Clear Sky Science · sv
Tidig upptäckt av kronisk njursjukdom baserat på en SURD-förstärkt maskininlärningsmodell
Varför det är viktigt att fånga upp njurproblem tidigt
Kronisk njursjukdom smyger sig ofta på utan tydliga varningssignaler tills njurarna är allvarligt skadade. Enkla blod- och urinprov kan dock avslöja problem år tidigare, när behandling kan sakta ner eller till och med förebygga allvarlig försämring. Denna studie utforskar ett nytt sätt att sålla bland rutinmässiga provresultat med hjälp av avancerade, men tolkbara, datorbaserade modeller så att personer med hög risk kan identifieras tidigare och läkare kan förstå varför.
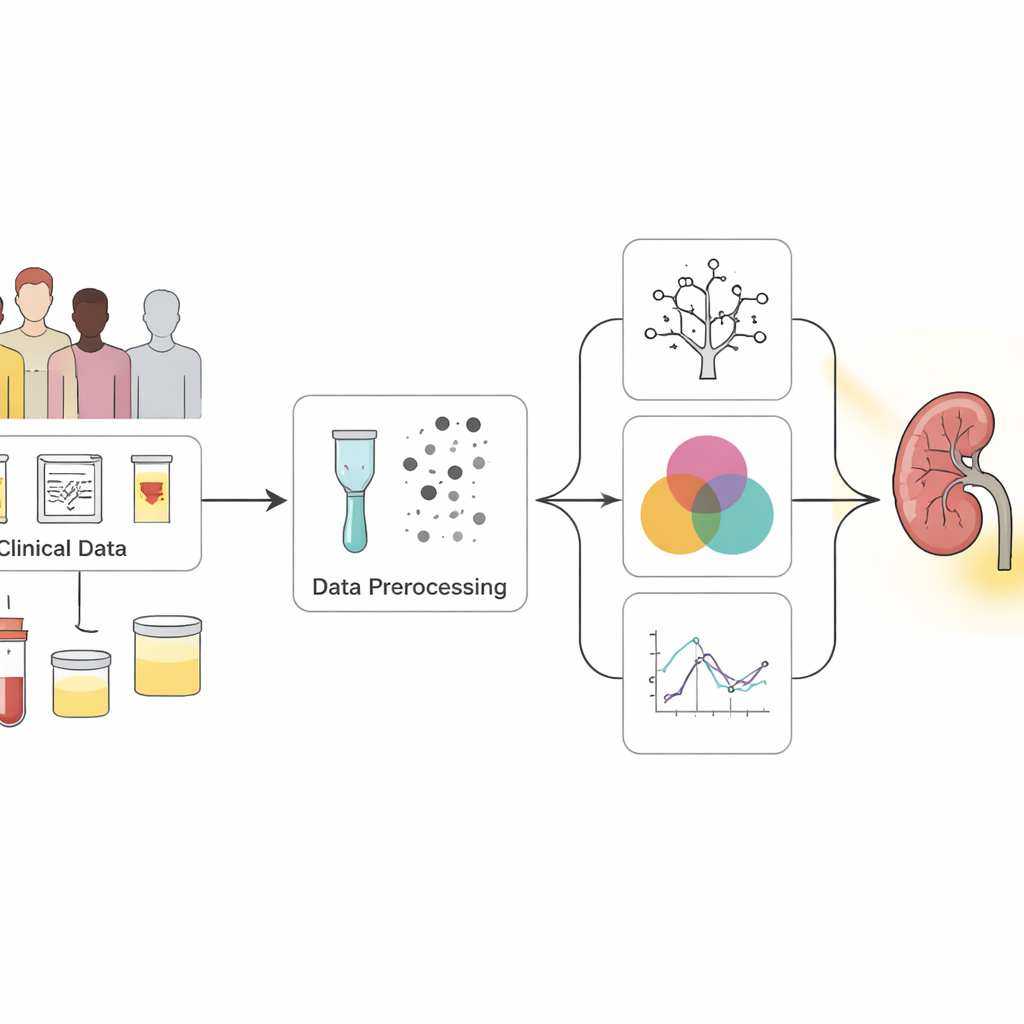
Att omvandla röriga vårduppgifter till tydliga signaler
Forskarna började med en allmänt använd offentlig datamängd med 400 personer, de flesta redan diagnostiserade med kronisk njursjukdom. Varje person hade 25 mätvärden, från blodtryck och blodvärden till urinfynd och sjukdomshistoria som diabetes och högt blodtryck. Många poster var ofullständiga, så teamet använde noggranna statistiska metoder för att fylla i saknade värden i stället för att enkelt kasta bort patienter. De balanserade också datan så att friska och sjuka fall blev mer jämnt representerade, vilket hjälpte modellerna att lära sig känna igen båda grupperna på ett rättvist sätt.
