Clear Sky Science · sv
Datadriven utformning av LNA‑blockerare för effektiv borttagning av föroreningar i Ribo‑Seq‑bibliotek
Varför rensning av sekvenseringsdata spelar roll
Modern biologi bygger ofta på att läsa av miljontals små RNA‑fragment för att förstå hur celler tillverkar proteiner. Men dessa kraftfulla mätningar, särskilt en metod kallad ribosomprofilering (Ribo‑Seq), kan vara fyllda med irrelevanta RNA‑bitar som slösar sekvenseringskapacitet och pengar. Denna studie beskriver ett enkelt, datadrivet sätt att utforma specialiserade molekylära ”blockerare” som selektivt tar bort dessa oönskade fragment, vilket nästan fördubblar den användbara information forskare får från samma experiment.
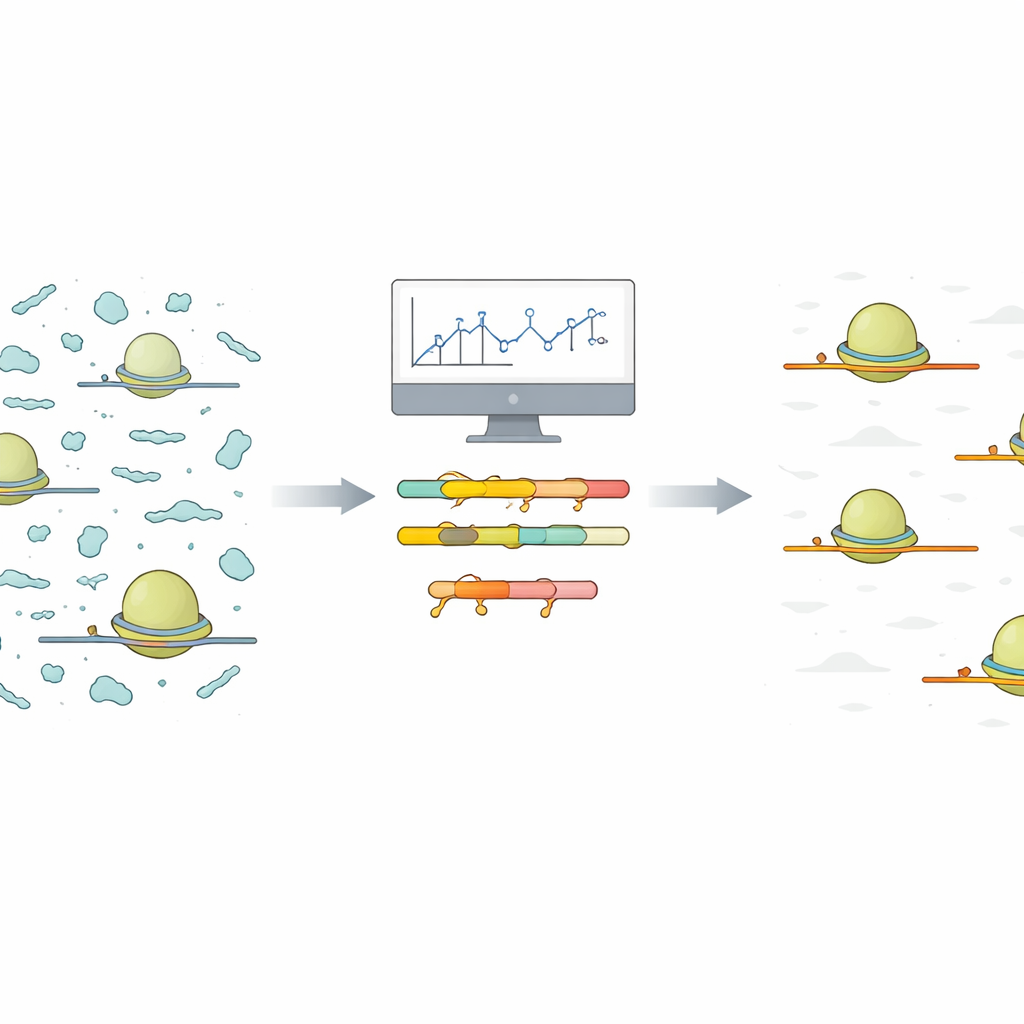
Problemet med brusiga ribosomögonblick
Ribo‑Seq fångar ett ögonblicksbild av vilka budskap i en cell som aktivt översätts till proteiner. För att göra detta isolerar forskare ribosomer tillsammans med de korta mRNA‑sträckor (mRNA) som de skyddar. Allt annat bryts ner, och de skyddade snuttarna sekvenseras och kartläggs tillbaka mot genomet. I praktiken smyger sig dock många andra små icke‑kodande RNA‑bitar igenom denna process. Eftersom dessa förorenande fragment är mycket vanliga och högst variabla, tar de upp en stor andel av sekvenseringsläsningarna, vilket lämnar färre läsningar för de verkliga protein‑kodande signalerna som forskarna är intresserade av.
