Clear Sky Science · sv
Dynamisk maskininlärningsmetod för arbetsbelastningsprognoser i molnmiljöer
Varför smart trafikprognos spelar roll
Varje gång du streamar en video, följer en stor sporthändelse online eller handlar under en blixtrea kan tusentals andra klicka vid samma tillfälle. Bakom kulisserna kämpar molndatacenter för att hålla webbplatser snabba utan att slösa pengar på tomgångsservrar. Denna artikel tar itu med en enkel fråga med stor praktisk betydelse: hur kan molnsystem förutse plötsliga vågor av webbtrafik tillräckligt väl för att slå på och av servrar i rätt tid, istället för att gissa och betala för mycket?
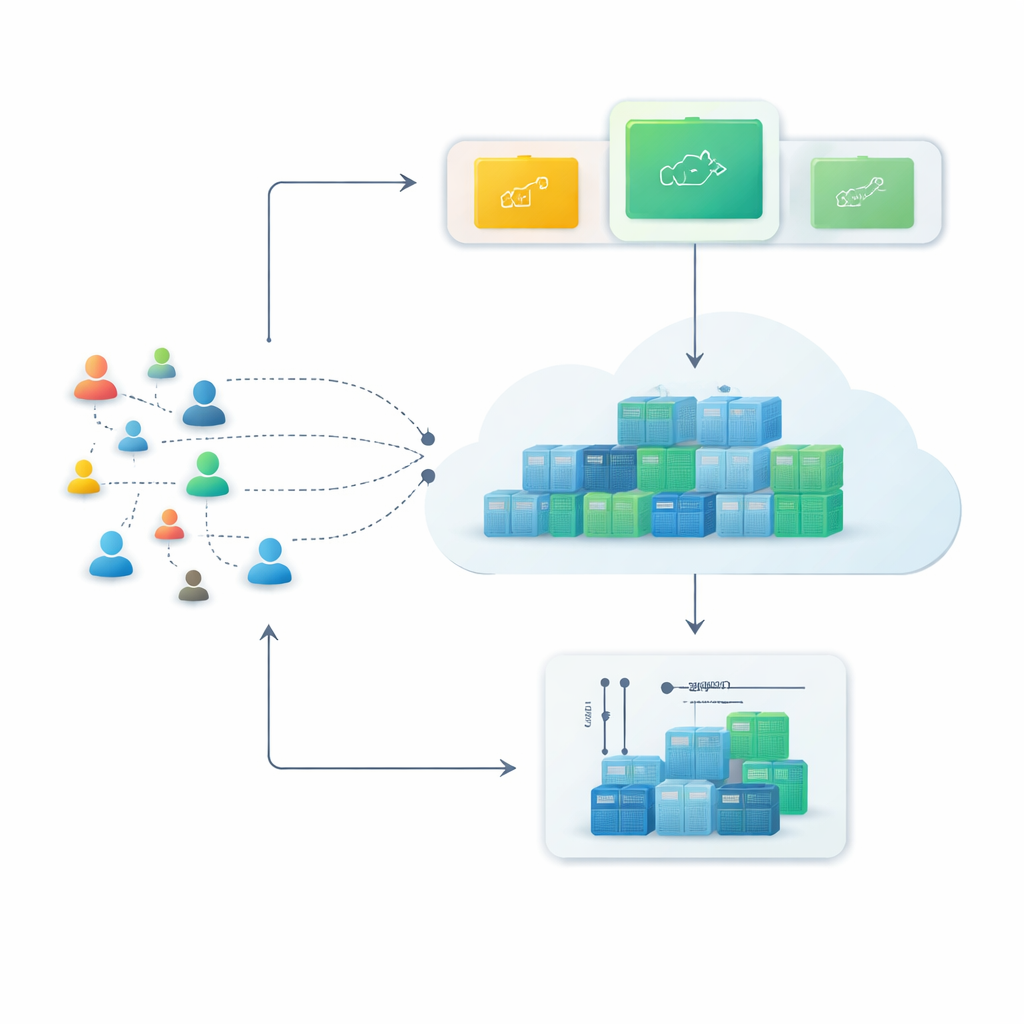
Från stela servrar till flexibla containrar
Moderna molnplattformar förlitar sig i allt högre grad på containrar, små programvarupaket som kan startas eller stoppas på sekunder. Jämfört med traditionella virtuella maskiner är containrar lättare och kan packas tätare, vilket gör dem perfekta för tjänster som måste växa snabbt under rusningstid och krympa igen efteråt. Denna flexibilitet lönar sig dock bara om systemet kan se problem i förväg—om det kan förutsäga hur många webbförfrågningar som kommer inom de närmaste minuterna och förbereda rätt antal containrar i förväg.
