Clear Sky Science · sv
Tänk om kontextkonstruktion med en uppmärksamhetsbaserad arkitektur
Varför smartare programhjälpare spelar roll
Varje klick du gör i en företagsapplikation—logga in, ladda upp en fil, köra en rapport—lämnar ett spår. Om mjukvara kunde förutsäga ditt nästa steg pålitligt skulle den kunna förladda data, föreslå genvägar och svara nästan omedelbart. Denna artikel utforskar ett nytt sätt att lära datorer att förstå dessa handlingsspår så väl att digitala assistenter kan förutse vad du kommer att göra härnäst, vad du försöker uppnå och när du är på väg att logga ut.
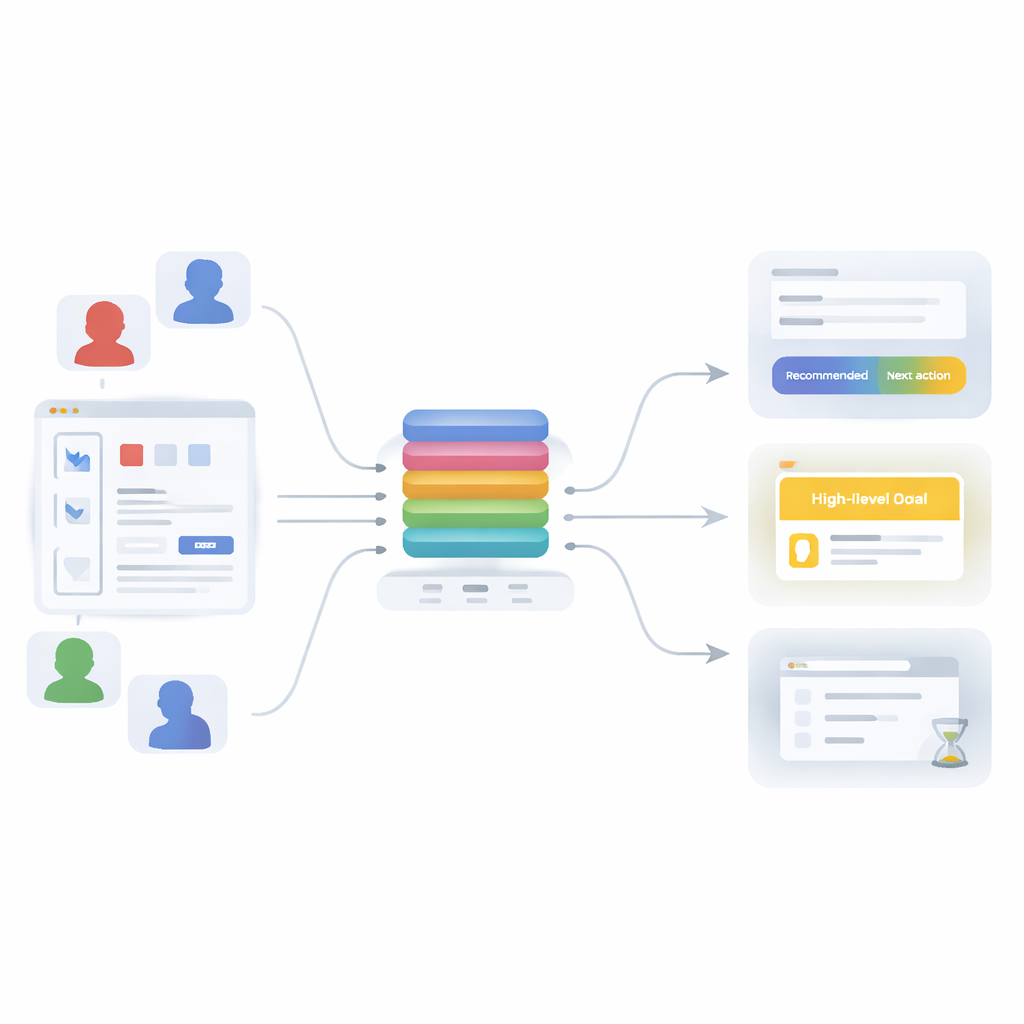
Från enkla kedjor till rika mönster
Många befintliga system som gissar en användares nästa steg förlitar sig på Markov-kedjor, ett klassiskt matematiskt verktyg som bara ser på den senaste åtgärden för att förutsäga nästa. Trots att det är snabbt och bekvämt fallerar detta "ettstegsminne" i verkliga arbetsmiljöer, där uppgifter som att bygga en maskininlärningspipeline eller förbereda en instrumentpanel utvecklas över många steg och involverar olika verktyg. Författarna hävdar att sådana enkla modeller missar långsiktig struktur, bara kan hantera ett förutsägelsemål åt gången och är svåra att jämföra mellan studier eftersom de ofta beror på privata loggar och oklara dataurvalsval.