Varför befintliga rensningsknep inte räcker
Standardstrategier försöker ta bort rikliga ribosomala och andra icke‑kodande RNA med fördesignade fångstprober eller enzymer. Dessa metoder fungerar bra när måltavlorna är intakta och förutsägbara, men Ribo‑Seq hugger avsiktligt RNA i många olika längder. Denna fragmentering rör till måltavlorna för fasta probeset, vilket gör depletionsstegen mycket mindre effektiva. Dessutom beror den exakta blandningen av föroreningar på den studerade arten, tillväxtförhållanden och till och med vilken nukleas som använts. Befintliga rensnings‑arbetsflöden innebär ofta också flera inkubations‑ och reningssteg, som tar tid och kan orsaka provförluster eller snedvridning.
Specialanpassade blockerare designade från verkliga data
Författarna föreslår ett förenklat tillvägagångssätt som börjar med en liten, lågkostnads pilotsekvensering under samma förhållanden som planeras för hela experimentet. De tillhandahåller ett R‑script som tar de alignerade läsningarna från denna pilotkörning och automatiskt grupperar liknande förorenande fragment baserat på sekvens. För varje grupp rapporterar scriptet den kortaste gemensamma sekvens som förekommer över fragmenten. Dessa korta, delade sträckor är idealiska måltavlor för specialiserade molekyler kallade locked nucleic acid (LNA) oligonukleotider. LNA är korta kedjor med en kemisk modifiering som gör att de binder mycket starkt till matchande RNA. Scriptet genererar också intuitiva heatmaps och sammanfattande diagram som hjälper användaren att se vilka föroreningar som dominerar och hur många LNA‑mål som skulle behövas för en betydande rensning.
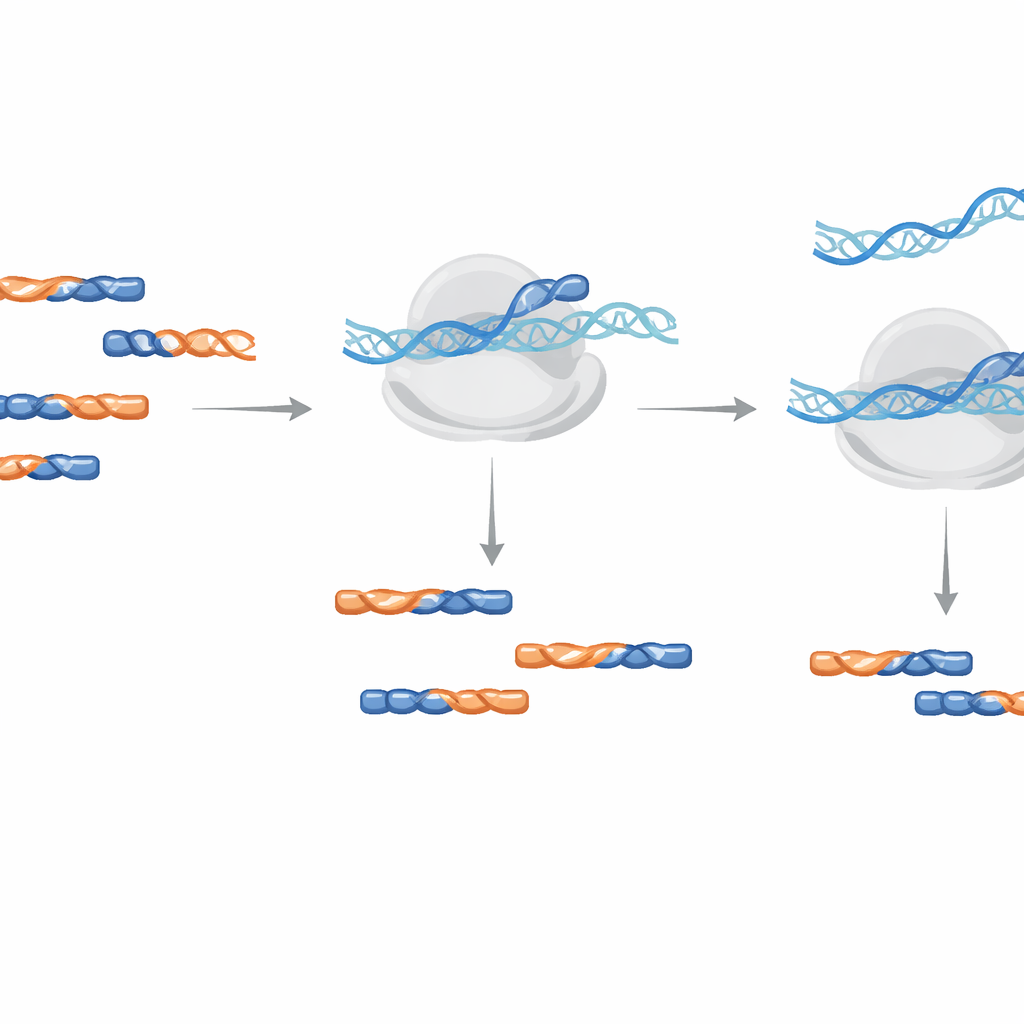
Enstegs‑rensning under amplifiering
I stället för att fysiskt dra ut föroreningar ur provet använder metoden LNA‑oligonukleotider som blockerare under DNA‑förstärkningssteget som bygger sekvenseringsbiblioteket. Författarna testade att tillsätta dessa blockerare antingen under den initiala omvända transkriptionssteget eller under senare PCR‑amplifiering. De fann att tillsats under amplifieringen var mer effektivt och krävde lägre