Att se bortom enkla korrelationer
De flesta medicinska prediktionsverktyg behandlar varje provresultat separat: de undersöker hur starkt en mätning, som blodsocker, är kopplad till sjukdom. Men i kroppen verkar riskfaktorer sällan ensamma. Vissa tester förmedlar nästan samma information, medan andra bara blir informativa i kombination. För att fånga detta använde författarna en ram kallad SURD som bryter ner varje variabels bidrag i tre delar: information som delas med andra tester, unik information och information som bara framträder när variabler samverkar. Detta gjorde det möjligt att gruppera laboratorievärden och kliniska fynd i ”unika”, ”redundanta” och ”synergistiska” uppsättningar innan de matades in i prediktionsmodellerna.
Att lära många modeller och välja de mest pålitliga
Med dessa SURD-baserade funktionsgrupper i handen tränade teamet tio olika maskininlärningsmodeller, från enkla beslutsträd till mer komplexa metoder som random forests och neurala nätverk. De jämförde prestanda när modellerna använde alla tillgängliga funktioner kontra endast en kombinerad uppsättning av unika och synergistiska funktioner. I nästan alla modelltyper presterade denna reducerade, SURD-styrda funktionsuppsättning lika bra eller bättre än den fullständiga samlingen av 25 variabler, och förbättrade ofta balansen mellan att korrekt identifiera sjuka patienter och undvika falska larm. Särskilt träd-baserade modeller som random forests och boosted trees nådde nästan perfekta poäng på den ursprungliga datamängden.
Test av metoden i verkliga sjukhusdata
Utmärkt prestanda på en liten benchmarkdatamängd kan vara missvisande om en modell misslyckas när den utsätts för mer varierade patienter. För att skydda mot detta validerade författarna sitt tillvägagångssätt med en mycket större sjukhusdatabas med över 27 000 intensivvårdspatienter. Här särskilde random forest-modellen byggd på SURD-valda funktioner fortfarande patienter med och utan njursjukdom med extremt hög noggrannhet. Dess prestanda överglänste tydligt en enklare beslutsträdmodell, vilket tyder på att metoden kan generalisera bortom en noggrant kuraterad forskningsdatamängd till rörigare verkliga journaler.
