kan omsluta befintliga arkitekturer. Nyckelidén är att upprätthålla en liten ”population” av modeller som delar samma struktur men startar från olika slumpmässiga inställningar. Under träningen utforskar dessa modeller olika sätt att anpassa sig till data, och den för tillfället bäst presterande används för att vägleda förbättringar i de övriga.
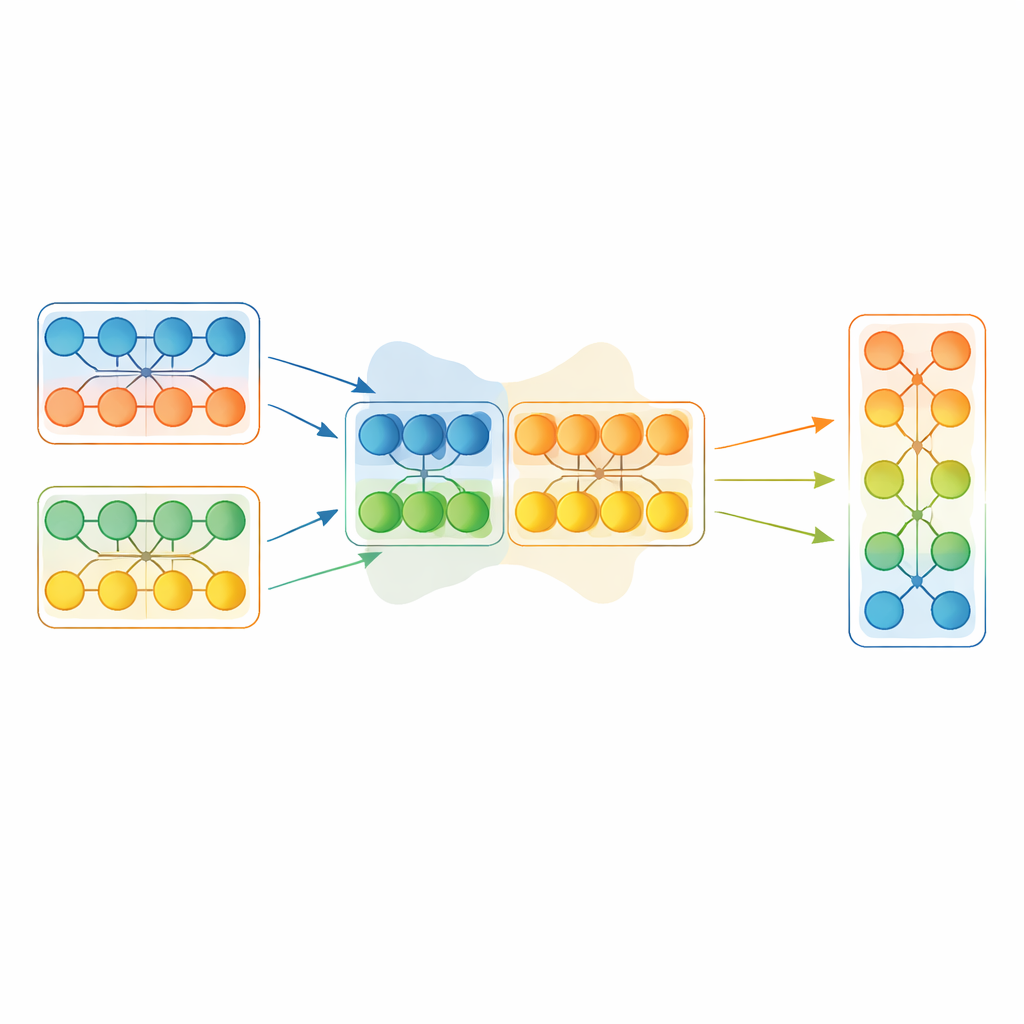
Låna goda delar samtidigt som användbar mångfald bevaras
I stället för att kopiera en hel vinnarmodell rakt av arbetar EGMF‑GR på modulnivå—upprepade byggstenar i ett nätverk, såsom staplar av lager. För varje modell i populationen anpassar ramverket motsvarande moduler till de i den nuvarande bästa modellen och jämför deras interna signaler när de bearbetar samma ingångsbatch. Det använder flera enkla mått på skillnad som fångar både hur aktivitetsmönstren formas och hur stora de är. Dessa modulvisa avvikelser summeras sedan, och endast moduler vars beteende framstår som starka avvikare i förhållande till sina kamrater övervägs för uppdatering. När det sker skjuts den eftersläpande modulen mot motsvarande modul i bästamodellen via en viktad blandning av deras parametrar, plus en liten slumpmässig skakning för att bevara mångfald.
