Clear Sky Science · sv
Hybridjusterad djupinlärningsmodell för bröstcancerdiagnos med genetiska data
Varför detta är viktigt för patienter och familjer
Bröstcancer är nu den vanligast diagnostiserade cancern hos kvinnor globalt, och att upptäcka den tidigt kan vara skillnaden mellan liv och död. Läkare har i allt högre grad tillgång till en persons genetiska information, men att omvandla tiotusentals genmätningar till tydliga svar är oerhört svårt. Denna artikel beskriver en ny datormodell som läser dessa komplexa genetiska mönster för att upptäcka bröstcancer och förutsäga utfall med slående noggrannhet, vilket potentiellt ger kliniker ett kraftfullt verktyg för tidigare och mer pålitliga beslut.
Från gener till varningssignaler
Varje brösttumör bär ett molekylärt fingeravtryck kodad i aktiviteten hos tusentals gener. Författarna ville bygga ett system som kunde läsa detta fingeravtryck direkt, i stället för att förlita sig endast på bilder eller ett fåtal välkända gener som BRCA1 och BRCA2. De arbetade med två av de största offentliga resurserna inom cancergenomik: TCGA:s bröstcancergrupp, som inkluderar genaktivitet för 17 814 gener i 590 prov, och METABRIC-studien, som innehåller genomisk och klinisk information för mer än 1 400 patienter. Deras mål var ambitiöst: att utforma en metod som kan hantera denna informationsflod, hitta de mest talande signalerna och ändå fungera pålitligt i helt separata patientgrupper.
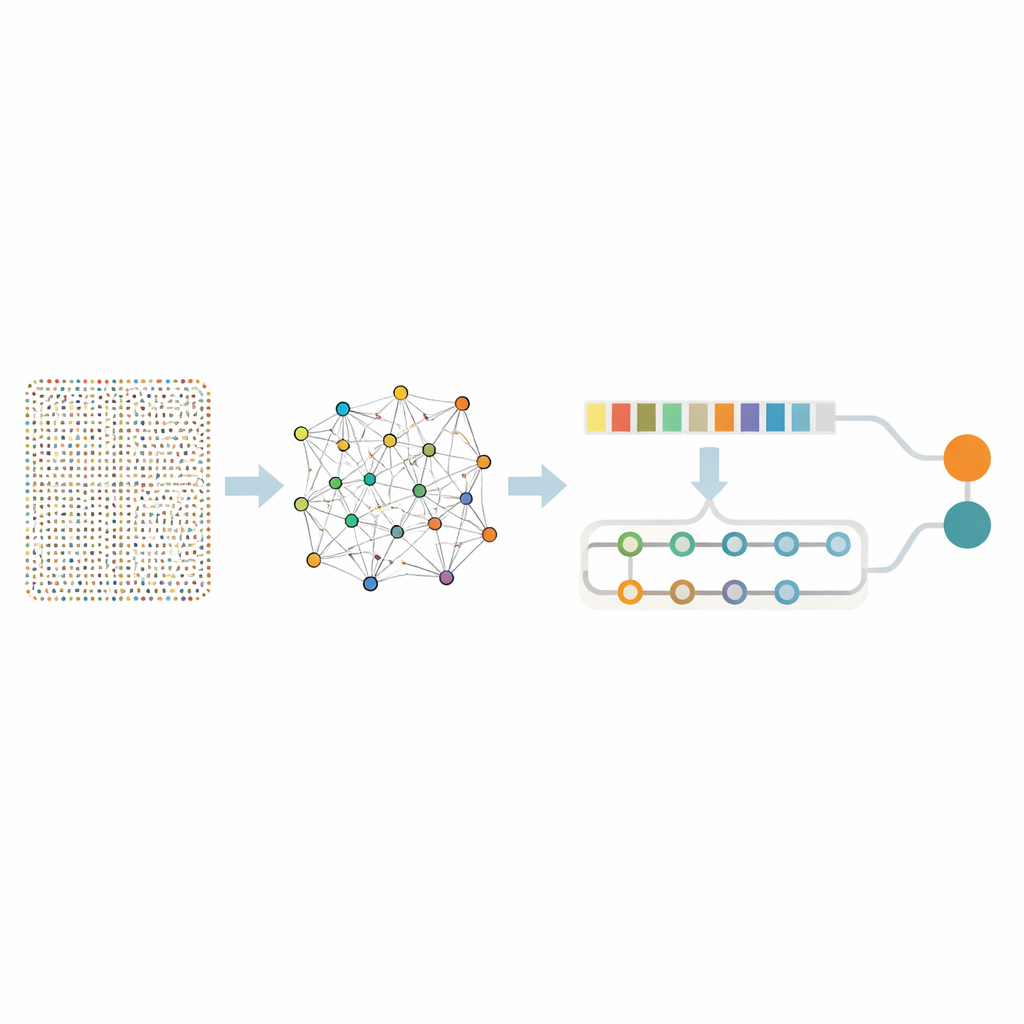
Koka ner tusentals gener till en användbar uppsättning
Att betrakta nästan arton tusen gener samtidigt är överväldigande även för avancerade algoritmer, och det finns risk att man plockar upp meningslöst brus. Forskarna använde därför ett tvåstegs "sikt" för att isolera en mindre uppsättning verkligt informativa gener. Först använde de en teknik kallad Random Forest, som i praktiken låter många beslutsträd avgöra vilka gener som spelar störst roll för att skilja cancervävnad från frisk vävnad. Detta steg trimmande listan till 436 lovande gener. Därefter undersökte de hur dessa gener beter sig tillsammans med hjälp av association rule mining, en metod som upptäcker grupper av gener som tenderar att vara aktiva samtidigt i tumörer. Detta extra analyssteg identifierade genpar och nätverk kopplade till centrala cancerprocesser såsom snabb celldelning, DNA-reparation och förändringar i vävnaden runt tumören. Efter denna förfining återstod 332 gener — fortfarande rika på biologisk betydelse men avsevärt mer hanterbara för djupare analys.
En tvådelad neuralt nätverk som lär sig mönster och kontext