koncentrationer, vilket reducerade en testförorening med över tusenfaldigt samtidigt som det fungerade oberoende av strängorientering. Praktiska designtips inkluderar att alternera vanliga DNA‑ och LNA‑byggstenar, använda en minsta längd på 14 enheter för växten Arabidopsis, och modifiera ände‑stumpen så att blockeraren själv inte av misstag kan förlängas.
Fler användbara läsningar utan att förvränga signalen
För att visa verklig prestanda designade teamet fem LNA‑blockerare riktade mot de vanligaste föroreningsgrupperna som ses över typiska tillväxtförhållanden i Arabidopsis‑växter. När de tillsatte denna blandning under bibliotekens amplifiering sjönk andelen identifierade föroreningar med mer än 30 %, och antalet användbara protein‑kodande läsningar nästan fördubblades. Viktigt är att när de jämförde gen‑nivå läsantal mellan bibliotek med och utan LNA‑behandling stämde värdena nästan perfekt överens, vilket indikerar att blockerarna tog bort skräpfragment utan att förvränga den biologiska signalen från genuina mRNA‑fotavtryck.
Vad detta betyder för framtida experiment
Detta arbete visar att ett kort pilotexperiment, i kombination med ett lättanvänt analys‑script och en liten uppsättning skräddarsydda LNA‑blockerare, kan förvandla röriga Ribo‑Seq‑bibliotek till mycket renare och mer informativa dataset i ett enda pipetteringssteg. Forskarna får fler meningsfulla läsningar per körning, sparar kostnader och förenklar experimentdesignen samtidigt som de bevarar noggranna mätningar av hur gener översätts. Författarna tillhandahåller också färdiga föroreningsprofiler och blockerar‑designer för vanliga växtförhållanden, och föreslår att liknande resurser kan byggas för många organismer, vilket gör högkvalitativ ribosomprofilering mer tillgänglig i forskarsamhället.
Citering: Ricciardi, D.A., Peter, F.E. & Böhmer, M. Data-driven design of LNA-blockers for efficient contaminant removal in Ribo-Seq libraries. Sci Rep 16, 8565 (2026). https://doi.org/10.1038/s41598-026-43117-3
Nyckelord: ribosomprofilering, RNA‑föroreningar, locked nucleic acids, rensning av sekvenseringsbibliotek, translationsreglering