Låta gradienter städa upp efter de stora dragen
Att blanda delar från olika nätverk kan införa plötsliga förändringar. För att undvika att göra träningen instabil genomgår varje fusionerad modell därefter en kort, konventionell gradientnedstigningsfas på träningsdata. Detta förfiningssteg låter nätverket återanpassa sig smidigt till sin nya interna konfiguration samtidigt som fördelarna med det inlånade kunnandet bevaras. Den övergripande proceduren alternerar: välj den nuvarande bästamodellen baserat på ett avskilt datastycke, fusa selektivt moduler från den ledaren in i resten av populationen och finjustera kortvarigt alla med gradienter. Viktigt är också att metoden synkroniserar interna bokföringstillstånd, såsom rullande medelvärden som används av vissa lager, vilka ofta ignoreras i enklare modellslagningsmetoder men kan påverka stabiliteten kraftigt.
Bevisa vinsterna över många verkliga signaler
För att testa ramverket tillämpade författarna EGMF‑GR på flera populära prognosryggrader, inklusive Transformer‑liknande modeller och en ny konvolutionsbaserad design, utan att ändra deras kärnstrukturer. De utvärderade prestanda på åtta publika benchmarkuppsättningar som spände över energianvändning, trafikflöden, växelkurser och väder, och på flera prognosintervall från några timmar till flera dagar framåt. Under en strikt matchad budget för kostsamma bakåtriktade uppdateringar minskade den hybrida träningen konsekvent prediktionsfel och jämnade ut träningsbeteendet för de flesta modell–datakombinationer, särskilt i högdimensionella eller brusiga miljöer. Teamet jämförde också sin metod med vanliga enkla tricks för enstaka modeller som exponentiella glidande medelvärden och stokastisk viktavstämning, och fann att populationsbaserad modulfusion gav ytterligare fördelar utöver enkel viktutjämning.
Förbli pålitlig när förhållandena försämras
Verkliga system beter sig sällan som rena läroboksexempel, så författarna testade också robustheten under tuffare scenarier: konstgjort korrupta ingångar, saknade dataavsnitt och perioder där de underliggande dynamikerna förändras abrupt. EGMF‑GR hjälpte tydligt när ingångarna var brusiga eller delvis saknade, vilket tyder på att lån av stabilt modulbeteende från den nuvarande bästamodellen kan motverka lokala fel. Vid plötsliga regimeskiften var fördelen mindre, vilket antyder att alltför mycket anpassning ibland kan bromsa omställningen till nya mönster. Detta pekar på framtida förfiningar där fusionens styrka dämpas när miljön blir mycket volatil.
Vad detta betyder för vardagliga prognosverktyg
I enkla ordalag visar studien att träning av många samverkande versioner av samma prognosmodell, och att låta dem bara dela de delar som verkligen framstår som bättre, kan göra långsiktiga prognoser mer exakta och stabila utan att konstruktionen av modellerna ändras. EGMF‑GR fungerar som en disciplinerad lagsport: medlemmar antar då och då varandras starkaste drag, och övar sedan lite själva för att passa det nuvarande spelet. För praktiker erbjuder detta en plug‑in‑träningsstrategi som kan stärka befintliga prognossystem inom finans, energi, transport och klimatapplikationer, särskilt när data är röriga och beräkningsbudgetar är knappa.
Citering: Zhao, L., Chen, Z., Wu, N. et al. Hybrid evolutionary-gradient training improves long-term time series forecasting. Sci Rep 16, 10697 (2026). https://doi.org/10.1038/s41598-026-45017-y
Nyckelord: tidsserieförutsägelse, evolutionär träning, neurala nätverk, modellfusion, förskjutning i fördelning