Varför en modell inte räcker
Tidigare forskning har försökt många olika sätt att prognostisera webbtrafik, från klassisk statistik till djupa neurala nätverk. Vissa metoder fungerar bra när efterfrågan förändras jämnt över dagen; andra är bättre när trafiken hoppar oförutsägbart, som under en VM-match. Problemet är att ingen ensam metod är bäst hela tiden. Om operatörer väljer en favoritmodell och håller fast vid den kan noggrannheten sjunka kraftigt när användarbeteendet förändras, vilket leder antingen till långsamma sajter eller till rader av underutnyttjade maskiner som i tysthet slösar pengar och energi.
Ett inlärningsloop som aldrig slutar anpassa sig
För att övervinna detta föreslår författarna ett slutet ramverk som de kallar Monitor–Train–Test–Deploy. Idén är att betrakta prognostisering som en levande process. Först registrerar systemet kontinuerligt inkommande webbförfrågningar i en tidsstämplad historik. Därefter tränar det flera olika prognosmetoder parallellt, var och en försöker lära sig mönster i den senaste historiken. Sedan testar det dessa kandidatmodeller på den senaste datan och poängsätter dem efter hur långt deras gissningar avviker från verkligheten. Endast den bäst presterande modellen får ansvaret för att göra live-prognoser, vilka styr hur många containrar som körs. När ny trafik anländer upprepas loopen: om prognosfelen växer bortom en tolererad nivå under två cykler i rad återtränas systemet automatiskt och kan lämna över kontrollen till en annan modell.
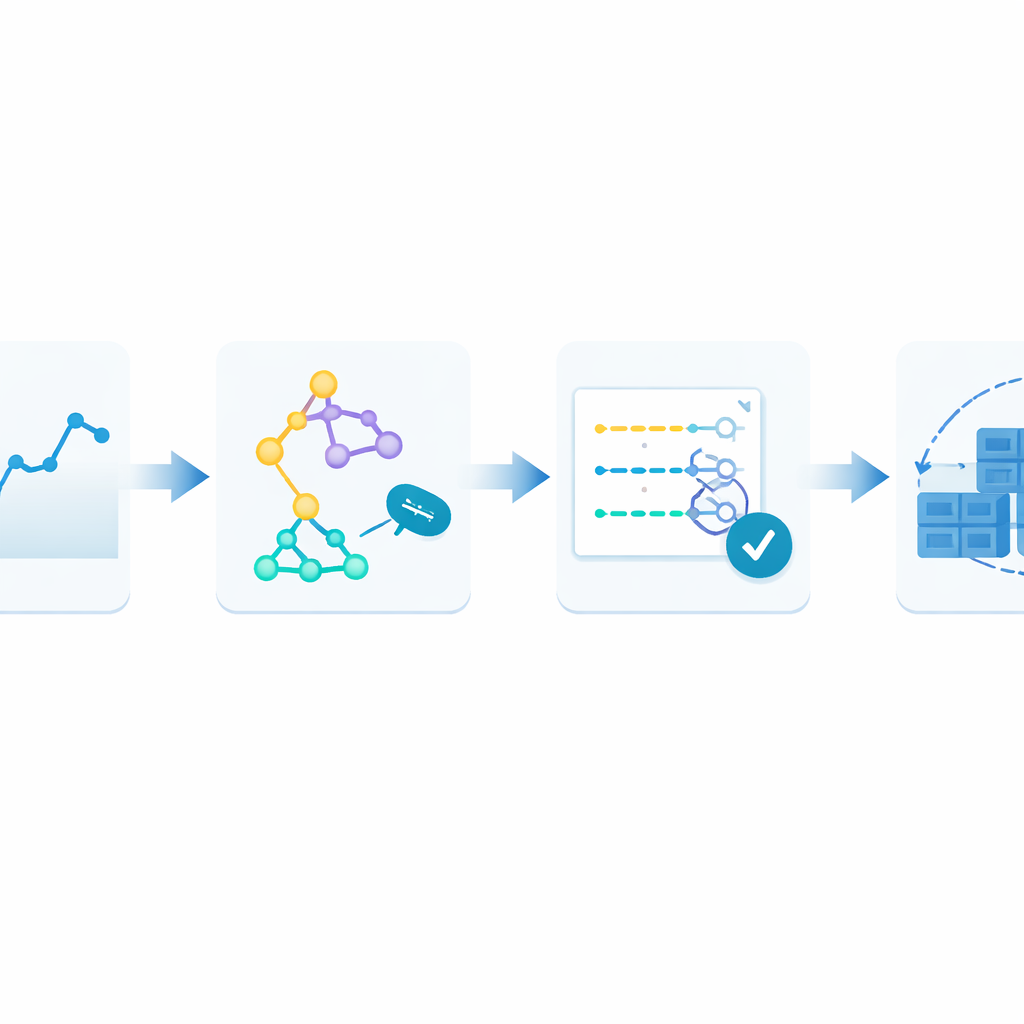
Sätta ramverket på prov
Forskarna utvärderade detta tillvägagångssätt med både syntetiska och verkliga spår av webbaktivitet. De genererade flera idealiserade mönster—släta klockformade kurvor, stadigt stigande belastningar i olika hastigheter och mycket oberäknelig trafik—och använde även registreringar från de officiella VM-webbplatserna 1998 och 2018, där intresset spikar abrupt. För varje fall jämförde de tre eller fyra välkända prognosverktyg, inklusive en