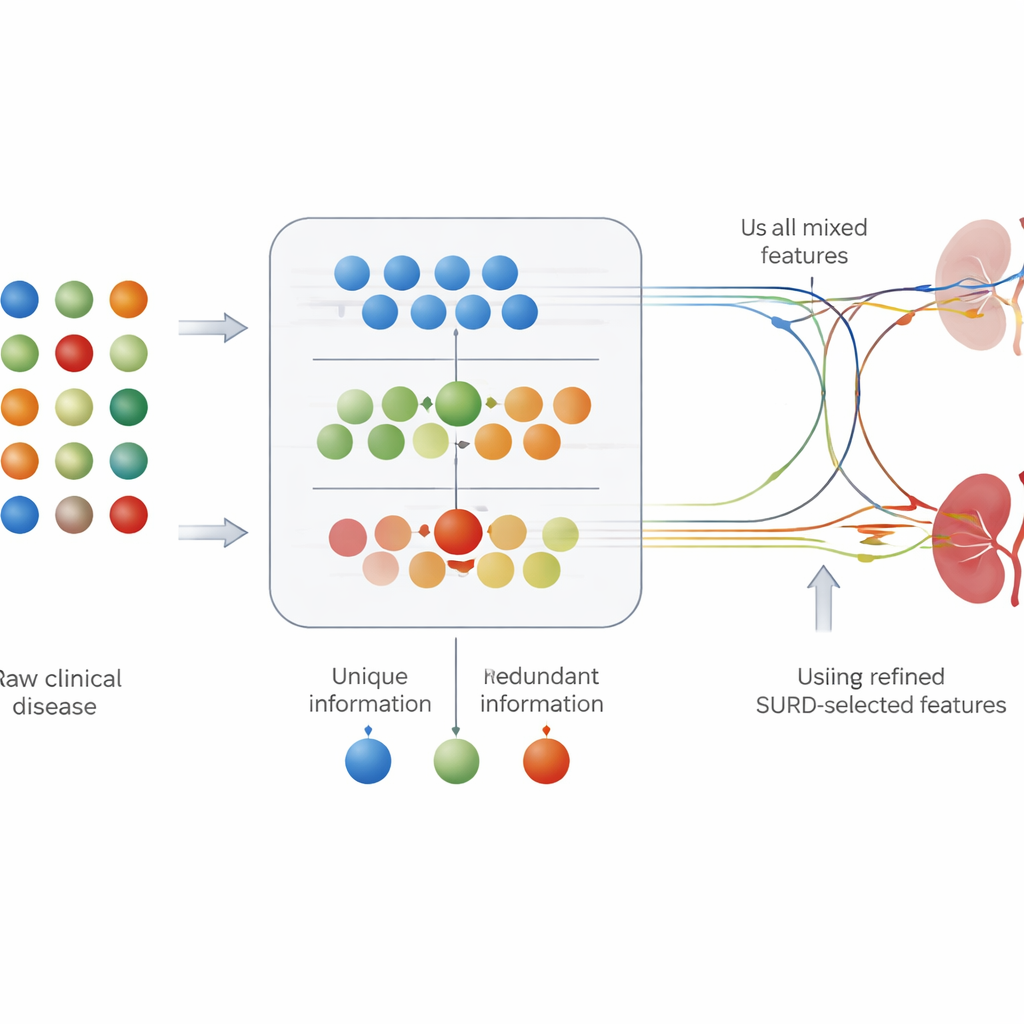
Att se vilka tester som är viktiga och varför
Noggrannhet räcker inte för klinisk användning; läkare behöver också veta vilka provresultat som driver en prediktion. Studien kombinerade SURD med moderna förklaringsverktyg som tilldelar varje funktion ett bidrag till modellens beslut för en given patient. Denna analys framhävde välkända riskmarkörer, såsom serumkreatinin (en direktmarkör för njurfunktion), hemoglobinnivåer, urinkoncentration och förekomst av diabetes eller högt blodtryck. Intressant visade SURD att några av dessa faktorer mest verkar i samverkan med andra, medan kreatinin framträder som en starkt informativ signal i sig. Tillsammans ger dessa tekniker både en övergripande bild av vilka tester modellen förlitar sig på och patientnivåförklaringar till varför en viss person förutses ha hög risk.
Vad detta betyder för vardaglig vård
Kort sagt visar studien att det är möjligt att bygga en njursjukdoms-riskkalkylator som både är mycket noggrann och relativt transparent. Genom att separera överlappande från verkligt unik information i rutinmässiga laboratorie- och anamnesdata gör de SURD-styrda modellerna skarpare prediktioner utan att bli en mystisk svart låda. Även om ytterligare arbete behövs i bredare och mer varierade patientgrupper, skulle detta tillvägagångssätt så småningom kunna hjälpa kliniker att upptäcka njurproblem tidigare, fokusera uppmärksamheten på de mest informativa testerna och förklara för patienter på ett rakt sätt vilka aspekter av deras hälsa som sätter deras njurar i riskzonen.
Citering: Xue, N., Bai, T., Jia, X. et al. Early detection of chronic kidney disease based on a SURD-enhanced machine learning model. Sci Rep 16, 10444 (2026). https://doi.org/10.1038/s41598-026-41050-z
Nyckelord: kronisk njursjukdom, njurriskprediktion, medicinsk maskininlärning, förklarbar AI, elektroniska patientjournaler