Clear Sky Science · sv
Utvärdering av upplösningskrav för subtil diskriminering av Caenorhabditis elegans-stammar med klassiska deskriptorer och CNN–transformermodeller
Varför små maskar och skarpa bilder spelar roll
Forskare använder ofta en mikroskopisk mask kallad Caenorhabditis elegans för att studera hur gener, åldrande och läkemedel påverkar nervsystemet. Många maskstammar ser och rör sig nästan likadant för blotta ögat, men dessa små skillnader kan avslöja hur deras hjärnor och muskler fungerar. Denna studie ställer en praktisk fråga: hur skarpa behöver våra bilder egentligen vara för att upptäcka sådana subtila förändringar i rörelse, och när drar moderna artificiella intelligensverktyg faktiskt nytta av högre upplösning?
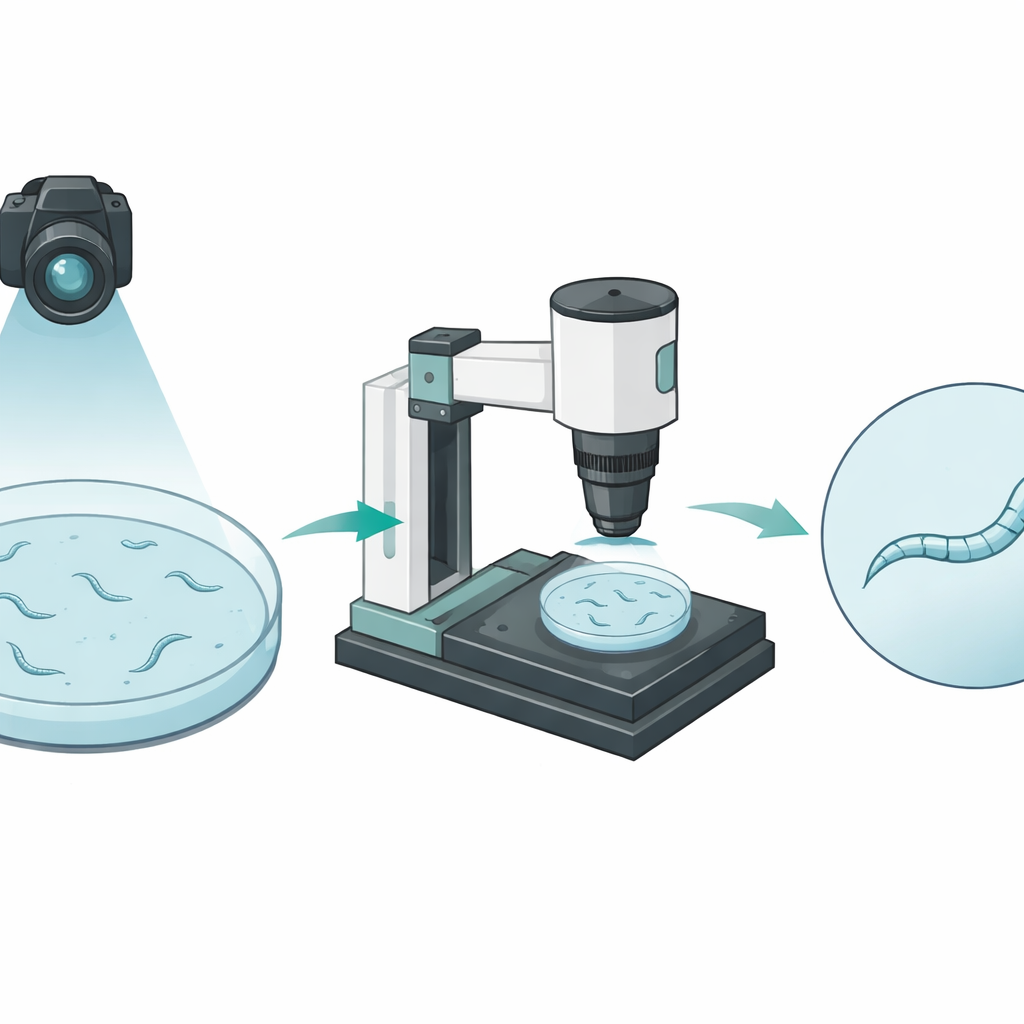
Att bevaka maskar på avstånd och nära håll
Forskarna byggde en automatiserad bildplattform som betraktar maskarna i två mycket olika skalor. Ett par kameror ser först hela petriskålen uppifrån och följer många maskar när de kryper runt. Denna vidvinkel fångar hur långt varje djur förflyttar sig men visar varje mask som bara några pixlar bred, som en pinnefigur sedd på avstånd. Ett separat motoriserat mikroskop kan sedan zooma in på en utvald mask och hålla den centrerad och i fokus under en hel minut. I dessa närbilder täcker maskens kropp dussintals pixlar i bredd och avslöjar fina böjningar och formförändringar när den rör sig.