statistikbaserad metod, en supportvektormodell, en ensemble av besluts-träd och, i senare experiment, en populär typ av återkommande neuralt nätverk. Nyckelresultatet var att ”vinnaren” skiftade med situationen: enkla statistiska modeller utmärkte sig när efterfrågan var stabil, medan inlärningsbaserade metoder var klart överlägsna när trafiken blev vild och burstig.
Vinster i noggrannhet och effektivitet
Genom att kontinuerligt växla till den modell som för närvarande passade observerat beteende bäst minskade ramverket prognosfelen med upp till cirka 15 procent jämfört med att hålla sig till en fast modell. Lika viktigt är att det gjorde detta utan att köra alla modeller hela tiden. Endast en prediktor är aktiv under livekörning; de andra återtränas och kontrolleras periodvis, vilket håller beräkningsbördan måttlig. Författarna introducerar också en successivt skärpt tröskel för när återträning ska ske, så att systemet blir mindre tolerant mot upprepade fel och minskar risken för långa perioder med dåliga prognoser.
Vad detta betyder för vanliga molnanvändare
I praktiska termer visar studien att molnplattformar kan drivas mer intelligent genom att låta prognosmodeller konkurrera och genom att anpassa valet över tid. För användare kan det översättas till smidigare upplevelser online under stora evenemang och färre inbromsningar när folkmassor dyker upp oväntat. För leverantörer lovar det en mer effektiv användning av datorkapacitet, lägre driftkostnader och mindre slöseri med energi. Istället för att satsa på en enda smart algoritm förespråkar detta arbete en flexibel styrloop som fortsätter att lära, testa och revidera hur den förutser efterfrågan i en allt mer oförutsägbar digital värld.
Citering: Nashaat, M., Moussa, W., Rizk, R. et al. Dynamic machine learning approach for workload prediction in cloud environments. Sci Rep 16, 10983 (2026). https://doi.org/10.1038/s41598-026-40777-z
Nyckelord: prognos för molnarbetsbelastning, autoskalning, containrar, maskininlärning, tidsserier