En ny blueprint för multitask-lärande
För att övervinna dessa begränsningar introducerar artikeln en uppmärksamhetsbaserad transformer-modell—samma familj tekniker som ligger bakom moderna språkinstrument—omtolkad för användarbeteende. Istället för att lära sig bara en sak tränas modellen att lösa tre relaterade uppgifter samtidigt: förutsäga nästa åtgärd (vilket API en användare kommer att anropa), avgöra sessions övergripande mål (såsom att köra en maskininlärningsarbetsflöde, göra dataanalys, hantera användare eller skapa snabba visualiseringar) och bedöma om det nuvarande steget sannolikt är det sista i sessionen. Alla tre uppgifter delar en gemensam "ryggrad" som omvandlar en kort historik av nyliga åtgärder till en enda, rik representation av vad som pågår, vilken sedan matas in i tre små prediktionsmoduler.
Att bygga en realistisk testbädd in silico
Eftersom verkliga företagsaktivitetsloggar ofta är känsliga och svåra att dela bygger författarna en sofistikerad simulerad miljö som efterliknar hur dataproffs använder en stor intern plattform. De definierar 100 distinkta API:er grupperade i 10 funktionella områden, inklusive autentisering, datainmatning, bearbetning, modellträning, visualisering, export och administration. Fyra användarpersonas—dataforskare, affärsanalytiker, utvecklare och avancerade användare—följer karakteristiska men ofullkomliga arbetsflöden, med sannolikheter som speglar både rutinbeteenden och tillfälliga avvikelser. Den resulterande datasetet innehåller 2 000 användarsessioner och 20 000 API-anrop, med sessionmål som "maskininlärningspipeline" och "snabb visualisering" som ger igenkännliga vägar som att logga in, ladda data, bearbeta den, skapa ett diagram och exportera resultatet.
Hur väl modellen lär sig att förutse
Tränad på denna strukturerade men varierade miljö visar transformer-modellen att uppmärksamhetsbaserat lärande kan fånga dolda regelbundenheter i användarbeteende mycket bättre än äldre metoder. För huvuduppgiften—att gissa nästa API-anrop bland 100 val—har den rätt nästan 80 % av gångerna, och placerar det korrekta valet bland sina fem bästa förslag mer än 99,9 % av gångerna, en förbättring på över fyra gånger jämfört med en grundläggande Markov-kedja. Samtidigt identifierar den korrekt användarens övergripande sessionsmål i runt 82 % av fallen och upptäcker nästan perfekt när en session är på väg att avslutas. Författarna betonar också att modellen är relativt kompakt och effektiv, vilket gör realtidsanvändning möjlig för liveassistenter som måste svara utan märkbar fördröjning.
Verktyg för andra att återanvända och bygga vidare på
För att göra tillvägagångssättet mer än ett engångsexperiment släpper författarna ett open source-programpaket, kallat context-engineer, tillsammans med det fullständiga simulerade datasetet. Med dessa resurser kan andra forskare och praktiker reproducera de rapporterade resultaten, testa alternativa modeller på en delad benchmark eller koppla in sina egna interna loggar genom att mappa åtgärder och sessionsetiketter till ett enkelt numeriskt format. Denna öppenhet tar itu med ett stort hinder inom fältet, där många tidigare system inte kunde jämföras rättvist eller återanvändas eftersom deras data och kod var otillgängliga.
Vad detta betyder för vardagsanvändare
För en icke-specialist är den viktigaste slutsatsen att artikeln erbjuder ett praktiskt recept för att få digitala verktyg att kännas mer "ett steg före." Genom att gemensamt lära sig vad människor försöker göra, vad de sannolikt kommer att klicka på härnäst och när de håller på att avsluta, förvandlar det föreslagna transformerbaserade systemet användarhistorik till en form av kontextmedvetenhet. I verkliga tillämpningar kan detta innebära chattbottar som förbereder nästa rapport innan du ber om den, analysplattformar som föreslår rimliga uppföljningsåtgärder och företagsinstrumentpaneler som tyst minskar väntetider. Även om den aktuella studien bygger på simulerade data och behöver testas på verkliga loggar, lägger den en tydlig, reproducerbar grund för att bygga smartare, mer förutseende programhjälpare över många typer av digitala plattformar.
Citering: Yin, Y. Rethink context engineering using an attention-based architecture. Sci Rep 16, 8851 (2026). https://doi.org/10.1038/s41598-026-43111-9
Nyckelord: förutsägelse av användarbeteende, sekventiella rekommendationer, uppmärksamhetsbaserad transformer, proaktiva digitala assistenter, kontextkonstruktion