Enkla mätningar når en gräns
För att jämföra vad varje vy kunde avslöja spelade teamet in tre typer av maskar. En var den standardiserade vildtypstammen som användes som referens. En andra var en mutant med extremt klumpig rörelse som är lätt att upptäcka. Den tredje var en specialkonstruerad stam med endast mycket milda motoriska problem, känd för att vara svår att skilja från referensstammen även för ögat. Från både vidvinkel- och närbildsinspelningarna extraherade forskarna traditionella mått såsom hur långt varje mask färdades, hur snabbt den rörde sig och hur dess kroppsform förändrades över tid. Som förväntat separerade båda vyerna tydligt den mycket klumpiga mutanten från de andra två stammarna. Däremot kunde ingen av dessa standardmätningar, varken var för sig eller tillsammans, pålitligt skilja de subtilt förändrade maskarna från de normala.
Låta djuplärning läsa av rörelsen
Nästa steg var en mer flexibel metod: en djuplärningsmodell som analyserar själva bildsekvensen i stället för handplockade mått. Varje bildruta passerades först genom ett konvolutionellt neuralt nätverk som lärde sig koda maskens utseende. Dessa rut-baserade funktioner matades sedan in i en Transformer-modul som analyserade hur hållningen utvecklades under 60-sekundersklippet. När modellen tränades på de lågdetaljerade, skålöversiktliga videorna presterade den inte bättre än slumpen för att skilja den subtila stammen från referensen. Men när den tränades på de högdetaljerade mikroskopinspelningarna klassificerade den konsekvent de två stammarna med omkring trekvarts korrekthet och avslöjade rörelsemönster som var för svaga för att standarddeskriptorerna skulle fånga upp.
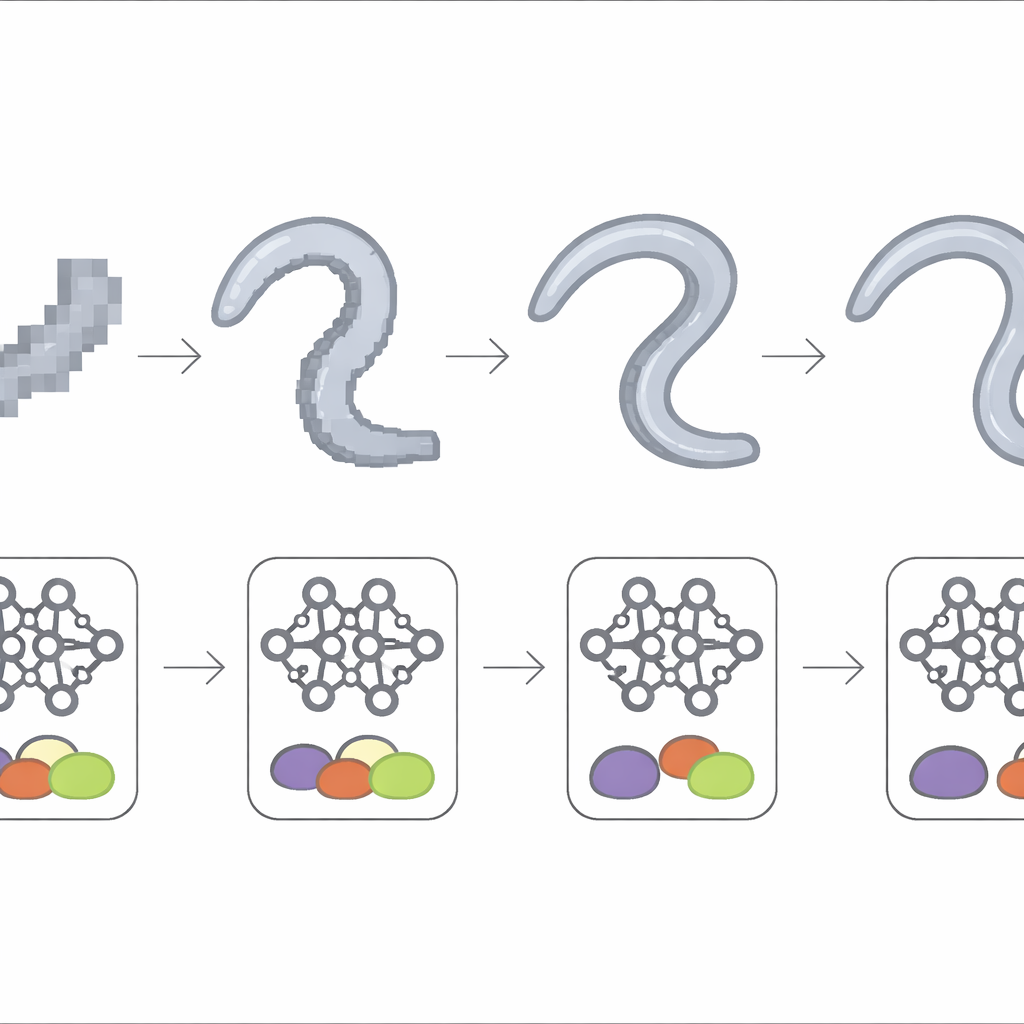
Hur mycket detalj räcker?