Med denna fokuserade gensats byggde teamet en hybrid djupinlärningsmodell som kombinerar två typer av neurala nätverk. En del, känd som ett konvolutionellt nätverk, skannar längs genlistan för att plocka upp lokala mönster — kluster av gener som tenderar att öka eller minska tillsammans. Den andra delen, ett bidirektionellt minnesnätverk, betraktar samma information samtidigt som det håller reda på långsiktiga relationer och fångar hur avlägsna gener påverkar varandra över hela profilen. Innan träning balanserade författarna data så att cancer- och icke-cancerprov representerades rättvist och lade till små mängder artificiellt brus, vilket lärde modellen att inte luras av slumpmässiga fluktuationer.
Hur väl systemet presterar i verkliga tester
När det tränades och testades på TCGA-data särskilde det hybrida nätverket korrekt tumör från normala prover med cirka 97 % noggrannhet och en nästan perfekt förmåga att separera de två grupperna. Viktigt är att det överträffade enklare djupinlärningsupplägg och standardverktyg inom maskininlärning såsom logistisk regression och supportvektormaskiner, även när dessa konkurrerande metoder fick samma noggrant utvalda gener. Det starkaste testet var dock om modellen skulle hålla för en helt annan datamängd. Tillämpad på METABRIC, som samlats in på andra sjukhus med andra laboratoriemetoder, bibehöll systemet hög prestanda: i sitt bästa körning uppnådde det 99,3 % noggrannhet och identifierade korrekt varje patient som senare dog av bröstcancer — en avgörande egenskap om verktyget ska användas för att flagga högriskfall.
Vad detta kan innebära för framtida vård
För en icke-specialist är slutsatsen att denna studie levererar ett smart filter och en tolk för genetiska data som kan upptäcka bröstcancer och relaterad risk med anmärkningsvärd konsekvens över stora patientgrupper. Genom att kombinera en genomtänkt genurvalsstrategi med ett tvågrensat neuralt nätverk visar författarna att datorer kan extrahera kliniskt meningsfulla signaler från enorma genetiska dataset, inte bara i en studie utan över oberoende kohorter. Även om mer arbete behövs för att testa metoden i olika populationer och för att förklara dess beslut i detalj, pekar metoden mot en framtid där ett enkelt blod- eller vävnadsprov kan matas in i sådana modeller och hjälpa läkare att upptäcka tumörer tidigare och skräddarsy behandlingar mer precist.
Citering: Hesham, F., Abbassy, M.M. & Abdalla, M. Hybrid tuned deep learning model for breast cancer diagnosis using genetic data. Sci Rep 16, 9664 (2026). https://doi.org/10.1038/s41598-026-41643-8
Nyckelord: bröstcancergenomik, djupinlärningsdiagnos, genuttrycksbiomarkörer, tidig cancerupptäckt, kliniskt beslutsstöd