För att bestämma bildskärpans roll suddade teamet gradvis ut mikroskopinspelningarna genom att krympa deras storlek med faktorerna två, fyra, åtta och sexton och tränade om samma djuplärningsmodell varje gång. Prestandan förblev hög när maskens kropp fortfarande täckte ett par dussin pixlar i bredd, vilket innebär att modellen tolererade måttlig detaljförlust. När masken krympte till omkring tio pixlar i bredd eller mindre sjönk noggrannheten brant och blev instabil mellan experiment. I de grövsta skalorna närmade sig resultaten dem från skålöversikten och de enkla statistiska metoderna, vilket indikerar att de subtila signaturerna för den milda motoriska defekten i praktiken hade försvunnit ur bilderna.
Vad detta betyder för framtida maskstudier
För experiment där man bara behöver skilja tydliga rörelsedefekter verkar en bred, lågupplöst vy räcka, och klassiska mått på sträcka och hastighet fungerar bra. Men när målet är att upptäcka små förändringar i hur maskar böjer sig och koordinerar sina kroppar—sådana som orsakas av milda genetiska förändringar eller svaga läkemedelseffekter—visar detta arbete att både högupplöst avbildning och sekvensbaserade djuplärningsmodeller behövs. Kort sagt: för att se de tysta viskningarna av sjukdoms- eller behandlingspåverkan i dessa små djur måste vi inte bara titta tillräckligt nära utan även använda verktyg tillräckligt smarta för att läsa de subtila mönstren i deras rörelser.
Citering: Peñaranda-Jara, JJ., Escobar-Benavides, S., Puchalt, JC. et al. Evaluating resolution requirements for subtle caenorhabditis elegans strain discrimination using classical descriptors and CNN–transformer models. Sci Rep 16, 8664 (2026). https://doi.org/10.1038/s41598-026-40784-0
Nyckelord: C. elegans lokomotion, fenotypklassificering, bildupplösning, djuplärning, beteendespårning